Self-reflection, the ability of a large language model (LLM) to revisit, evaluate, and revise its own reasoning, has recently emerged as a powerful behavior enabled by reinforcement learning with verifiable rewards (RLVR). While self-reflection correlates with improved reasoning accuracy, its origin and underlying mechanisms remain poorly understood. In this work, we first show that self-reflection is not exclusive to RLVR fine-tuned models: it already emerges, albeit rarely, in pretrained models. To probe this latent ability, we introduce Reflection-Inducing Probing, a method that injects reflection-triggering reasoning traces from fine-tuned models into pretrained models. This intervention raises self-reflection frequency of Qwen2.5 from 0.6% to 38.9%, revealing a hidden capacity for reflection. Moreover, our analysis of internal representations shows that both pretrained and fine-tuned models maintain hidden states that distinctly separate self-reflective from non-reflective contexts. Leveraging this observation, we then construct a self-reflection vector, a direction in activation space associated with self-reflective reasoning. By manipulating this vector, we enable bidirectional control over the self-reflective behavior for both pretrained and fine-tuned models. Experiments across multiple reasoning benchmarks show that enhancing these vectors improves reasoning performance by up to 13.7, while suppressing them reduces computational cost, providing a flexible mechanism to navigate the trade-off between reasoning quality and efficiency without requiring additional training. Our findings further our understanding of self-reflection and support a growing body of work showing that understanding model internals can enable precise behavioral control. Our code is publicly available at https://github.com/xzAscC/ProbingReflection.

LLM-as-a-Judge has become the dominant paradigm for evaluating language model outputs, yet LLM judges exhibit systematic biases that compromise evaluation reliability. We present a comprehensive empirical study comparing nine debiasing strategies across five judge models from four provider families (Google, Anthropic, OpenAI, Meta), three benchmarks (MT-Bench n=400, LLMBar n=200, custom n=375), and four bias types. Our headline practical finding is that a mid-tier model with the right debiasing can outperform frontier judges at a fraction of the cost: Gemini 2.5 Flash with the Combined Budget strategy achieves the highest agreement of any configuration we tested (71.0%, κ = 0.549, p < 0.0001) at ~$0.001 per evaluation, roughly 15× cheaper than the strongest frontier configuration (Claude Sonnet 4 with the same strategy at 69.5%, ~$0.015 per evaluation). Our other key findings: (1) Style bias is the dominant bias (0.10–0.76 baseline across all models, mostly favoring markdown over plain prose), far exceeding position bias (≤ 0.04), yet has received minimal research attention. (2) Verbosity bias is heterogeneous across models when measured length-aware: Llama, Gemini Pro, and Gemini Flash show classical verbosity bias (+0.24 to +0.44, prefer longer), Claude Sonnet 4 shows the opposite (-0.12, prefer concise), and GPT-4o is essentially neutral (-0.04); on truncation controls all models correctly prefer the genuinely complete response (0.88–1.00 accuracy), so the expansion-pair preferences cannot be reduced to length-only effects. (3) Debiasing is statistically beneficial for multiple models: Claude S8 (+11.5 pp, p<0.0001), Flash S8 (+7.5 pp, p<0.0001), Claude S5 (+7.3 pp, p=0.0009) survive Holm-Bonferroni correction; Flash S1 (+4.7 pp, p=0.004) and Llama S8 (+4.5 pp, p=0.011) are significant before correction; Pro and GPT-4o show smaller, non-significant directional gains. We release our evaluation framework, the 375-pair controlled dataset (now including round-robin MODEL_ORIGIN and position-mirrored STYLE pairs), and per-instance cached results for all 9 strategies.

Reinforcement learning policies parametrized by deep neural networks have achieved strong performance for continuous control, yet even small input perturbations may lead to unpredictable behavior. This sensitivity limits their use in safety-critical domains, where robustness guarantees are required. Our work addresses this gap between state-of-the-art adversarial training methods and formal verification to train verifiably robust agents. Previous works train networks with individual adversarial perturbations, making them only robust against the specific adversarial attacks used. In contrast, our approach propagates entire perturbed input sets, enclosing all possible adversarial attacks within a single network pass. We leverage this to explicitly penalize the size of the output set (minimizing closed-loop uncertainty) and thereby make the actor robust against all possible attacks. This is realized by the use of set-based policy gradients, where each output within the set has a different gradient, thereby balancing the accuracy and robustness of the network. Doing so, we achieve formal verifiability across different verification frameworks for up to 9 times larger input perturbations compared to standard reinforcement learning and improve certified worst-case performance.

Post-training quantization (PTQ) is a practical way to reduce the memory footprint of large language models, but low-bit quantization is sensitive to mismatches between the quantization codebook and the empirical weight/activation distributions. We revisit Benford-like leading-digit statistics as a lightweight diagnostic of scale-broad behavior in transformer tensors. Across several model families, we observe a consistent functional dichotomy: transformational nn.Linear weights tend to be Benford-like, whereas LayerNorm and embedding parameters systematically deviate. Motivated by this observation, we propose BenQ, a data-free PTQ codebook that uses a simple log-spaced grid as a proxy for scale-broad distributions and applies it selectively to transformational layers while keeping stability-critical parameters in higher precision. In 4-bit group-wise PTQ, BenQ consistently improves over uniform RTN and is often competitive with NF4, while remaining substantially simpler than optimization-based methods. We additionally report activation quantization results as an exploratory stress test: BenQ can improve robustness over uniform baselines in some families, but performance remains mixed across models, highlighting open challenges for static-grid activation PTQ. Code is available at https://github.com/ufopcsilab/benford-quant.
Existing unlearning approaches typically rely on post hoc weight adaptation or distillation, leading to duplicated memory costs, degraded generalization, and limited scalability. In this work, we introduce ERASE, Erasure via Reconstructive Adversarial Signal Editing, a framework for on-the-go forgetting that suppresses the observable influence of private data without modifying model weights. ERASE leverages structured, class-conditioned input perturbations to induce selective forgetting during inference, eliminating the need for retraining, fine-tuning, or model copies. We rigorously characterize sufficient conditions when ERASE provably achieves functional forgetting of designated subclasses while preserving predictions across other subclasses within the same superclass. This analysis offers a principled foundation for inference-time forgetting under mild regularity assumptions. Across diverse architectures and benchmark datasets, ERASE maintains the best observed balance between forgetting efficacy, computational efficiency, and retention fidelity over recent unlearning-based methods. By reimagining data removal as forgetting without unlearning, our work establishes a scalable, regulation-aligned pathway for continual, privacy-conscious learning.

Flow Matching (FM) has recently emerged as a principled and efficient generative modeling framework for reinforcement learning (RL), enabling expressive, multimodal policy parameterizations via deterministic probability transport. Compared to diffusion-based policies that rely on stochastic denoising chains, FM uses sampling based on ordinary differential equations (ODEs), with learned velocity fields, which can substantially reduce inference latency and simplify the incorporation of RL objectives. As research in flow-based RL rapidly accelerates across offline continuous control, online fine-tuning, and foundation model alignment, the literature has become highly fragmented. In this survey, we provide a comprehensive taxonomy of flow-matching approaches in reinforcement learning. We organize the literature along two axes: the target distribution being modeled (e.g., action policies, value critics, transition dynamics) and the mechanism of RL signal integration (e.g., energy-weighted regression, flow-based policy gradients, and group relative policy optimization). Furthermore, we survey emerging frontiers such as discrete and non-Euclidean action spaces, provide a systematic comparative analysis against Gaussian and diffusion baselines, and outline critical open problems. Ultimately, this survey serves as a foundational roadmap for the next generation of generative reinforcement learning and alignment.
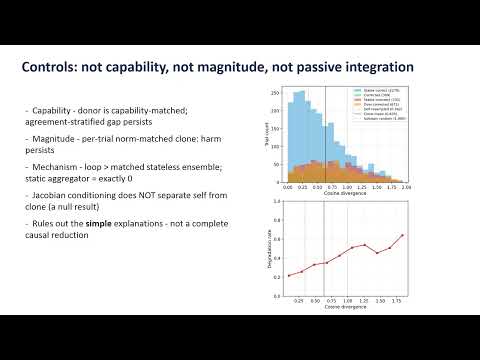
When a recurrent network iteratively refines its predictions, is the performance gain driven primarily by generic temporal integration, or does it depend on the specific geometry of the model's own prior output? To resolve this, we dissect a minimal 35-neuron recurrent network with controlled feedback interventions. Recurrent-specific gain is isolated by two contrasts that do not depend on the convergence-sensitive variable-noise residual: static repeated input, where any deterministic stateless aggregator yields zero gain by construction, and a 120k-parameter MNIST extension where the recurrent loop retains a small but reliable residual. Under variable noise a loop−ensemble residual is additionally present at low-to-moderate noise but is convergence-dependent (reported descriptively), with the no-feedback within-network ensemble matching or nominally exceeding the loop at high noise. Testing feedback-source dependence directly, we replace self-generated feedback with structurally valid output from an independently trained clone. This consistently degrades performance relative to self-feedback at all tested scales. At the minimal scale, clone feedback drops accuracy below the no-feedback baseline — a scale-bounded fake-mirror inversion (robust under static input; marginal under variable noise). This absolute-harm penalty is scale-dependent in both regimes: under variable noise it transitions to a net-positive but still suboptimal signal at the larger tested widths and on MNIST, while under static input it attenuates toward near-neutral at the larger widths; coordinate-shuffled feedback by contrast is harmful at every tested scale. Progressively stronger static aligners recover the clone-feedback loss essentially fully under static input but plateau near ~85% under variable noise, indicating that static open-loop mapping does not fully restore closed-loop compatibility across the aligner capacities we evaluated. A relative condition-number analysis does not separate the evaluated feedback-source conditions. Together, these results characterize feedback-geometry compatibility: an empirical relation between a recurrent receiver and the geometry of its self-generated feedback that is not captured by generic temporal integration alone.

Safety tuning through supervised fine-tuning and reinforcement learning from human feedback has substantially improved the robustness of large language models (LLMs). However, it typically suppresses rather than eliminates unsafe behaviors, leaving rare but critical failures hidden in the long tail of the output distribution. While most red-teaming work emphasizes adversarial prompt search (input-space search), we show that these hidden risks can be systematically exposed through diverse response generation (output-space search). Specifically, we show that, for a fixed safety-critical prompt, increasing the number and diversity of sampled responses monotonically raises the jailbreak success rate. To efficiently uncover these failures, we propose Progressive Diverse Population Sampling (PDPS). This approach replaces naive, large-scale IID sampling with a multi-stage expansion-and-selection strategy that generates a compact, semantically diverse set of responses at a substantially lower computational cost. Across multiple jailbreak benchmarks and open-source LLMs, PDPS achieves attack success rates comparable to large-scale IID sampling while using only 8%-29% of the computational cost, and outperforms IID sampling and Diverse Beam Search by 26%-40% under limited-response budgets, while uncovering a broader and more semantically diverse range of failure modes. Critically, this diversity translates directly into more effective safety hardening: when integrated into an RLHF-based safety-tuning pipeline, PDPS-generated unsafe responses yield 33% and 41% greater reductions in ASR than those generated by IID sampling and Diverse Beam Search, respectively. Finally, we show that while input-space prompt optimization methods fall short of output-space exploration when used in isolation, combining input-space perturbation with diversity-driven output-space exploration covers a wider range of failure modes more efficiently than either paradigm alone.

Pixel-based reinforcement learning agents often exploit spurious visual correlations, leading to brittle policies that fail under minor visual perturbations. We systematically investigate spatial grounded semantic channel representations, often called Feature Maps, Planes, or Object Channels, as a representation design principle for reducing shortcut learning. Object channels map detected entities into binary tensors aligned with the original coordinate frame, preserving compatibility with standard RL backbones without architectural modifications. Specifically, through systematic evaluation in Atari environments under controlled perturbations, we demonstrate that such channel representations substantially improve zero-shot robustness to distribution shifts while maintaining competitive in-distribution performance. We analyze the abstraction–fidelity trade-off and show that combining object channels with raw pixels improves robustness and sample efficiency compared to pure pixel-based approaches. The experimental results indicate that spatially grounded object-based encodings offer a practical mechanism for bridging pixel- and object-centric RL.

We study robust high-dimensional sparse regression under finite-variance heavy-tailed noise, ε-contamination, and α-mixing dependence via two subsampling estimators: Adaptive Importance Sampling (AIS) and Stratified Sub-sampling (SS). Under sub-Gaussian design whose scopeis precisely delimited and finite-variance noise, a subsample of size$m=\Omega(s\log p)$ achieves the minimax-optimal rate $O(\sqrt{s\log p/m})$. We close the theory-algorithm gap: Theorem 4.6 applies to AIS at termination conditional on stabilized weights (Proposition 4.1), and SS fits the median-of-means M-estimation framework of Lecu´e and Lerasle (Proposition 4.3). The de-biasing step is fully specified via the nodewise-Lasso precision estimator under a new sparse-precision assumption, yielding valid coordinate-wise CIs (Theorem 4.14). The α-mixing extension uses a calendar-time block protocol that guarantees temporal separation (Theorem 4.12). Empirically, AIS achieves 3.1× lower error than uniform subsampling at 20% contamination, and 29.5% lower test MSE on Riboflavin (p=4,088 ≫ n=71).

Data acquired from multiple sensors or modalities, commonly referred to as multiview data, is prevalent in real-world applications. A core problem in multiview data analysis is finding representations of common components across views while filtering out view-specific nuisance factors. A widely spread assumption in existing methods is that the views are fully aligned, where each sample has measurements from all views. However, in practice, data is often partially aligned, where some samples have missing measurements from one or more views, and only a subset of the samples are fully aligned. In this work, we propose ADM+, a multiview manifold learning algorithm that computes a low-dimensional embedding of common information from partially aligned data. ADM+ extends Alternating Diffusion Maps (ADM), an existing multiview manifold learning method, to the partial alignment setting by using fully aligned samples as anchor points for extracting common components for unaligned samples. Unlike existing methods, ADM+ does not require prior imputation of missing data or interpolation in the embedding space and makes use of all available data. We provide a computationally efficient implementation, improving upon the $O(N^3)$ time complexity of ADM, and a theoretical analysis showing that ADM+ approximates an anisotropic diffusion process that emphasizes common components. Empirical evaluations across three domains -- dynamical systems, synthetic multiview images, and real-world functional magnetic resonance imaging (fMRI) -- demonstrate that ADM+ achieves favorable performance compared to kernel- and manifold-based baselines. In addition, ADM+ shows robustness to distributional discrepancies between aligned and unaligned samples.
Learning interactive multi-agent behaviors from scratch is often sample-inefficient and fails to exploit reusable skills learned in simpler settings. While latent skill representations enable efficient single-agent reinforcement learning, their extension to multi-agent interaction requires conditioning behaviors on other agents without destroying pretrained structure. We formulate multi-agent interaction as a latent adaptation problem and propose the Latent Motion Adjuster (LMA), a lightweight conditional module that modifies latent actions produced by a pretrained single-agent policy based on other agents’ states. Rather than relearning policies from scratch, our method performs structured residual adaptation in latent space, enabling efficient skill reuse under both cooperative and competitive scenarios. Experiments on physics-based control benchmarks demonstrate that latent-space adaptation improves sample efficiency and interaction performance over fine-tuning and strategic baselines. These results suggest that conditional latent modulation provides a principled mechanism for transferring single-agent skills to multi-agent reinforcement learning.

Many multi-agent reinforcement learning (MARL) algorithms do not scale well as the number of agents increases due to an exponential time and space complexity dependency on the number of agents in the environment. Mean field theory has been used to address this problem by approximating the effect of neighbourhoods of agents by a single representative agent. While this approximation allows MARL algorithms to scale to environments with many agents, approaches typically assumed that agents 1) inside a neighbourhood are homogeneous, and 2) outside a neighbourhood have no influence (and can therefore be ignored). This paper relaxes these assumptions and proposes a novel framework, mean field attention (MFA), which uses an attention mechanism for local responses and the mean field approximation for global responses. We implement MFA with two new algorithms leveraging Q-learning and actor-critic. These novel MFA algorithms consistently outperform other MARL algorithms, including prior mean field-based algorithms, across multiple metrics and benchmarks.
Sequential recommendation tracks users' preferences over time based on users' historical activities and makes prediction on their next most probable action. However, this approach faces limitations when dealing with cold-start users who possess minimal interaction data, leading to difficulty in learning their preferences. To address this challenge, by taking regular users with longer interaction histories and cold-start users as two domains, this paper introduces domain adaptation techniques to narrow the performance gap caused by knowledge shifts in domains. We propose a dual-transformer framework with separate models for long (source) and short (target) sequences, collaboratively trained with shared item embeddings. To enable effective knowledge transfer, we introduce an emulated target domain by sampling short sequences from the source, and apply contrastive learning to align their contextual representations. To further improve adaptation under complex knowledge shifts, we reduce item popularity bias and incorporate user similarity into the contrastive loss. Experiments on five public datasets show consistent improvements over strong baselines, demonstrating the robustness of our approach under both length shifts and compounded shifts involving item distribution changes.
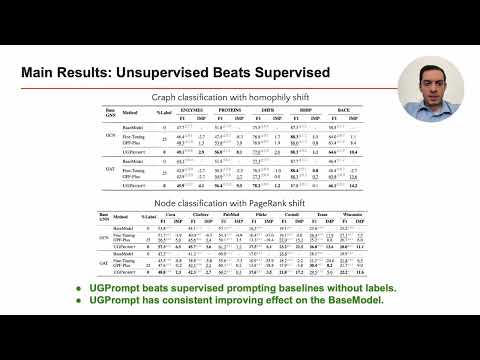
Prompt tuning has become a key mechanism for adapting pre-trained Graph Neural Networks (GNNs) to new downstream tasks. However, existing approaches are predominantly supervised, relying on labeled data to optimize the prompting parameters and typically fine-tuning a task-specific prediction head—practices that undermine the promise of parameter-efficient adaptation. We propose Unsupervised Graph Prompting Problem (UGPP), a challenging new setting where the pre-trained GNN is kept entirely frozen, labels on the target domain are unavailable, the source data is inaccessible, and the target distribution exhibits covariate shift. To address this, we propose UGPrompt, the first fully unsupervised GNN prompting framework. UGPrompt leverages consistency regularization and pseudo-labeling to train a prompting function, complemented with diversity and domain regularization to mitigate class imbalance and distribution mismatch. Our extensive experiments demonstrate that UGPrompt consistently outperforms state-of-the-art supervised prompting methods with access to labeled data, demonstrating the viability of unsupervised prompting as a practical adaptation paradigm for GNNs.
Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images—using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models’ flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
Combinatorial optimization problems are ubiquitous in science and engineering. Still, learning-based approaches to accelerate combinatorial optimization often require solving a large number of difficult instances to collect training data, incurring significant computational cost. Existing learning-based methods require training dedicated models for each problem distribution, for each downstream task, severely limiting their scalability and generalization. We introduce Forge: Foundational Optimization Representations from Graph Embeddings, a framework that pre-trains a vector-quantized graph autoencoder on a large, diverse collection of mixed-integer programming (MIP) instances in an unsupervised manner, without relying on optimization solvers or optimal solutions. Vector quantization produces discrete code assignments that serve as a vocabulary for representing optimization instances. We evaluate Forge in both unsupervised and supervised settings. In the unsupervised setting, Forge embeddings effectively cluster unseen instances across problem domains and sizes. In the supervised setting, we fine-tune Forge embeddings and show that a single pre-trained model helps predicting both the integrality gap for cut-generation and variable hints for search guidance across multiple problem and size distributions. In both tasks, we improve the performance of a commercial optimization solver and outperform state-of-the-art learning-based methods. Finally, we open-source our training code, pre-trained Forge weights, and embeddings for multiple MIP distributions to foster further research in representation learning for optimization problems.

Assessing when language models develop specific capabilities remains challenging, as behavioral evaluations are expensive and internal representations are opaque. We introduce attention-head binding ($EB^*$), a lightweight mechanistic metric that tracks how attention heads bind multi-token technical terms, such as accessibility concepts ("screen reader," "alt text"), into coherent units during training. Using seven models across five architectures, including Pythia (160M, 1B, 2.8B), OLMo-1B, CRFM GPT-2 Small (5 seeds), SmolLM3-3B, and Qwen2.5-1.5B, we evaluate on 41 canonical accessibility terms ($N=205$ prompts) and the 9-term pilot set, reporting five empirical findings. Discriminant validity validates $EB^*$ against token co-occurrence baselines (nonsense $0.26 \to$ real terms $0.74$, all $p<0.001$, $d=1.2$--$2.9$). The relationship between binding and behavior shifts markedly over the course of training. Early in training, the two are tightly coupled ($\rho=+0.57$, $p<0.001$). Later, this pattern reverses into a decoupled regime ($\rho=-0.20$, $p=0.01$). Cross-architecture replication confirms C1-B: OLMo-1B achieves 90% $EB^*$-leads ($p<0.0001$), CRFM 72.7% ($p<<0.001$). This gives rise to a two-factor model. First, a parameter threshold around 1B parameters controls how deeply decoupling occurs. Second, a training-step threshold near 300K steps determines when the temporal ordering between binding and behavior emerges (C1/C4). High-binding/mid-accuracy checkpoints contain unlockable latent knowledge, yielding few-shot gains up to 61 percentage points (a 183% relative improvement), replicated at 18--37 points across six of seven models (CRFM shows weak unlockability at +7.6 pp due to undertraining). Modern models such as SmolLM3 and Qwen show headroom compression where they reach the same absolute ceiling near 0.72, but display smaller nominal gains because their zero-shot baselines are already high (C3). Causal ablation reveals opposite regimes across scales. At 160M, binding heads remain necessary for performance. Removing them impairs accuracy by 16.7 percentage points. At 2.8B, these same heads have become functionally superseded; ablating them improves performance by 33.3 points. Cross-architecture C5 reveals three distinct patterns. First, OLMo and Qwen achieve near-perfect recognition ceiling with negligible ablation effects. Second, SmolLM3 operates in a distributed regime with negative specificity ($-0.043$). Third, CRFM displays striking initialization sensitivity, with four of five random seeds showing coupled behavior and one seed exhibiting suppressor dynamics (C5). Beyond establishing attention binding as a diagnostic for concept emergence, these findings demonstrate a qualitative shift in how mechanistic structures map to behavioral competence across model scales, a phenomenon we term the "binding-behavior decoupling effect". Code: https://github.com/RayoHQ/attention-binding-a11y

The ability to learn manipulation skills by watching videos of humans has the potential to unlock a new source of highly scalable data for robot learning. Here, we tackle prehensile manipulation, in which tasks involve grasping an object before performing various post-grasp motions. Human videos offer strong signals for learning the post-grasp motions, but they are less useful for learning the prerequisite grasping behaviors, especially for robots without human-like hands. A promising way forward is to use a modular policy design, leveraging a dedicated grasp generator to produce stable grasps. However, arbitrary stable grasps are often not task-compatible, hindering the robot's ability to perform the desired downstream motion. To address this challenge, we present Perceive-Simulate-Imitate (PSI), a framework for training a modular manipulation policy using human video motion data processed by paired grasp-trajectory filtering in simulation. This simulation step extends the trajectory data with grasp suitability labels, which allows for supervised learning of task-oriented grasping capabilities. We show through real-world experiments that our framework can be used to learn precise manipulation skills efficiently without any robot data, resulting in significantly more robust performance than using a grasp generator naively.
Low-Rank Adaptation (LoRA) has become a popular technique for parameter-efficient fine-tuning of large language models (LLMs). In many real-world scenarios, multiple adapters are loaded simultaneously to enable LLM customization for personalized user experiences or to support a diverse range of tasks. Although each adapter is lightweight in isolation, their aggregate cost becomes substantial at scale. To address this, we propose LoraQuant, a mixed-precision post-training quantization method tailored to LoRA. Specifically, LoraQuant reparameterizes each adapter by singular value decomposition (SVD) to concentrate the most important information into specific rows and columns. This makes it possible to quantize the important components to higher precision, while quantizing the rest to lower bitwidth. We conduct comprehensive experiments with LLaMA 2-7B, LLaMA 2-13B, and Mistral 7B models on mathematical reasoning, coding, and summarization tasks. Results show that our LoraQuant uses significantly lower bits than other quantization methods, but achieves comparable or even higher performance.
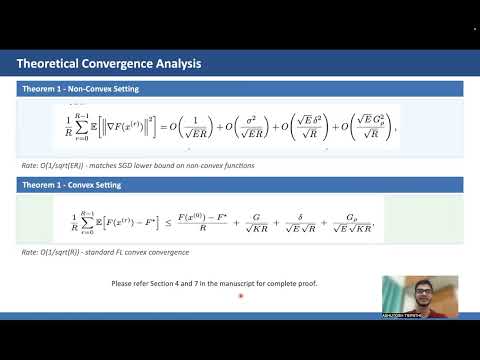
Federated Learning (FL) has emerged as a promising paradigm for collaborative model training without sharing local data. However, a significant challenge in FL arises from the heterogeneous data distributions across participating clients. This heterogeneity leads to highly variable gradient norms in the model's final layers, resulting in poor generalization, slower convergence, and reduced robustness of the global model. To address these issues, we propose a novel technique that incorporates a gradient penalty term into partial variance control. Our method enables diverse representation learning from heterogeneous client data in the initial layers while modifying standard SGD in the final layers. This approach reduces the variance in the classification layers, aligns the gradients, and mitigates the effects of data heterogeneity. Through theoretical analysis, we establish convergence rate bounds for the proposed algorithm, demonstrating its potential for competitive convergence compared to current FL methods in highly heterogeneous data settings. Empirical evaluations on five benchmark datasets validate our approach, showing enhanced performance and faster convergence over state-of-the-art baselines across various levels of data heterogeneity.

Multi-expert systems, where multiple Large Language Models (LLMs) collaborate to solve complex tasks, are increasingly adopted for high-performance reasoning and generation. However, the orchestration policies governing expert interaction and sequencing remain largely opaque. We introduce INFORM, an interpretability analysis that treats orchestration as an explicit, analyzable computation, enabling the decoupling of expert interaction structure, execution order, and functional attribution. We use INFORM to evaluate an orchestrator on GSM8K, HumanEval, and MMLU using a homogeneous consortium of ten instruction-tuned experts drawn from LLaMA-3.1 8B, Qwen3 8B, and DeepSeek-R1 8B, with controlled decoding-temperature variation, and a secondary heterogeneous consortium spanning 1B-7B parameter models. Across tasks, routing dominance is a poor proxy for functional necessity. We reveal a divergence between relational importance, captured by routing mass and interaction topology, and intrinsic importance, measured via gradient sensitivity: frequently selected experts often act as interaction hubs with limited influence, while sparsely routed experts can be structurally critical. Orchestration behaviors emerge asynchronously, with expert centralization preceding stable routing confidence and expert ordering remaining non-deterministic. Targeted ablations show that masking intrinsically important experts induces disproportionate collapse in interaction structure compared to masking frequent peers, confirming that INFORM exposes functional and structural dependencies beyond accuracy metrics alone.
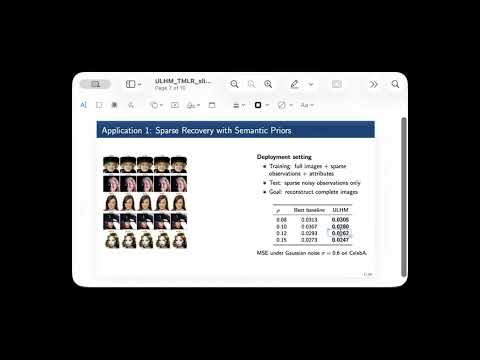
We present the Universal Latent Homeomorphic Manifold (ULHM), a framework that unifies semantic representations (e.g., human descriptions, diagnostic labels) and observation-driven machine representations (e.g., pixel intensities, sensor readings) into a single latent structure. Despite originating from fundamentally different pathways, both modalities capture the same underlying reality. We establish homeomorphism, a continuous bijection preserving topological structure, as the mathematical criterion for determining when latent manifolds induced by different semantic-observation pairs can be rigorously unified. When this homeomorphic criterion is satisfied, it enables three critical applications: (1) semantic-guided sparse recovery from incomplete observations, (2) cross-domain transfer learning with empirically assessed structural compatibility, and (3) transductive zero-shot compositional learning via valid transfer from semantic to observation space. Our framework learns continuous manifold-to-manifold transformations through conditional variational inference, with training objectives explicitly designed to enforce bi-Lipschitz homeomorphic properties. We develop practical verification algorithms, including trust, continuity, and Wasserstein distance metrics, that empirically indicate whether the learned representations exhibit properties consistent with homeomorphic structure from finite samples. Experiments demonstrate substantial improvements over state-of-the-art (SOTA) baselines: (1) sparse recovery from 8% of pixels with much lower MSE than SOTA on CelebA under noise, (2) cross-domain transfer achieving 86.73% MNIST$\rightarrow$Fashion-MNIST accuracy without retraining, and (3) transductive zero-shot classification achieving 78.76% on CIFAR-10, exceeding prior work by 16.66%. Critically, the homeomorphism criterion determines when different semantic-observation pairs share compatible latent structure, enabling principled unification into shared representations within the tested domains and suggesting a structured basis for decomposing broad models into domain-specific components.
Assessing and enhancing human learning through question-answering is vital, yet automating this process remains challenging. We propose Savaal, a scalable question-generation system using large language models (LLMs) with three objectives: (i) scalability, enabling question-generation from hundreds of pages of text (ii) depth of understanding, producing questions beyond factual recall to test conceptual reasoning, and (iii) domain-independent design, supporting various fields without domain-specific training or prompting. Instead of providing an LLM with large documents as context, Savaal improves results with a three-stage processing pipeline. Our evaluation with 76 human experts on 71 papers and PhD dissertations shows that Savaal generates questions that better test depth of understanding by 6.5$\times$ for dissertations and 1.5$\times$ for papers compared to a direct-prompting LLM baseline. Notably, as document length increases, Savaal's advantages in higher question quality and lower cost become more pronounced.

The rise of e-commerce and short-video platforms has fueled demand for realistic video-based virtual try-on. Unlike virtual try-on of clothing, which has been actively studied to date, virtual try-on of eyeglasses is uniquely challenging: they align closely with facial structure and strongly affect facial identity, making the faithful preservation of unedited regions especially important. Existing generative editing approaches, such as GAN- and diffusion-based methods, lack reconstruction objectives and often rely on inpainting, which fails to ensure identity consistency. We argue that semantic editing requires not only plausible generation but also faithful reconstruction, making autoencoder-based latent spaces a natural fit. We introduce a training-free, reference-guided framework for video eyeglass transfer built on Diffusion Autoencoders (DiffAE). By blending semantic features in the encoder and incorporating spatial-temporal self-attention, our method achieves realistic, identity-preserving, and temporally consistent results, and points to the potential of autoencoder-based latent spaces for local video editing. The project page is available at https://moegi161.github.io/freeeyeglass-project/.
Flow matching models generate high-fidelity molecular geometries but incur significant computational costs during inference, requiring hundreds of neural network evaluations. This inference cost becomes the primary bottleneck when such models are employed in practice to sample large numbers of molecular candidates. This work presents a training-free caching strategy that accelerates molecular geometry generation by predicting intermediate hidden states across solver steps. This caching scheme operates directly on the SE(3)-equivariant backbone, is compatible with pretrained models, and is orthogonal to existing training-based accelerations and system-level optimizations. Experiments on molecular geometry generation demonstrate that caching achieves a twofold reduction in wall-clock inference time at matched sample quality and a speedup of up to 3× with minimal sample quality degradation. Because these gains compound with other optimizations, applying caching alongside other general, lossless optimizations yield as much as a 7× speedup.
Joint audio-video generation aims to synthesize realistic audio-video pairs that are both semantically aligned with text prompts and precisely synchronized. While existing joint audio-video generation models often require substantial training resources to improve fidelity, Inference-Time Scaling (ITS) has recently emerged as a promising training-free alternative in single-modality domains. However, extending ITS from a single modality to multimodal domains is non-trivial, as it requires balancing multiple heterogeneous objectives. In this paper, we present the first comprehensive study of ITS for joint audio-video generation. We first demonstrate that a multi-verifier framework is essential to address the limitations of single-objective guidance, including asymmetric performance trade-offs and verifier hacking. Through systematic analysis, we then identify an optimal multi-verifier combination that yields balanced improvements across all quality dimensions. Finally, to effectively aggregate diverse reward signals, we propose Adaptive Reward Weighting (ARW), a novel test-time optimization algorithm. ARW treats reward aggregation as an online optimization problem, utilizing learnable parameters to calibrate reward variances without requiring prior knowledge of reward distributions, thereby ensuring robust multi-objective selection. Experimental results on VGGSound and JavisBench-mini benchmarks demonstrate that our framework significantly enhances semantic alignment, perceptual quality, and audio-visual synchronization of generated outputs.

Algorithmic recourse provides individuals who receive undesirable outcomes from machine learning systems with minimum-cost improvements to achieve a desirable outcome. However, machine learning models often get updated, so the recourse may not lead to the desired outcome. The robust recourse framework chooses recourses that are less sensitive to adversarial model changes, but this comes at a higher cost. To address this, we initiate the study of learning-augmented algorithmic recourse and evaluate the extent to which a designer equipped with a prediction of the future model can reduce the cost of recourse when the prediction is accurate (consistency) while also limiting the cost even when the prediction is inaccurate (robustness). We propose a novel algorithm, study the robustness-consistency trade-off, and analyze how prediction accuracy affects performance.

Mixup involves training neural networks on convex combinations of input samples and labels and has been adapted for privacy-preserving collaborative training, most notably in InstaHide. However, mixing-based obfuscation schemes create structured linear systems that can be exploited to reconstruct the underlying private data. We propose a singularized mixup procedure that injects controlled perturbations prior to forming convex combinations, rendering the resulting inverse problem ill-conditioned while preserving discriminative structure. We provide an average-case theoretical analysis that characterizes the security--utility trade-off via minimax reconstruction bounds and directional signal-to-noise ratio control. Empirically, we evaluate classification accuracy on MNIST, CIFAR-10, CIFAR-100, and Tiny-ImageNet, and compare against InstaHide, observing competitive or improved accuracy under strong privacy settings. We assess robustness against both linear and nonlinear reconstruction attacks, including at-scale linear inversion experiments on CIFAR-5M. In a collaborative training setting with multiple parties and heterogeneous data partitions, we further compare against standard federated learning (FedProx), showing that singularized mixup enables accurate centralized training without iterative gradient exchange and yields improved robustness and performance in heterogeneous regimes. Overall, our results demonstrate that singularized mixup substantially degrades reconstruction quality while maintaining strong predictive performance, providing a practical and scalable approach to privacy-preserving collaborative learning.

A generalist agent must continuously learn and adapt throughout its lifetime, achieving efficient forward transfer while minimizing catastrophic forgetting. Previous work within the dominant pretrain-then-finetune paradigm has explored parameter-efficient fine-tuning for single-task adaptation, effectively steering a frozen pretrained model with a small number of parameters. However, in the context of lifelong learning, these methods rely on the impractical assumption of a test-time task identifier and restrict knowledge sharing among isolated adapters. To address these limitations, we propose Dynamic Mixture of Progressive Parameter-Efficient Expert Library (DMPEL) for lifelong robot learning. DMPEL progressively builds a low-rank expert library and employs a lightweight router to dynamically combine experts into an end-to-end policy, enabling flexible and efficient lifelong forward transfer. Furthermore, by leveraging the modular structure of the fine-tuned parameters, we introduce expert coefficient replay, which guides the router to accurately retrieve frozen experts for previously encountered tasks. This technique mitigates forgetting while being significantly more storage- and computation-efficient than experience replay over the entire policy. Extensive experiments on the lifelong robot learning benchmark LIBERO demonstrate that our framework outperforms state-of-the-art lifelong learning methods in success rates during continual adaptation, while utilizing minimal trainable parameters and storage.

Text-guided sound separation enables flexible audio editing and assistive applications, but existing open-domain systems such as AudioSep remain too compute-intensive for low-latency edge or codec-mediated deployment. Neural audio codec (NAC)-based separators such as CodecFormer and SDCodec are more efficient, but they are largely restricted to fixed-class or fixed-stem separation. We introduce \textbf{CodecSep}, a \emph{text-guided universal sound separation} framework that operates directly in neural audio codec latent space. CodecSep combines a frozen DAC backbone with a lightweight Transformer \emph{masker} conditioned by CLAP-derived FiLM parameters, enabling open-vocabulary source extraction while preserving the efficiency advantages of codec-native representations. To our knowledge, this is the first prompt-driven universal sound separation system built directly on NAC latents. Across \textbf{dnr-v2} and five additional open-domain benchmarks under matched training and prompting protocols, CodecSep consistently improves over AudioSep in separation fidelity (\textbf{SI\mbox{-}SDR}) while remaining competitive in perceptual quality (\textbf{ViSQOL}), and also shows gains in human \textbf{MOS--LQS}. Further analyses show that finer-grained semantic supervision improves separation more consistently than coarse prompting, and that \emph{explicit masking} is more effective than decoder-style latent generation for codec-domain source separation. Qualitative and diagnostic analyses further support the central design premise: modern NAC latents preserve meaningful \emph{source-dependent structure}, and the learned masks exploit this structure primarily through \emph{channel-wise modulation}, indicating that source extraction can be performed through masking alone without explicit latent generation. From a systems perspective, CodecSep also provides a concrete \emph{deployment path} for codec-mediated audio processing. In deployment-typical \emph{code-stream} settings, where the edge device transmits audio as NAC codes generated by the same codec backbone used by the separator, the server can map the received codes to codec embeddings through codebook lookup and perform separation directly in codec space, avoiding a separate decode--separate--re-encode cycle. In this regime, CodecSep requires only \textbf{1.35~GMACs} end-to-end—about $\mathbf{54\times}$ less compute than AudioSep in the same codec-mediated pipeline (and about $\mathbf{25\times}$ lower separator-only compute)—while also reducing latency and memory footprint substantially and remaining fully compatible with \emph{codes in: codes out} operation. More broadly, this codes-in / codes-out formulation provides a concrete blueprint for \emph{codec-native downstream audio processing}, suggesting that tasks such as enhancement, denoising, dereverberation, and prompt-guided audio editing can be designed to operate directly on NAC representations rather than repeatedly decoding to waveform and re-encoding after each processing stage.
Task arithmetic, representing downstream tasks through linear operations on task vectors, has emerged as a simple yet powerful paradigm for transferring knowledge across diverse settings. However, maintaining a large collection of task vectors introduces scalability challenges in both storage and computation. We propose Task Vector Bases, a framework compressing $T$ task vectors into $M < T$ basis vectors while preserving the functionality of task arithmetic. By representing each task vector as a structured linear combination of basis atoms, our approach supports standard operations such as addition, negation, as well as more advanced arithmetic ones. The framework is orthogonal to other efficiency-oriented improvements in task arithmetic and can be used in combination with them. We provide theoretical analysis showing that basis compression retains addition generalization guarantees and enables principled unlearning, with error bounds depending on reconstruction quality. Empirically, our proposed basis construction methods consistently outperform heuristic basis construction baselines and, in some cases, even surpass the performance of full task vector collections across diverse downstream applications while reducing storage and computational requirements.
We present a method to dynamically deform 3D garments, in the form of a 3D polygon mesh, based on body shape, motion, and physical cloth material properties. Considering physical cloth properties allows to learn a physically grounded model, with the advantage of being more accurate in terms of physically inspired metrics such as strain or curvature. Existing work studies pose-dependent garment modeling to generate garment deformations from example data, and possibly data-driven dynamic cloth simulation to generate realistic garments in motion. We propose *D-Garment*, a learning-based approach trained on new data generated with a physics-based simulator. Compared to prior work, our 3D generative model learns garment deformations conditioned by physical material properties, which allows to model loose cloth geometry, especially for large deformations and dynamic wrinkles driven by body motion. Furthermore, the model can be efficiently fitted to observations captured using vision sensors such as 3D point clouds. We leverage the capability of diffusion models to learn flexible and powerful generative priors by modeling the 3D garment in a 2D parameter space independently from the mesh resolution. This representation allows to learn a template-specific latent diffusion model. This allows to condition global and local geometry with body and cloth material information. We quantitatively and qualitatively evaluate *D-Garment* on both simulations and data captured with a multi-view acquisition platform. Compared to recent baselines, our method is more realistic and accurate in terms of shape similarity and physical validity metrics. Code and data are available for research purposes at https://dumoulina.github.io/d-garment/

We study a common domain adaptation setting in causal systems with local causal knowledge: the target variable is observed in the source domain but is entirely missing in the target domain, and the conditional mechanism of the target given its Markov blanket is assumed stable across domains. We aim to impute the target variable in the target domain from the remaining observed variables under various shifts. Our central transfer mechanism is structural: restricting the predictor to the Markov blanket of the target screens off shift-prone non-blanket variation and yields zero-shot transfer under blanket invariance. On top of this restriction, we frame estimation as learning a compact, mechanism-stable representation, and we instantiate it with the Information Bottleneck (IB) as a principled compression and regularization mechanism. For linear Gaussian causal models, we derive a closed-form Gaussian Information Bottleneck (GIB) solution that reduces to a canonical correlation analysis (CCA)–style projection and is provably lossless relative to using all non-target variables; in this well-specified regime, ordinary least squares on the blanket is already near-optimal, so the value of IB is regularization rather than accuracy gains. For nonlinear or non-Gaussian data, where no closed-form conditional estimator is available, we introduce a Variational Information Bottleneck (VIB) encoder–predictor that scales to high dimensions and can be trained on source data and deployed zero-shot to the target domain. Across synthetic and real datasets, our approach consistently attains accurate imputations, supporting practical use in high-dimensional causal models and furnishing a unified, lightweight toolkit for causal domain adaptation.
Some real networks keep a fixed structure (e.g., roads, sensors and their connections) while node or edge signals evolve over time. Existing graph generators either model topology changes (i.e., edge additions/deletions) or focus only on static graph properties (such as degree distributions or motifs), without considering how temporal signals shape the generated structure. By approaching the problem from an unconventional perspective, we introduce TANGEM, that integrate a temporal similarity matrix into biased random walks, thereby coupling signals with structure to generate graphs that highlight patterns reflecting how nodes co-activate over time. We evaluate TANGEM using an approach that separates structural fidelity (clustering, spectral metrics) from downstream temporal consistency, allowing us to clearly isolate the impact of the topology generator itself. In structural benchmarks, TANGEM consistently outperforms strong baselines while remaining lightweight. These results show that adding attribute-guided bias to structural sampling produces more realistic graphs and establishes TANGEM as a basis for future models that further integrate evolving signals and structure.

We examine the consequences of positing that the weight function $\alpha$ in the classical random feature model formulation $f(x) = \E_{w\sim p}\qty[\alpha(w)\phi(w,x)]$ belongs to a reproducing kernel Hilbert space. Depending on the choices of parameters of the random feature model, this assumption grants the ability to exactly calculate the model instead of relying on the random kitchen sinks method of approximation. We present several such examples. Additionally, using this form of the model, the functional gradient of the loss can be approximated in an unbiased way through sampling of the random features. This allows using a stochastic functional gradient descent to learn the weight function. We show that convergence is guaranteed under mild assumptions. Further theoretical analysis shows that the empirical risk minimizer converges with the same $\Ocal\qty(\frac 1 {\sqrt m} + \frac 1 {\sqrt T})$ rate as Rahimi & Recht (2009). We also present two other algorithms for learning the weight function. We run experiments to compare these three learning algorithms, and to compare this random feature model variant to the original random kitchen sinks and other state of the art algorithms.
Euclidean representations distort data with intrinsic non-Euclidean structure. While Riemannian representation learning offers a solution by embedding data onto matching manifolds, it typically relies on an encoder to estimate densities on chosen manifolds. This involves optimizing numerically brittle objectives, potentially harming model training and quality. To completely circumvent this issue, we introduce the Riemannian generative decoder, a unifying approach for finding manifold-valued latents on any Riemannian manifold. Latents are learned with a Riemannian optimizer while jointly training a decoder network. By discarding the encoder, we vastly simplify the manifold constraint compared to current approaches which often only handle few specific manifolds. We validate our approach on three case studies --- a synthetic branching diffusion process, human migrations inferred from mitochondrial DNA, and cells undergoing a cell division cycle --- each showing that learned representations respect the prescribed geometry and capture intrinsic non-Euclidean structure. Our method requires only a decoder, is compatible with existing architectures, and yields interpretable latent spaces aligned with data geometry.

Deep neural networks, despite their high accuracy, often exhibit poor confidence calibration, limiting their reliability in high-stakes applications. Current ad-hoc confidence calibration methods attempt to fix this during training but face a fundamental trade-off: two-phase training methods achieve strong classification performance at the cost of training instability and poorer confidence calibration, while single-loss methods are stable but underperform in classification. This paper addresses and mitigates this stability-performance trade-off. We propose Socrates Loss, a novel, unified loss function that explicitly leverages uncertainty by incorporating an auxiliary unknown class, whose predictions directly influence the loss function and a dynamic uncertainty penalty. This unified objective allows the model to be optimized for both classification and confidence calibration simultaneously, without the instability of complex, scheduled losses. We provide theoretical guarantees that our method regularizes the model to prevent miscalibration and overfitting. Across four benchmark datasets and multiple architectures, our comprehensive experiments demonstrate that Socrates Loss consistently improves training stability while achieving more favorable accuracy-calibration trade-off, often converging faster than existing methods.

Explainability aspects of most classification models are learnt through instance-specific analysis. However, in understanding diseases, it is important to consider population-wide analysis in order to identify affected regions that are consistently seen across cohorts of diseased population. In this study, we report utility of Kolmogorov-Arnold Networks (KANs) in understanding population-wide characteristics seen in subjects affected by Alzheimer's disease (AD). KANs offer enhanced interpretability through learnable activation functions on network edges. Thus, the learned functions reflect the characteristics of the entire span of training data. In a KAN network trained for classification, attributions through the network can be traced to understand how specific inputs influence the output label. In this study, we propose a path-based attribution framework that generates global importance maps by tracing exhaustive information flow through all potential paths. Our method initially scores the functions on the edges of a trained KAN using an appropriate scoring function. Subsequently, these scores are propagated through the network to compute path-attributions. This approach scales linearly with network depth, and is only dependent on model training and does not need further analysis on training data post-hoc. Evaluation on three public AD neuroimaging datasets (OASIS, ADNI, Mendeley, totally comprising 7428 acquisitions), were carried out on 2D brain slices as well as 3D brain volumes. The corresponding KAN test accuracies are $93.24\%$, $81.85\%$, and $91.25\%$ on OASIS, ADNI, and Mendeley datasets, respectively. Alongside, competitive or improved performance via metrics such as Insertion AUC, Deletion AUC and Sufficiency, is also demonstrated. The generated attribution maps identify clinically meaningful regions including the body and genu of corpus callossum, corona radiata, bilateral caudate nuclei, medial prefrontal cortex and temporal lobe structures, aligned with established AD pathology literature. By providing voxel-level global attributions as network-intrinsic properties, our framework addresses a critical gap in AI interpretability and supports exploratory clinical analysis and model auditing of AI-assisted AD diagnosis systems.

Modern deep learning methods typically treat image sequences as large tensors of sequentially stacked frames. However, is this straightforward representation ideal given the current state-of-the-art (SoTA)? In this work, we address this question in the context of generative models and aim to devise a more effective way of modeling image sequence data. Observing the inefficiencies and bottlenecks of current SoTA image sequence generation methods, we showcase that rather than working with large tensors, we can improve the generation process by factorizing it into first generating the coarse sequence at low resolution and then refining the individual frames at high resolution. We train a generative model solely on grid images comprising subsampled frames. Yet, we learn to generate image sequences, using the strong self-attention mechanism of the Diffusion Transformer (DiT) to capture correlations between frames. In effect, our formulation extends a 2D image generator to operate as a 3D image-sequence generator without introducing any architectural modifications. Subsequently, we super-resolve each frame individually to add the sequence-independent high-resolution details. This approach offers several advantages and can overcome key limitations of the SoTA in this domain. Compared to existing image sequence generation models, our method achieves superior synthesis quality and improved coherence across sequences. It also delivers high-fidelity generation of arbitrary-length sequences and increased efficiency in inference time and training data usage. Furthermore, our straightforward formulation enables our method to generalize effectively across diverse data domains, which typically require additional priors and supervision to model in a generative context. Our method consistently delivers superior quality and offers a $>2\times$ speedup in inference rates across various datasets.

Offline safe reinforcement learning (RL) aims to learn policies that maximize reward while satisfying safety constraints from a fixed dataset. Existing methods extend offline RL with primal–dual value learning and behavior-regularized policy optimization, but in safety-critical tasks they struggle: uniform updates across all states ignore the difference between safety-preserving and unsafe states, leading to inaccurate value estimates, infeasible solutions when constraints conflict, and strong sensitivity to dataset quality. We propose SEVPO($\textbf{SE}$lective $\textbf{V}$alue Learning and $\textbf{P}$olicy $\textbf{O}$ptimization), a divide-and-conquer framework that separates updates based on state safety. SEVPO learns conservative cost values to identify safe states, applying reward-constrained optimization with selective regularization there, and switches to cost-minimization outside to compute least-cost escape paths. Extensive experiments show SEVPO achieves high reward and strict safety guarantees, outperforming state-of-the-art offline safe RL across diverse dataset qualities. We further validate SEVPO by training a Unitree Go2 quadruped robot in dynamic environments using only offline data, demonstrating its potential for safety-critical robotics (https://youtu.be/tDpWq2EV_Ig).

We present a distributed approach for constrained Multi-Agent Reinforcement Learning (MARL) that combines state-augmented policy learning with distributed consensus over dual variables. Our method targets systems where agents have separable dynamics but must coordinate to satisfy global resource constraints, a setting in which, as we demonstrate empirically, independent learning fails to produce feasible solutions because agents cannot determine appropriate individual contributions toward collective constraintsatisfaction. The key technical contribution is showing that lightweight neighbor-to-neighbor consensus over Lagrange multipliers suffices for globally coordinated constraint enforcement while preserving the scalability of independent training. Each agent learns a single augmented policy offline, conditioned on both its local state and a dual variable encoding constraint feedback. During execution, agents reach agreement on this dual variable through local communication alone. We prove that under mild connectivity assumptions, the consensus error among agents' multipliers is bounded, and show that this translates to a bounded constraint violation that decreases with graph connectivity and the number of consensus rounds. Unlike centralized training with decentralized execution (CTDE) approaches, whose complexity grows at least quadratically with agent count, our method scales linearly in both training and execution. Experiments on smart grid demand response demonstrate that consensus coordination is \emph{essential for feasibility}: without it, agents satisfy grid capacity constraints only by indefinitely postponing demand, a degenerate non-solution. With consensus, agents converge to a shared dual variable and satisfy both grid constraints and demand fulfillment, scaling to thousands of agents while CTDE baselines are limited to dozens.

Public datasets, crucial for modern machine learning and statistical inference, often contain low-quality or contaminated samples that can harm model performance. This creates a need for principled prefiltering procedures that a data provider can apply to protect the accuracy of a range of potential downstream statistical and learning procedures _simultaneously_. In this work, we formalize and analyze **L**earner-**A**gnostic **R**obust data **P**refiltering (LARP), the problem of designing prefiltering procedures with guarantees on the worst-case loss over a pre-specified set of learners. We establish the feasibility of LARP in two theoretical settings, by providing upper-bound guarantees on the worst-case loss. Our theoretical results indicate that protecting heterogeneous learner sets via LARP comes at the price of some performance loss compared to individual, learner-specific prefiltering; we call this gap the price of LARP. To assess this gap in performance, we empirically measure the price of LARP across image and tabular tasks. We further explore potential benefits of LARP from the perspective of saving on repeated data curation efforts, in a game-theoretic model where the downstream learners can split the cost of the single prefiltering.
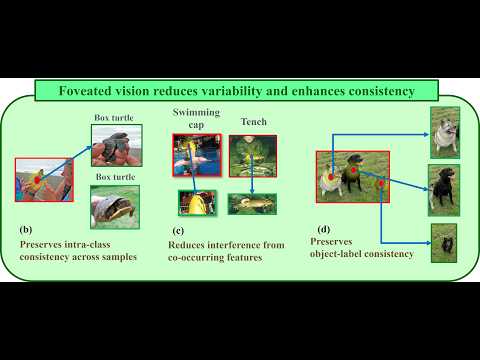
Human active vision integrates spatial attention (dorsal) and object recognition (ventral) as distinct information processing pathways. Rapid eye movements focus perception on task-relevant regions while filtering out background clutter. Mimicking this ventral specialization, we introduce FocL (Foveated Object-Centric Learning), a training strategy that biases image classification models toward label-consistent object regions by replacing full images with foveated crops. Standard training often relies on spurious correlation between label and background, increasing memorization of hard examples in the tail of the difficulty distribution. FocL simulates saccades by jittering fixation points and extracting foveated glimpses from annotated bounding boxes. This object-first restructuring reduces non-foreground contamination and lowers mean training loss. FocL reduces memorization, lowering mean cumulative sample loss by approximately 65 % and making nearly all high-memorization samples (top 1 %) easier to learn. It also increases the mean $\ell_2$ adversarial perturbation distance required to flip predictions by approximately 62 %. On ImageNet-V1, FocL achieves up to 11 % higher accuracy on oracle crops. When paired with the Segment Anything Model (SAM) as a dorsal proposal generator, FocL provides around an 7 % gain on ImageNet-V1 and up to 8 % under natural distribution shift (ImageNet-V2). Extending this setup to COCO, FocL improves cross-domain mAP by 3--4 points without any target-domain training. Finally, given object localization (bounding boxes), FocL reaches higher accuracy using roughly 56\% fewer training images, offering a simple path to more robust and efficient visual recognition.
We study Conformal Prediction (CP) in the practical and challenging regime where labeled training and calibration data observe only a subset of the label space. In this setting, classical Conformal guarantees no longer control marginal risk and naive unseen labels detection methods are either overconservative or uninformative. We introduce CP-POL, a simple operational pipeline that couples Split CP over observed labels with a calibrated novelty test and integrates Prediction-Powered Inference (PPI) for finite sample population estimation. We provide a non-asymptotic theory that (i) proves Le Cam impossibility result: novelty test from features alone is hopeless without structural assumptions, (ii) derives tight finite-sample coverage decompositions that isolate the role of the non-conforming event $s(X)>q$, (iii) gives Dvoretzky-Kiefer-Wolfowitz (DKW)-based conservative estimators and anytime martingale analogues for the novel mass function $\pi_{nov}$, (iv) identifies practically meaningful structural conditions under which strong guarantees for novel region prediction hold, and (v) proves finite-sample PPI bounds that cleanly separate sampling fluctuation, trained model error and novel-mass effects. We validate the theory with reproducible simulations. All bounds are non-asymptotic and designed for immediate use in deployed monitoring pipelines.
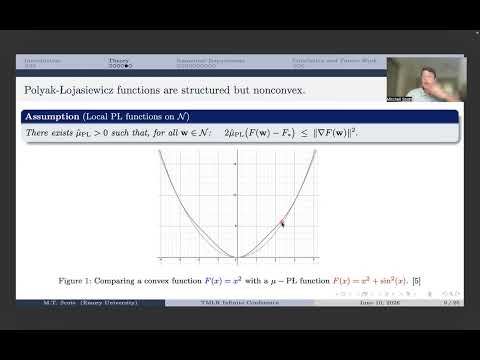
Stochastic Gradient Descent (SGD) often slows in the late stage of training due to anisotropic curvature and gradient noise. We analyze preconditioned SGD in the geometry induced by a symmetric positive definite matrix $\mathbf{M}$. Our bounds make explicit how both the convergence rate and the stochastic noise floor depend on $\mathbf{M}$. For nonconvex objectives, we establish a basin-stability guarantee in a local $\mathbf{M}$-metric neighborhood around a minimizer set: under local smoothness and a local PL condition, we give an explicit lower bound on the probability that the iterates remain in the basin up to a time horizon. This perspective is particularly relevant in Scientific Machine Learning (SciML), where reaching small training losses under stochastic updates is closely tied to physical fidelity, numerical stability, and constraint satisfaction. Our framework covers both diagonal/adaptive and curvature-aware preconditioners and yields a practical criterion: choose $\mathbf{M}$ to improve local conditioning while attenuating noise in the $\mathbf{M}^{-1}$-norm. Experiments on a quadratic diagnostic and three SciML benchmarks support the predicted rate--floor behavior.

We present ContagionRL, a Gymnasium-compatible reinforcement learning platform specifically designed for systematic reward engineering in spatial epidemic simulations. Unlike traditional agent-based models that rely on fixed behavioral rules, our platform enables rigorous evaluation of how reward function design affects learned survival strategies across diverse epidemic scenarios. ContagionRL integrates a spatial SIRS+D epidemiological model with configurable environmental parameters, allowing researchers to stress-test reward functions under varying conditions including limited observability, different movement patterns, and heterogeneous population dynamics. We evaluate five distinct reward designs, ranging from sparse survival bonuses to a novel potential field approach, across multiple RL algorithms (PPO, SAC, A2C). Through systematic ablation studies, we identify that directional guidance and explicit adherence incentives are critical components for robust policy learning. Our comprehensive evaluation across varying infection rates, grid sizes, visibility constraints, and movement patterns reveals that reward function choice dramatically impacts agent behavior and survival outcomes. Agents trained with our potential field reward consistently achieve superior performance, learning maximal adherence to non-pharmaceutical interventions while developing sophisticated spatial avoidance strategies. The platform's modular design enables systematic exploration of reward-behavior relationships, addressing a knowledge gap in models of this type where reward engineering has received limited attention. ContagionRL is an effective platform for studying adaptive behavioral responses in epidemic contexts and highlight the importance of reward design, information structure, and environmental predictability in learning. Our code is publicly available at https://github.com/redradman/ContagionRL
Lip synchronization, known as the task of aligning lip movements in an existing video with new input audio, is typically framed as a simpler variant of audio-driven facial animation. However, as well as suffering from the usual issues in talking head generation (e.g., temporal consistency), lip synchronization presents significant new challenges such as expression leakage from the input video and facial occlusions, which can severely impact real-world applications like automated dubbing, but are largely neglected by existing works. To address these shortcomings, we present KeySync, a two-stage framework that succeeds in mitigating the issue of temporal consistency, while also incorporating solutions for leakage and occlusions using a carefully designed masking strategy. We show that KeySync achieves state-of-the-art results in lip reconstruction and cross-synchronization, improving visual quality and reducing expression leakage according to LipLeak, our novel leakage metric. Furthermore, we demonstrate the effectiveness of our new masking approach in handling occlusions and validate our architectural choices through several ablation studies. Our code and videos are available here: https://antonibigata.github.io/KeySync/.
The rapid adoption, usefulness, and resource-intensive training of Graph Neural Network~(GNN) models have made them an invaluable intellectual property in graph-based machine learning. However, their wide-spread adoption also makes them susceptible to stealing, necessitating robust Ownership Demonstration~(OD) techniques. Watermarking is a promising OD framework for deep neural networks, but existing methods fail to generalize to GNNs due to the non-Euclidean nature of graph data. Existing works on GNN watermarking primarily focus on node and graph classification, overlooking Link Prediction (LP). In this paper, we propose \genie~(watermarking \textbf{G}raph n\textbf{E}ural \textbf{N}etworks for l\textbf{I}nk pr\textbf{E}diction), the first scheme to watermark GNNs for LP. \genie creates a novel backdoor for both node-representation and subgraph-based LP methods, utilizing a unique trigger set and a secret watermark vector. Our OD scheme is equipped with Dynamic Watermark Thresholding~(DWT), ensuring high verification probability while addressing practical issues in existing OD schemes. We extensively evaluate \genie across 4~diverse model architectures~(\ie SEAL, GCN, GraphSAGE and NeoGNN), 7~real-world datasets and 21~watermark removal techniques and demonstrate its robustness to watermark removal and ownership piracy attacks. Finally, we discuss adaptive attacks against \genie and a defense strategy to counter it.

Accurate predictions on tabular data rely on capturing complex, dataset-specific feature interactions. Attention-based methods and graph neural networks, referred to as graph-based tabular deep learning (GTDL), aim to improve predictions by modeling these interactions as a graph. In this work, we analyze how these methods model the feature interactions. Current GTDL approaches primarily focus on optimizing predictive accuracy, often neglecting the accurate modeling of the underlying graph structure. Using synthetic datasets with known ground-truth graph structures, we find that current GTDL methods fail to recover meaningful feature interactions, as their edge recovery is close to random. This suggests that the attention mechanism and message-passing schemes used in GTDL do not effectively capture feature interactions. Furthermore, when we impose the true interaction structure, we find that the predictive accuracy improves. This highlights the need for GTDL methods to prioritize accurate modeling of the graph structure, as it leads to better predictions

Partial differential equations (PDEs) are fundamental to modeling physical systems, yet solving them remains a complex challenge. Traditional numerical solvers rely on expert knowledge to implement and are computationally expensive, while neural-network-based solvers require large training datasets and often lack interpretability. In this work, we frame PDE solving as a code generation task and introduce CodePDE, the first inference framework for generating PDE solvers using large language models (LLMs). With CodePDE, we present a thorough evaluation on critical capacities of LLM for PDE solving: reasoning, debugging, self-refinement, and test-time scaling. CodePDE shows that, with advanced inference-time algorithms and scaling strategies, LLMs can achieve strong performance across a range of representative PDE problems. We also identify novel insights into LLM-driven solver generation, such as trade-offs between solver reliability and sophistication, design principles for LLM-powered PDE solving agents, and failure modes for LLM on hard tasks. These insights offer guidance for building more capable and reliable LLM-based scientific engines.
With the recent drastic advancements in text-to-video diffusion models, controlling their generations has drawn interest. A popular way for control is through bounding boxes or layouts. However, enforcing adherence to these control inputs is still an open problem. In this work, we show that by slightly adjusting user-provided bounding boxes we can improve both the quality of generations and the adherence to the control inputs. This is achieved by simply optimizing the bounding boxes to better align with the internal attention maps of the video diffusion model while carefully balancing the focus on foreground and background. In a sense, we are modifying the bounding boxes to be at places where the model is familiar with. Surprisingly, we find that even with small modifications, the quality of generations can vary significantly. To do so, we propose a smooth mask to make the bounding box position differentiable and an attention-maximization objective that we use to alter the bounding boxes. We conduct thorough experiments, including a user study to validate the effectiveness of our method.
Cross-domain imitation learning (CDIL) accelerates policy learning by transferring expert knowledge across domains, which is valuable in applications where collection of expert data is costly. Existing methods are either supervised, relying on proxy tasks and explicit alignment, or unsupervised, aligning distributions without paired data but often unstable. We introduce the Semi-Supervised CDIL (SS-CDIL) setting and propose the first algorithm for SS-CDIL with theoretical justification. Our method uses only offline data, including a small number of target expert demonstrations and some unlabeled imperfect trajectories. To handle domain discrepancy, we propose a novel cross-domain loss function for learning inter-domain state-action mappings and design an adaptive weight function to balance the source and target knowledge. Experiments on MuJoCo and Robosuite show consistent gains over the baselines, demonstrating that our approach achieves stable and data-efficient policy learning with minimal supervision.
This paper investigates cooperative predictive target tracking using a robotic swarm operating under high prediction bias and communication uncertainty. The robots interact over a randomly time-varying communication network and exhibit heterogeneity in onboard sensors and prediction algorithms. To address these challenges, a Distributed Online learning-based Multi-Estimate (DOME) fusion algorithm is proposed, which performs a collaborative weighted fusion of local and socially shared predictions. The fusion weights are adapted online using feedback from a prediction loss. Theoretical analysis establishes that conditional expectations of the fusion weights converge under reasonable assumptions. Simulation studies demonstrate that DOME outperforms both covariance-based and online learning-based decentralized fusion baselines, achieving $74\%$ and $72.4\%$ lower prediction loss in performance and scalability tests, respectively -- particularly under conditions involving significant model drift and communication unreliability. Further, DOME fusion is implemented in a ROS-Gazebo simulation environment.

We advance probabilistic multiclass prediction on open-ended streams of items. In this setting, a predictor must emit items with probabilities, and adapt to significant non-stationarity, including new item appearances and frequency changes. The predictor is not given the set of items that it is to predict a priori, and moreover the totality of the items can grow unbounded: the space-limited predictor need only track the currently salient items and their probabilities. We develop Sparse Moving Average techniques (SMAs), including adaptations of sparse EMA as well as novel queue-based methods with dynamic per-item histories. For performance evaluation, to handle new items, we develop a bounded version of log-loss. Our findings, on a range of synthetic and real data streams, show that dynamic predictand-specific (per connection) parameters, such as learning rates, enhance both adaptation speed and stability.
Stephen Wolfram proclaimed in his 2003 seminal work ``A New Kind Of Science'' that simple recursive programs in the form of Cellular Automata (CA) are a promising approach to replace currently used mathematical formalizations, e.g. differential equations, to improve the modeling of complex systems. Over two decades later, while Cellular Automata have still been waiting for a substantial breakthrough in scientific applications, recent research showed new and promising approaches which combine Wolfram's ideas with learnable Artificial Neural Networks: So-called Neural Cellular Automata (NCA) are able to learn the complex update rules of CA from data samples, allowing them to model complex, self-organizing generative systems. The aim of this paper is to review the existing work on NCA and provide a unified theory, as well as a reference implementation in the open-source library NCAtorch.

Watermarking has become a practical tool for tracing language model outputs, but it modifies token probabilities at inference time, which were carefully tuned by alignment training. This creates a tension: how do watermark-induced shifts interact with the procedures intended to make models safe and useful? Experiments on several contemporary models and two representative watermarking schemes reveal that watermarking induces a nontrivial, patterned yet model-specific shift in alignment. We see two failure modes: guard attenuation, where models become more helpful but less safe, and guard amplification, where refusals become overly conservative. These effects persist even after controlling for perplexity degradation, pointing to alignment-specific distortions, not just quality loss. We address this with Alignment Resampling (AR), a procedure that samples multiple watermarked outputs and selects the most aligned response according to an external reward model. Using standard results on the expected maximum of Gaussian random variables, we derive a theoretical lower bound showing that alignment gains grow sublogarithmically with sample size. In practice, sampling as few as two to four candidates largely restores unwatermarked alignment performance in truthfulness, safety, and helpfulness, without hurting watermark detection. This is the first empirical study of watermarking-alignment interactions; it shows that a simple inference-time fix can recover alignment.

Tensor-based discrete density estimation requires flexible modeling and proper divergence criteria to enable effective learning; however, traditional approaches using α-divergence face analytical challenges due to the α-power terms in the objective function, which hinder the derivation of closed-form update rules. We present a generalization of the expectation-maximization~(EM) algorithm, called the E2M algorithm. It circumvents this issue by first relaxing the optimization into the minimization of a surrogate objective based on the Kullback–Leibler (KL) divergence, which is tractable via the standard EM algorithm, and subsequently applying a tensor many-body approximation in the M-step to enable simultaneous closed-form updates of all parameters. Our approach offers flexible modeling for not only a variety of low-rank structures, including the CP, Tucker, and Tensor Train formats, but also their mixtures, thus allowing us to leverage the strengths of different low-rank structures. We evaluate the effectiveness of our approach on synthetic and real datasets, highlighting its comparable convergence to gradient-based procedures, robustness to outliers, and favorable density estimation performance compared to prominent existing tensor-based methods.
The intrinsic capability to continuously learn a changing data stream is a desideratum of deep neural networks (DNNs). However, current DNNs suffer from catastrophic forgetting, which interferes with remembering past knowledge. To mitigate this issue, existing Continual Learning (CL) approaches often retain exemplars for replay, regularize learning, or allocate dedicated capacity for new tasks. This paper investigates an unexplored direction for CL called Retrospective Feature Estimation (RFE). RFE learns to reverse feature changes by aligning the features from the current trained DNN backward to the feature space of the old task, where performing predictions is easier. This retrospective process utilizes a chain of small feature mapping networks called retrospector modules. Empirical experiments on several CL benchmarks, including CIFAR10, CIFAR100, and Tiny ImageNet, demonstrate the effectiveness and potential of this novel CL direction compared to existing representative CL methods, motivating further research into retrospective mechanisms as a principled alternative for mitigating catastrophic forgetting in CL. Code is available at: https://github.com/mail-research/retrospective-feature-estimation.
The pervasive use of large language models (LLMs) on sensitive data presents a critical privacy challenge, as traditional encryption renders data unusable for inference. We introduce STEALTH, a 120M secure transformer framework designed to process encrypted text while preserving its semantic utility under an authorized-key threat model (no decryption or side-channel access). The core innovation of STEALTH is the Semantic Isomorphism Enforcement (SIE) loss function, a loss that trains the model to learn a topology-preserving mapping between encrypted text embeddings and their original plaintext latent space. This encourages preservation of semantic relationships and topological structure in the encrypted domain. Using retrieval-based reconstruction from a domain-aligned plaintext corpus, STEALTH achieves near-perfect semantic retrieval (BLEU score of 1.0 under full-corpus coverage in our experiments) and enables accurate privacy-preserving clustering on encrypted embeddings. We evaluate STEALTH across 44 datasets spanning general language understanding, healthcare, finance, legal, e-commerce, programming, content analysis, reading comprehension, and corporate communication domains with 16 encryption schemes (704 experimental conditions), establishing a comprehensive benchmark for privacy-preserving NLP on encrypted text. Performance depends on domain alignment between encrypted inputs and the indexed plaintext corpus. Our results demonstrate that, with well-aligned domain indexes and retrieval support, models can perform effective NLP on encrypted data without direct decryption.
Understanding and forecasting future scene states is critical for autonomous agents to plan and act effectively in complex environments. Object-centric models, with structured latent spaces, have shown promise in modeling object dynamics and interactions in order to predict future scene states, but often struggle to scale beyond simple synthetic datasets and to integrate external guidance, limiting their applicability in robotic environments. To address these limitations, we propose TextOCVP, an object-centric model for video prediction guided by textual descriptions. TextOCVP parses an observed scene into object representations, called slots, and utilizes a text-conditioned transformer predictor to forecast future object states and video frames. Our approach jointly models object dynamics and interactions while incorporating textual guidance, enabling accurate and controllable predictions. TextOCVP’s structured latent space offers a more precise control of the forecasting process, outperforming several video prediction baselines on two datasets. Additionally, we show that structured object-centric representations provide superior robustness to novel scene configurations, as well as improved controllability and interpretability, enabling more precise and understandable predictions.
Recent advances in text-to-image generation have improved the quality of synthesized images, but evaluations mainly focus on aesthetics or alignment with text prompts. Thus, it remains unclear whether these models can accurately represent a wide variety of realistic visual entities. To bridge this gap, we propose KITTEN, a benchmark for Knowledge-InTegrated image generaTion on real-world ENtities. Using KITTEN, we conduct a systematic study of recent text-to-image models, retrieval-augmented models, and unified understanding and generation models, focusing on their ability to generate real-world visual entities such as landmarks and animals. Analyses using carefully designed human evaluations, automatic metrics, and MLLMs as judges show that even advanced text-to-image and unified models fail to generate accurate visual details of entities. While retrieval-augmented models improve entity fidelity by incorporating reference images, they tend to over-rely on them and struggle to create novel configurations of the entities in creative text prompts. The dataset and evaluation code are publicly available at https://kitten-project.github.io.

Despite remarkable progress in recent years, Vision Language Models (VLMs) remain prone to overconfidence and hallucinations on tasks such as Visual Question Answering (VQA) and Visual Reasoning. Bayesian methods can potentially improve reliability by helping models predict selectively, that is, models respond only when they are sufficiently confident. Unfortunately, such approaches can be costly and ineffective for large models, and there exists little evidence to show otherwise for multimodal applications. Here, we show for the first time the effectiveness and competitive edge of variational Bayes for selective prediction in VQA. We build on recent advances in variational methods for deep learning and propose an extension called "Variational VQA". This method improves calibration and yields significant gains for selective prediction on VQA and Visual Reasoning, particularly when the error tolerance is low (≤ 1%). Often, just one posterior sample yields more reliable answers than those given by models trained with AdamW. In addition, we propose a new risk-averse selector that outperforms standard sample averaging by considering the variance of predictions. Overall, we present compelling evidence that variational learning is a viable option to make large VLMs safer and more trustworthy.

Regularization, whether explicit in terms of a penalty in the loss or implicit in the choice of algorithm, is a cornerstone of modern machine learning. Indeed, controlling the complexity of the model class is particularly important when data is scarce, noisy or contaminated, as it translates a statistical belief on the underlying structure of the data. This work investigates the question of how to choose the regularization norm $\lVert \cdot \rVert$ in the context of high-dimensional adversarial training for binary classification. To this end, we first derive an exact asymptotic description of the robust, regularized empirical risk minimizer for various types of adversarial attacks and regularization norms (including non-$\ell_p$ norms). We complement this analysis with a uniform convergence analysis, deriving bounds on the Rademacher Complexity for this class of problems. Leveraging our theoretical results, we quantitatively characterize the relationship between perturbation size and the optimal choice of $\lVert \cdot \rVert$, confirming the intuition that, in the data scarce regime, the type of regularization becomes increasingly important for adversarial training as perturbations grow in size.

Continual learning requires models to integrate new classes or domains over time while preserving previously acquired knowledge. Within this paradigm, foundation models often achieve strong performance, but they still remain subject to the stability–plasticity trade-off, where excessive plasticity leads to forgetting of prior knowledge, and excessive stability constrains the adaptation. This necessitates an effective post-training strategy that introduces minimal yet functional modifications. To address this challenge, we first introduce a new parameter-efficient fine-tuning module ‘Learn and Calibrate’, or LuCA, designed to acquire task-specific knowledge through an adapter-calibrator couple, enabling well-refined feature representations. Then, for each task, we deploy a sparse LuCA module on top of the last classification token [CLS] just before the classifier, which we refer to as ‘Token-level Sparse Calibration and Adaptation’, or TOSCA. By leaving the generalization capabilities of the foundation models intact and adapting exclusively via the last token, our approach achieves a harmonious balance between stability and plasticity while reducing both training and inference complexity. We demonstrate that TOSCA yields state-of-the-art performance while introducing 8 times fewer parameters compared to prior methods.
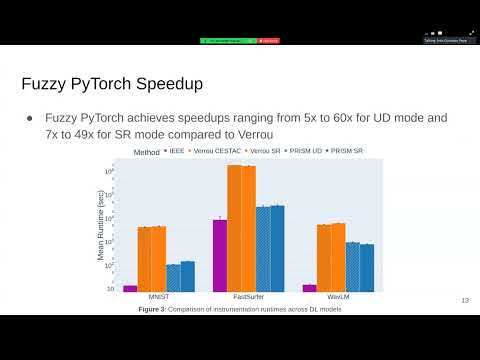
We introduce Fuzzy PyTorch, a framework for rapid evaluation of numerical variability in deep learning (DL) models. As DL is increasingly applied to diverse tasks, understanding variability from floating-point arithmetic is essential to ensure robust and reliable performance. Tools assessing such variability must be scalable, efficient, and integrate seamlessly with existing frameworks while minimizing code modifications. Fuzzy PyTorch enables this by integrating stochastic arithmetic into PyTorch through Probabilistic Rounding with Instruction Set Management, a novel library interfacing with Verificarlo, a numerical analysis compiler. The library offers stochastic rounding mode and a novel mode; up-down rounding. Comparative evaluations show Fuzzy PyTorch maintains model performance and achieves runtime reductions of $5\times$ to $60\times$ versus Verrou, a state-of-the-art tool. We further demonstrate scalability by running models from 1 to 341 million parameters, confirming applicability across small and large DL architectures. Overall, Fuzzy PyTorch provides an efficient, scalable, and practical solution for assessing numerical variability in deep learning, enabling researchers and practitioners to quantify and manage floating-point uncertainty without compromising performance or computational efficiency.
In this paper, we propose a new solution to reward adaptation (RA) in reinforcement learning, where the agent adapts to a target reward function based on one or more existing source behaviors learned a priori under the same domain dynamics but different reward functions. While learning the target behavior from scratch is possible, it is often inefficient given the available source behaviors. Our work introduces a new approach to RA through the manipulation of Q-functions. Assuming the target reward function is a known function of the source reward functions, we compute bounds on the Q-function and present an iterative process (akin to value iteration) to tighten these bounds. The iteration process is based on a lite-model, which is assumed to be given or can be learned. The computed bounds enable action pruning in the target domain before learning even starts. We refer to this method as "$Q-Manipulation$" (Q-M). We formally prove that Q-M, under discrete domains and an accurate lite-model, does not affect the optimality of the returned policy and show that it is provably efficient in terms of sample complexity. Q-M is evaluated in a variety of synthetic and simulation domains to demonstrate its effectiveness, generalizability, and practicality.

In this work, we study the problem of distributed mean estimation with $1$-bit communication constraints when the variance is unknown. We focus on the setting where each user has access to one i.i.d. sample drawn from a distribution belonging to a \emph{location–scale family}, and is limited to sending just a single bit of information to a central server whose goal is to estimate the mean. We propose simple non-adaptive and adaptive protocols and show that both achieve asymptotic normality. We derive bounds on the asymptotic (in the number of users) Mean Squared Error (MSE) achieved by these protocols. For a class of symmetric log-concave distributions, we derive matching lower bounds for the MSE of adaptive protocols, establishing the optimality of our scheme. Furthermore, we develop a lower bound on the MSE for non-adaptive protocols that applies to any symmetric strictly log-concave distribution, using a refined squared Hellinger distance analysis. Through this, we show that for many common distributions, including a subclass of the generalized Gaussian family, the asymptotic minimax MSE achieved by the best non-adaptive protocol is strictly larger than that achieved by our simple adaptive protocol. We also demonstrate that increasing the number of bits per user can only marginally reduce the asymptotic MSE of adaptive protocols. Our simulation results confirm a positive gap between the adaptive and non-adaptive settings, aligning with the theoretical bounds.

Despite their growing capabilities, language models still frequently reproduce content from their training data, generate repetitive text, and favor common grammatical patterns and vocabulary. A possible cause is the decoding strategy: the most common strategies either consider only the most probable tokens, which reduces output diversity, or increase the likelihood of unlikely tokens, compromising output accuracy and correctness. In this paper, we propose DiffSampling, a new decoding method that leverages a mathematical analysis of the token probability distribution to ensure the generation of contextually appropriate text. In particular, the difference between consecutive, sorted probabilities can be used to truncate incorrect tokens. In addition, we also propose two variations of the proposed method that aim to correct the subtle inconsistencies of common sampling strategies. Experiments involving four different text-generation tasks demonstrate that our approach consistently performs at least on par with the existing methods it builds upon in terms of quality, despite sampling from a larger set of tokens.
Recent advances in video diffusion models have unlocked new potential for realistic audio-driven talking video generation. However, maintaining long-term identity consistency, achieving seamless lip-audio synchronization, and producing natural, audio-aligned expressions in generated talking videos remain significant challenges. To address these challenges, we propose Memory-guided EMOtion-aware diffusion (MEMO), an end-to-end audio-driven portrait animation approach to generate identity-consistent and expressive talking videos. Our approach is built around two key modules: (1) a memory-guided temporal module, which enhances long-term identity consistency and motion smoothness by developing causal motion memory to store information from an extended past context to guide temporal modeling; and (2) an emotion-aware audio module, which replaces traditional cross attention with multi-modal attention to enhance audio-video interaction, while detecting emotions from audio to refine facial expressions via emotion-adaptive layer norm. Extensive quantitative and qualitative results demonstrate that MEMO generates more realistic talking videos across diverse image and audio types, outperforming state-of-the-art methods in overall quality, lip-audio synchronization, identity consistency, and expression-audio alignment. Our model and video demos are available at https://memoavatar.github.io.
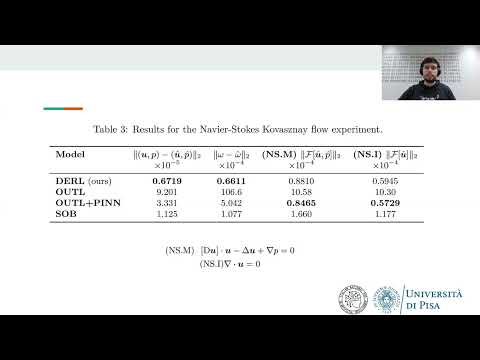
We propose Derivative Learning (DERL), a supervised approach that models physical systems by learning their partial derivatives. We also leverage DERL to build physical models incrementally, by designing a distillation protocol that effectively transfers knowledge from a pre-trained model to a student one. We provide theoretical guarantees that DERL can learn the true physical system, being consistent with the underlying physical laws, even when using empirical derivatives. DERL outperforms state-of-the-art methods in generalizing an ODE to unseen initial conditions and a parametric PDE to unseen parameters. We also design a method based on DERL to transfer physical knowledge across models by extending them to new portions of the physical domain and a new range of PDE parameters. This introduces a new pipeline to build physical models incrementally in multiple stages.
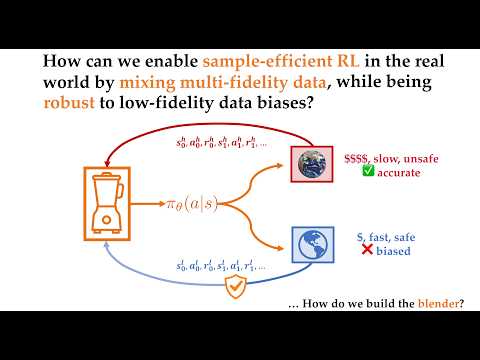
Many reinforcement learning (RL) algorithms are impractical for deployment in operational systems or for training with computationally expensive high-fidelity simulations, as they require large amounts of data. Meanwhile, low-fidelity simulators—such as reduced-order models, heuristic reward functions, or generative world models—can cheaply provide useful data for RL training, even if they are too coarse for direct sim-to-real transfer. We propose multi-fidelity policy gradients (MFPGs), an RL framework that mixes a small amount of data from the target environment with a control variate formed from a large volume of low-fidelity simulation data to construct an unbiased, variance-reduced estimator for on-policy policy gradients. We instantiate the framework by developing a practical, multi-fidelity variant of the classical REINFORCE algorithm. We show that under standard assumptions, the MFPG estimator guarantees asymptotic convergence of multi-fidelity REINFORCE to locally optimal policies in the target environment, and achieves faster finite-sample convergence rates compared to training with high-fidelity data alone. We evaluate the MFPG algorithm across a suite of simulated robotics benchmark tasks in scenarios with limited high-fidelity data but abundant off-dynamics, low-fidelity data. In our baseline comparisons, for scenarios where low-fidelity data are neutral or beneficial and dynamics gaps are mild to moderate, MFPG is, among the evaluated off-dynamics RL and low-fidelity-only approaches,the only method that consistently achieves statistically significant improvements in mean performance over a baseline trained solely on high-fidelity data. When low-fidelity data become harmful, MFPG exhibits the strongest robustness against performance degradation among the evaluated methods, whereas strong off-dynamics RL methods tend to exploit low-fidelity data aggressively and fail substantially more severely. An additional experiment in which the high- and low-fidelity environments are assigned anti-correlated rewards shows that MFPG can remain effective even when the low-fidelity environment exhibits reward misspecification. Thus, MFPG not only offers a reliable and robust paradigm for exploiting low-fidelity data, e.g., to enable efficient sim-to-real transfer, but also provides a principled approach to managing the trade-off between policy performance and data collection costs.

Visual Prompt Tuning (VPT) of pre-trained Vision Transformers (ViTs) has proven highly effective as a parameter-efficient fine-tuning technique for adapting large models to downstream tasks with limited data. Its parameter efficiency makes it particularly suitable for Federated Learning (FL), where both communication and computation budgets are often constrained. However, global prompt tuning struggles to generalize across heterogeneous clients, while personalized tuning overfits to local data and lacks generalization. We propose PEP-FedPT (Prompt Estimation from Prototypes for Federated Prompt Tuning), a unified framework designed to achieve both generalization and personalization in federated prompt tuning of ViTs. Within this framework, we introduce the novel Class-Contextualized Mixed Prompt (CCMP) — based on class-specific prompts maintained alongside a globally shared prompt. For each input, CCMP adaptively combines class-specific prompts using weights derived from global class prototypes and client class priors. This approach enables per-sample prompt personalization without storing client-dependent trainable parameters. The prompts are collaboratively optimized via traditional federated averaging technique on the same. Comprehensive evaluations on CIFAR-100, TinyImageNet, DomainNet, and iNaturalist datasets demonstrate that PEP-FedPT consistently surpasses the state-of-the-art baselines under diverse data heterogeneity scenarios, establishing a strong foundation for efficient and generalizable federated prompt tuning of Vision Transformers.

Computer-aided design (CAD) is the digital construction of 2D and 3D objects, and is central to a wide range of engineering and manufacturing applications like automobile and aviation. Despite its importance, CAD modeling remains largely a time-intensive, manual task. Recent works have attempted to automate this process with small transformer-based models and handcrafted CAD sequence representations. However, there has been little effort to leverage the potential of large language models (LLMs) for sequential CAD design. In this work, we introduce a new large-scale dataset of more than 170k CAD models annotated with high-quality, human-like descriptions generated with our pipeline based on GPT-4.1. Using this dataset, we fine-tune powerful code-LLMs to generate CAD sequences represented in a JSON-based format from natural language descriptions, demonstrating the viability and effectiveness of this approach for text-conditioned CAD generation. Because simple metrics often fail to reflect the quality of generated objects, we introduce geometric and topological metrics based on sphericity, mean curvature, and Euler characteristic to provide richer structural insights. Our experiments and ablation studies on both synthetic and human-annotated data demonstrate that CADmium is able to automate CAD design, drastically speeding up the design of new objects. The dataset, code, and fine-tuned models are available online.

Empirical evidence shows that deep vision networks often represent concepts as directions in latent space with concept information written along directional components in the vector representation of the input. However, the mechanism to encode (write) and decode (read) concept information to and from vector representations is not directly accessible as it constitutes a latent mechanism that naturally emerges from the training process of the network. Recovering this mechanism unlocks significant potential to open the black-box nature of deep networks, enabling understanding, debugging, and improving deep learning models. In this work, we propose an unsupervised method to recover this mechanism. For each concept, we explain that under the hypothesis of linear concept representations, this mechanism can be implemented with the help of two directions: the first facilitating encoding of concept information and the second facilitating decoding. Compared to previous matrix decomposition, autoencoder, and dictionary learning approaches which rely on the reconstruction of feature activations, we propose a different perspective to learn these encoding-decoding direction pairs. We base identifying the decoding directions on directional clustering of feature activations and introduce signal vectors to estimate encoding directions under a probabilistic perspective. Unlike most other works, we also take advantage of the network’s instructions encoded in its weights to guide our direction search. For this, we illustrate that a novel technique called \textit{Uncertainty Region Alignment} can exploit these instructions to reveal the encoding-decoding mechanism of interpretable concepts that influence the network's predictions. Our thorough and multifaceted analysis shows that, in controlled, toy settings with synthetic data, our approach can recover the ground-truth encoding-decoding direction pairs. In real-world settings, our method effectively reveals the encoding-decoding mechanism of interpretable concepts, often scoring substantially better in interpretability metrics than other unsupervised baselines, such as PCA and NMF. Finally, we provide concrete applications of how the learned directions can help open the black box and understand global model behavior, explain individual sample predictions in terms of local, spatially-aware, concept contributions and intervene on the network's prediction strategy to provide either counterfactual explanations or correct erroneous model behavior.

Training convolutional neural networks (CNNs) on high‑resolution images is often bottlenecked by the cost of evaluating gradients of the loss on the finest spatial mesh. To address this, we propose Multiscale Gradient Estimation (MGE), a Multilevel Monte Carlo‑inspired estimator that expresses the expected gradient on the finest mesh as a telescopic sum of gradients computed on progressively coarser meshes. By assigning larger batches to the cheaper coarse levels, MGE achieves the same variance as single‑scale stochastic gradient estimation while reducing the number of fine mesh convolutions by a factor of 4 with each downsampling. We further embed MGE within a Full‑Multiscale training algorithm that solves the learning problem on coarse meshes first and "hot‑starts" the next finer level, cutting the required fine mesh iterations by an additional order of magnitude. Extensive experiments on image denoising, deblurring, inpainting and super‑resolution tasks using UNet, ResNet and ESPCN backbones confirm the practical benefits: Full-Multiscale reduces the computation costs by 4-16$\times$ with no significant loss in performance. Together, MGE and Full‑Multiscale offer a principled, architecture‑agnostic route to accelerate CNN training on high‑resolution data without sacrificing accuracy, and they can be combined with other variance‑reduction or learning‑rate schedules to further enhance scalability.
We introduce $\textsf{gradOL}$, the first gradient-based optimization framework for solving Chebyshev center problems, a fundamental challenge in optimal function learning and geometric optimization. $\textsf{gradOL}$ hinges on reformulating the semi-infinite problem as a finitary max-min optimization, making it amenable to gradient-based techniques. By leveraging automatic differentiation for precise numerical gradient computation, $\textsf{gradOL}$ ensures numerical stability and scalability, making it suitable for large-scale settings. Under strong convexity of the ambient norm, $\textsf{gradOL}$ provably recovers optimal Chebyshev centers while directly computing the associated radius. This addresses a key bottleneck in constructing stable optimal interpolants. Empirically, $\textsf{gradOL}$ achieves significant improvements in accuracy and efficiency on 34 benchmark Chebyshev center problems from a benchmark \textsf{CSIP} library. Moreover, we extend $\textsf{gradOL}$ to general convex semi-infinite programming (CSIP), attaining up to $4000\times$ speedups over the state-of-the-art \textsf{sipampl} solver tested on the indicated \textsf{CSIP} library containing 67 benchmark problems. Furthermore, we provide the first theoretical foundation for applying gradient-based methods to Chebyshev center problems, bridging rigorous analysis with practical algorithms. $\textsf{gradOL}$ thus offers a unified solution framework for Chebyshev centers and broader CSIPs.

We introduce Gaga, a framework that reconstructs and segments open-world 3D scenes by leveraging inconsistent 2D masks predicted by zero-shot class-agnostic segmentation models. Contrasted to prior 3D scene segmentation approaches that rely on video object tracking or contrastive learning methods, Gaga utilizes spatial information and effectively associates object masks across diverse camera poses through a novel 3D-aware memory bank. By eliminating the assumption of continuous view changes in training images, Gaga demonstrates robustness to variations in camera poses, particularly beneficial for sparsely sampled images, ensuring precise mask label consistency. Furthermore, Gaga accommodates 2D segmentation masks from diverse sources and demonstrates robust performance with different open-world zero-shot class-agnostic segmentation models, significantly enhancing its versatility. Extensive qualitative and quantitative evaluations demonstrate that Gaga performs favorably against state-of-the-art methods, emphasizing its potential for real-world applications such as 3D scene understanding and manipulation.

An Achilles heel of Large Language Models (LLMs) is their tendency to hallucinate non-factual statements. A response mixed of factual and non-factual statements poses a challenge for humans to verify and accurately base their decisions on. To combat this problem, we propose Highlighted Chain-of-Thought Prompting (HoT), a technique for prompting LLMs to generate responses with XML tags that ground facts to those provided in the question. That is, given an input question, LLMs would first re-format the question to add XML tags highlighting key facts, and then, generate a response with highlights over the facts referenced from the input. Compared to vanilla chain of thought prompting (CoT), HoT reduces the rate of hallucination and separately improves LLM accuracy of 5 LLMs consistently on over 22 tasks from arithmetic, reading comprehension, to logical reasoning. Consistent with the success of HoT few-shot prompting, training small LLMs (LLaMA-3.2-1B and Qwen2.5-1.5B) via supervised-finetuning on HoT examples improve LLMs accuracy (on 5 out-of-distribution tasks) over the baselines and over finetuning on CoT examples. When asking humans to verify LLM responses, highlights help time-limited participants to more accurately and efficiently recognize when LLMs are correct. Yet, surprisingly, when LLMs are wrong, HoTs tend to fool users into believing that an answer is correct.

Despite rapid progress in large language model (LLM)-based multi-agent systems, current benchmarks fall short in evaluating their scalability, robustness, and coordination capabilities in complex, dynamic, real-world tasks. Existing environments typically focus on small-scale, fully observable, or low-complexity domains, limiting their utility for developing and assessing next-generation multi-agent Agentic AI frameworks. We introduce CREW-Wildfire, an open-source benchmark designed to close this gap. Built atop the human-AI teaming CREW simulation platform, CREW-Wildfire offers procedurally generated wildfire response scenarios featuring large maps, heterogeneous agents, partial observability, stochastic dynamics, and long-horizon planning objectives. The environment supports both low-level control and high-level natural language interactions through modular Perception and Execution modules. We implement and evaluate several state-of-the-art LLM-based multi-agent Agentic AI frameworks, uncovering significant performance gaps that highlight the unsolved challenges in large-scale coordination, communication, spatial reasoning, and long-horizon planning under uncertainty. By providing more realistic complexity, scalable architecture, and behavioral evaluation metrics, CREW-Wildfire establishes a critical foundation for advancing research in scalable multi-agent Agentic intelligence. All code, environments, data, and baselines will be released to support future research in this emerging domain.

The Lipschitz constant is a key measure for certifying the robustness of neural networks to input perturbations. However, computing the exact constant is NP-hard, and standard approaches to estimate the Lipschitz constant involve solving a large matrix semidefinite program (SDP) that scales poorly with network size. Further, there is a potential to efficiently leverage local information on the input region to provide tighter Lipschitz estimates. We address this problem here by proposing a compositional framework that yields tight yet scalable Lipschitz estimates for deep feedforward neural networks. Specifically, we begin by developing a generalized SDP framework for Lipschitz estimation that is highly flexible, accommodating heterogeneous activation function slope bounds for each neuron on each layer, and allowing Lipschitz estimates with respect to arbitrary input-output pairs in the neural network and arbitrary choices of sub-networks of consecutive layers. We then decompose this generalized SDP into a equivalent small sub-problems that can be solved sequentially, yielding the ECLipsE-Gen series of algorithms, with computational complexity that scales linearly with respect to the network depth. We also develop a variant that achieves near-instantaneous computation through closed-form solutions to each sub-problem. All our algorithms are accompanied by theoretical guarantees on feasibility and validity, serving as strict upper bounds on the true Lipschitz constant. Next, we develop a series of algorithms, termed as ECLipsE-Gen-Local, that explicitly incorporate local information on the input region to provide tighter Lipschitz constant estimates. Our experiments demonstrate that our algorithms achieve substantial speedups over a multitude of benchmarks while producing significantly tighter Lipschitz bounds than global approaches. Moreover, we demonstrate that our algorithms provide strict upper bounds for the Lipschitz constant with values approaching the exact Jacobian from autodiff when the input region is small enough. Finally, we demonstrate the practical utility of our approach by showing that our Lipschitz estimates closely align with network robustness. In summary, our approach considerably advances the scalability and efficiency of certifying neural network robustness, while capturing local input–output behavior to deliver provably tighter bounds, making it particularly suitable for safety-critical and adaptive learning tasks.

Sequence modeling tasks across domains such as natural language processing, time-series forecasting, speech recognition, and control require learning complex mappings from input to output sequences. In recurrent networks, nonlinear recurrence is theoretically required to universally approximate such sequence-to-sequence functions; yet in practice, linear recurrent models have often proven surprisingly effective. This raises the question of when nonlinearity is truly required. In this study, we present a framework to systematically dissect the functional role of nonlinearity in recurrent networks -- allowing to identify both when it is computationally necessary, and what mechanisms it enables. We address the question using Almost Linear Recurrent Neural Networks (AL-RNNs), which allow the recurrence nonlinearity to be gradually attenuated and decompose network dynamics into analyzable linear regimes, making the underlying computational mechanisms explicit. We illustrate the framework across a diverse set of synthetic and real-world tasks, including classic sequence modeling benchmarks, an empirical neuroscientific stimulus-selection task, and a multi-task suite. We demonstrate how the AL-RNN's piecewise linear structure enables direct identification of computational primitives such as gating, rule-based integration, and memory-dependent transients, revealing that these operations emerge within predominantly linear dynamical backbones. Across tasks, sparse nonlinearity plays several functional roles: it improves interpretability by reducing and localizing nonlinear computations, promotes shared (rather than highly distributed) representations in multi-task settings, and reduces computational cost by limiting nonlinear operations. Moreover, sparse nonlinearity acts as a useful inductive bias: in low-data regimes, or when tasks require discrete switching between linear regimes, sparsely nonlinear models often match or exceed the performance of fully nonlinear architectures. Our findings provide a principled approach for identifying where nonlinearity is functionally necessary in sequence models, guiding the design of recurrent architectures that balance performance, efficiency, and mechanistic interpretability.

Predicting the accurate and realistic future is an attractive landmark in spatiotemporal sequence prediction. Despite recent progress in spatiotemporal predictive models, explorations in this field are challenging due to difficulties in intricate global coherence and comprehensive history understanding. In this study, we introduce latent diffusion models (LDMs) into spatiotemporal sequence prediction (PredLDM) with a two-stage training paradigm. (i) To compress intricate global coherent spatiotemporal content into latent space, we propose the masked-attention transformer-based variational autoencoder (MT-VAE) by exploiting transformers with masked self-attention layers. (ii) Different from LDMs in generation-related fields where the condition in our problem settings is historical observations instead of texts, the condition-aware LDM (CA-LDM) is provided for comprehensive understanding of historical sequences. Our denoising diffusion process learns the distribution of both conditional generation and condition-aware reconstruction. Results on KittiCaltech, KTH and SEVIR datasets show that our PredLDM provides promising performance and realistic predictions in multiple scenarios including car driving, humans and weather evolutions. (https://github.com/MaoWuToday/PredLDM.git)

Large language models (LLMs) have greatly improved the quality of synthetic text data. We aim to extend these advances to tabular data with Tabby, a simple but powerful post-training modification to the standard Transformer language model architecture, enabling its use for tabular dataset synthesis. Tabby represents differences across columns using Gated Mixture-of-Experts, with column-specific sets of parameters. Empirically, Tabby results in data quality near or equal to that of real data. Pairing Tabby with Plain, our novel tabular training technique, we observe up to a $7\%$ improvement in quality (measured by MLE) over previous methods. Additionally, our approach is more flexible than prior strategies and extends beyond tables, to more general structured data. In a structured JSON setting, Tabby outperforms all other methods by $2$-$3$ points and is the only approach with MLE equal to the upper bound of non-synthetic data.
Text-to-image models are trained using large datasets of image-text pairs collected from the internet. These datasets often include copyrighted and private images. Training models on such datasets enables them to generate images that might violate copyright laws and individual privacy. This phenomenon is termed imitation – generation of images with content that has recognizable similarity to its training images. In this work we estimate the point at which a model was trained on enough instances of a concept to be able to imitate it – the imitation threshold. We posit this question as a new problem and propose an efficient approach that estimates the imitation threshold without incurring the colossal cost of training these models from scratch. We experiment with two domains – human faces and art styles, and evaluate four text-to-image models that were trained on three pretraining datasets. We estimate the imitation threshold of these models to be in the range of 200-700 images, depending on the domain and the model. The imitation threshold provides an empirical basis for copyright violation claims and acts as a guiding principle for text-to-image model developers that aim to comply with copyright and privacy laws.
Sparse-view Cone-Beam Computed Tomography reconstruction from limited X-ray projections remains a challenging problem in medical imaging due to the inherent undersampling of fine-grained anatomical details, which correspond to high-frequency components. Conventional CNN-based methods often struggle to recover these fine structures, as they are typically biased toward learning low-frequency information. To address this challenge, this paper presents DuFal (Dual-Frequency-Aware Learning), a novel framework that integrates frequency-domain and spatial-domain processing via a dual-path architecture. The core innovation lies in our High-Local Factorized Fourier Neural Operator, which comprises two complementary branches: a Global High-Frequency Enhanced Fourier Neural Operator that captures global frequency patterns and a Local High-Frequency Enhanced Fourier Neural Operator that processes spatially partitioned patches to preserve spatial locality that might be lost in global frequency analysis. To improve efficiency, we design a Spectral-Channel Factorization scheme that reduces the Fourier Neural Operator parameter count. We also design a Cross-Attention Frequency Fusion module to integrate spatial and frequency features effectively. The fused features are then decoded through a Feature Decoder to produce projection representations, which are subsequently processed through an Intensity Field Decoding pipeline to reconstruct a final Computed Tomography volume. Experimental results on the LUNA16 and ToothFairy datasets demonstrate that DuFal significantly outperforms existing state-of-the-art methods in preserving high-frequency anatomical features, particularly under extremely sparse-view settings.
The performance of reinforcement learning (RL) in real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in MDPs that slightly deviate. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a second learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our method does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs, while maintaining the data-efficiency of the base algorithm. Our methodology is also compared against various other robust RL approaches. We further examine how pessimism is achieved by exploring the learned deviation between the proposed auxiliary world model and the nominal model. By introducing a pessimistic world model and demonstrating its role in improving policy robustness, our research presents a general methodology for robust RL in a model-based setting.

Ensuring both syntactic and semantic correctness in Large Language Model (LLM) outputs remains a significant challenge, despite being critical for real-world deployment. In this paper, we introduce $\texttt{SEM-CTRL}$, a unified approach that allows for enforcing rich context-sensitive constraints, and task and instance specific semantics directly on the LLM decoder. Our approach integrates token-level MCTS which is guided by specific syntactic and semantic constraints. The constraints over desired outputs are expressed using Answer Set Grammars, which is a logic-based formalism that generalizes context sensitive grammars while incorporating background knowledge to represent task-specific semantics. We show that our approach helps guarantee valid completions for any off-the-shelf LLM without the need for fine-tuning. We evaluate $\texttt{SEM-CTRL}$ on a range of tasks, including synthetic grammar synthesis, combinatorial reasoning, JSON parsing, and planning. Our experimental results demonstrate that $\texttt{SEM-CTRL}$ allows even small pre-trained LLMs to efficiently outperform larger variants and state-of-the-art reasoning models (e.g., $\text{\textit{o4-mini}}$) while simultaneously guaranteeing semantic validity.
Deep reinforcement learning (DRL) methods often face challenges in environments characterized by large state spaces, long action horizons, and sparse rewards, where effective exploration and credit assignment are critical. We introduce Generative Proto-Sequence (GPS), a novel generative DRL approach that produces variable-length discrete action sequences. By generating entire action sequences in a single decision rather than selecting individual actions at each timestep, GPS reduces the temporal decision bottleneck that impedes learning in long-horizon tasks. This sequence-level abstraction provides three key advantages: (1) it facilitates more effective credit assignment by directly connecting state observations with the outcomes of complete behavioral patterns; (2) by committing to coherent multi-step strategies, our approach facilitates better exploration of the state space; and (3) it promotes better generalization by learning macro-behaviors that transfer across similar situations rather than memorizing state-specific responses. Evaluations across diverse maze navigation tasks of varying sizes and complexities demonstrate that GPS outperforms leading action repetition and temporal methods in the large majority of tested configurations, where it converges faster and achieves higher success rates.

The recent emergence of hybrid models has introduced a transformative approach to computer vision, gradually moving beyond conventional convolutional neural networks and vision transformers. However, efficiently combining these two approaches to better capture long-range dependencies in complex images remains a challenge. In this paper, we present iiANET (Inception Inspired Attention Network), an efficient hybrid visual backbone designed to improve the modeling of long-range dependencies in complex visual recognition tasks. The core innovation of iiANET is the iiABlock, a unified building block that integrates a modified global r-MHSA (Multi-Head Self-Attention) and convolutional layers in parallel. This design enables iiABlock to simultaneously capture global context and local details, making it effective for extracting rich and diverse features. By efficiently fusing these complementary representations, iiABlock allows iiANET to achieve strong feature interaction while maintaining computational efficiency. Extensive qualitative and quantitative evaluations on some SOTA benchmarks demonstrate improved performance.
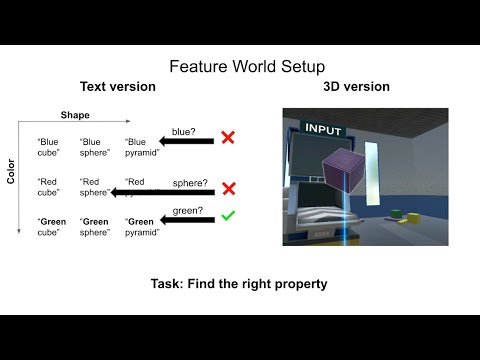
Foundation models excel at single-turn reasoning, but many real-world challenges, from scientific research to technology development, require multi-turn exploration in dynamic interactive environments. Crucial components of learning from experience in these settings, such as efficiently gathering information to test hypotheses, meta-learning a model of the world's dynamics, and adapting to unexpected changes, remain largely unexplored for these models. We first evaluate foundation models in Feature World, a setting that primarily tests information gathering about a static hidden reward function. In this initial setting, we show that state-of-the-art foundation models come close to optimal efficiency in selecting maximally informative actions in tasks with simple reward functions. As a proof of concept, we also show a model can gather information efficiently in a 3D embodied version of this task, though errors in vision limit some aspects of performance. In order to test exploration across multiple dependent turns and trials, we implement a custom, text-based version of the Alchemy environment, a benchmark designed for meta-learning. Here, agents must deduce a latent causal structure by integrating information across multiple state-dependent trials. In this more complex setting, we find that recent foundation models struggle to meta-learn strategies that enable improved performance over time. However, prompting the models to summarize their observations at regular intervals enables an emergent meta-learning process, allowing them to improve across trials. Notably, in some models, summarization also enabled adaptive re-learning of this information when the environment's rules change unexpectedly. While most models performed reasonably well on simple Feature World tasks, evaluations in Alchemy reveal stark differences in robustness among the models, with Gemini 2.5 performing best, followed by Claude 3.7, and ChatGPT-4o and o4-mini struggling the most. These results underscore Alchemy's value as a benchmark for meta-learning and strategy adaptation in foundation models. By moving beyond simple discovery to complex, stateful environments, we demonstrate that the most significant challenge for foundation agents is not selecting informative actions in the moment, but rather seeking and integrating knowledge through adaptive strategies over time. Intriguingly, we find there is likely no intrinsic barrier to future generations of foundation agents more fully mastering these abilities.
In this paper, we introduce a new problem, Online-MMSI, where the model must perform multimodal social interaction understanding (MMSI) using only historical information. Given a recorded video and a multi-party dialogue, the AI assistant is required to immediately identify the speaker’s referent, which is critical for real-world human-AI interaction. Without access to future conversational context, both humans and models experience substantial performance degradation when moving from offline to online settings. To tackle the challenges, we propose Online-MMSI-VLM, a novel framework based on multimodal large language models. The core innovations of our approach lie in two components: (1) multi-party conversation forecasting, which predicts upcoming speaker turns and utterances in a coarse-to-fine manner; and (2) socially-aware visual prompting, which highlights salient social cues in each video frame using bounding boxes and body keypoints. Our model achieves state-of-the-art results on three tasks across two datasets, significantly outperforming the baseline and demonstrating the effectiveness of Online-MMSI-VLM.

We study a model-free federated linear quadratic regulator (LQR) problem where M agents with unknown, distinct yet similar dynamics collaboratively learn an optimal policy to minimize an average quadratic cost while keeping their data private. To exploit the similarity of the agents' dynamics, we propose to use federated learning (FL) to allow the agents to periodically communicate with a central server to train policies by leveraging a larger dataset from all the agents. With this setup, we seek to understand the following questions: (i) Is the learned common policy stabilizing for all agents? (ii) How close is the learned common policy to each agent's own optimal policy? (iii) Can each agent learn its own optimal policy faster by leveraging data from all agents? To answer these questions, we propose the federated and model-free algorithm FedLQR. Our analysis overcomes numerous technical challenges, such as heterogeneity in the agents’ dynamics, multiple local updates, and stability concerns. We show that FedLQR produces a common policy that, at each iteration, is stabilizing for all agents. Moreover, we prove that when learning each agent's optimal policy, FedLQR achieves a sample complexity reduction proportional to the number of agents M in a low-heterogeneity regime, compared to the single-agent setting.

Diffusion models now generate high-quality, diverse samples, with an increasing focus on more powerful models. Although ensembling is a well-known way to improve supervised models, its application to unconditional score-based diffusion models remains largely un- explored. In this work we investigate whether it provides tangible benefits for generative modelling. We find that while ensembling the scores generally improves the score-matching loss and model likelihood, it fails to consistently enhance perceptual quality metrics such as FID on image datasets. We confirm this observation across a breadth of aggregation rules using Deep Ensembles, Monte Carlo Dropout, on CIFAR-10 and FFHQ. We attempt to ex- plain this discrepancy by investigating possible explanations, such as the link between score estimation and image quality. We also look into tabular data through random forests, and find that one aggregation strategy outperforms the others. Finally, we provide theoretical insights into the summing of score models, which shed light not only on ensembling but also on several model composition techniques (e.g. guidance). Our Python code is available at https://github.com/rarazafin/score_diffusion_ensemble.

Memory is a critical component in replay-based continual learning (CL). Prior research has largely treated CL memory as a monolithic store of past data, focusing on how to select and store representative past examples. However, this perspective overlooks the higher-level memory architecture that governs the interaction between old and new data. In this work, we identify and characterize a dual-memory system that is inherently present in both online and offline CL settings. This system comprises: a short-term memory, which temporarily buffers recent data for immediate model updates, and a long-term memory, which maintains a carefully curated subset of past experiences for future replay and consolidation. We propose \textit{memory capacity ratio} (MCR), the ratio between short-term memory and long-term memory capacities, to characterize online and offline CL. Based on this framework, we systematically investigate how MCR influences generalization, stability, and plasticity. Across diverse CL settings—class-incremental, task-incremental, and domain-incremental—and multiple data modalities (e.g., image and text classification), we observe that a smaller MCR, characteristic of \textit{online CL}, can yield comparable or even superior performance relative to a larger one, characteristic of \textit{offline CL}, when both are evaluated under equivalent computational and data storage budgets. This advantage holds consistently across several state-of-the-art replay strategies, such as ER, DER, and SCR. Theoretical analysis further reveals that a reduced MCR yields a better trade-off between stability and plasticity by lowering a bound on generalization error when learning from non-stationary data streams with limited memory. These findings offer new insights into the role of memory allocation in continual learning and underscore the underexplored potential of online CL approaches.

Transformer-based language models are effective but complex, and understanding their inner workings and reasoning mechanisms remains a significant challenge. Previous research has primarily explored how these models handle simple tasks such as name copying or selection; we extend this line of work by investigating how they perform recursive language structure reasoning defined by context-free grammars (CFGs). We introduce a family of synthetic CFGs that produce hierarchical rules, capable of generating long (e.g., hundreds of tokens), locally ambiguous sentences that require dynamic programming to parse. Despite this complexity, we demonstrate that autoregressive language models such as GPT can accurately learn and reason over these CFG-defined hierarchical languages and generate valid continuations. Analyzing model internals in this controlled setting, we reveal that hidden states linearly encode CFG parse structure, and that attention patterns align closely with the information flow of dynamic-programming parsing algorithms. This paper also presents several corollary findings, including: why absolute positional embeddings are inferior to relative and rotary embeddings; why uniform attention alone is surprisingly effective (motivating our follow-up work on Canon layers); why encoder-only models (e.g., BERT, DeBERTa) struggle with *deep* structural reasoning on CFGs compared to autoregressive models (e.g., GPT); and why injecting structural or syntactic noise into pretraining data markedly improves robustness to corrupted language prompts.

Since its introduction, softmax attention has become the backbone of modern transformer architectures due to its expressiveness and scalability across a wide range of tasks. However, the main drawback of softmax attention is the quadratic memory requirement and computational complexity with respect to the sequence length. By replacing the softmax nonlinearity, linear attention and similar methods have been introduced to avoid the quadratic bottleneck of softmax attention. Despite these linear forms of attention being derived from the original softmax formulation, they typically lag in terms of downstream accuracy. While strong intuition of the softmax nonlinearity on the query and key inner product suggests that it has desirable properties compared to other nonlinearities, the question of why this discrepancy exists still remains unanswered. This work demonstrates that linear attention is a first-order approximation of the softmax numerator by deriving its full recurrent form. We further show empirically that the denominator's function can be effectively replaced by a simple vector norm. Using this form, each part of softmax attention can be described in the language of recurrent neural networks (RNNs). Describing softmax attention as an RNN allows for the ablation of the components of softmax attention to understand the importance of each part and how they interact. In this way, our work helps explain why softmax attention is more expressive than its counterparts. Code found at: https://github.com/gmongaras/On-the-Expressiveness-of-Softmax-Attention-A-Recurrent-Neural-Network-Perspective

Classifying an electroencephalography (EEG) recording as pathological or non-pathological is an important first step in diagnosing and managing neurological diseases and disorders. As manual EEG classification is costly, time-consuming and requires highly trained experts, deep learning methods for automated classification of general EEG pathology offer a promising option to assist clinicians in screening EEGs. Convolutional neural networks (CNNs) are well-suited for classifying pathological EEG signals due to their ability to perform end-to-end learning. In practice, however, current CNN solutions suffer from limited classification performance due to I) a single-scale network design that cannot fully capture the high intra- and inter-subject variability of the EEG signal, the diversity of the data, and the heterogeneity of pathological EEG patterns and II) the small size and limited diversity of the dataset commonly used to train and evaluate the networks. These challenges result in a low sensitivity score and a performance drop on more diverse patient populations, further hindering their reliability for real-world applications. Here, we propose a novel multi-branch, multi-scale CNN called Multi-BK-Net (Multi-Branch Multi-Kernel Network), comprising five parallel branches that incorporate temporal convolution, spatial convolution, and pooling layers, with temporal kernel sizes defined by five clinically relevant frequency bands in its first block. Evaluation is based on two public datasets with predefined test sets: the Temple University Hospital (TUH) Abnormal EEG Corpus and the TUH Abnormal Expansion Balanced EEG Corpus. Our Multi-BK-Net outperforms five baseline architectures and state-of-the-art end-to-end approaches in terms of accuracy and sensitivity on these datasets, setting a new benchmark. Furthermore, ablation experiments highlight the importance of the multi-branch, multi-scale input block of the Multi-BK-Net. Overall, our findings indicate the efficacy of multi-branch, multi-scale CNNs in accurately and reliably classifying EEG pathology, demonstrating advantages in handling data heterogeneity compared to other deep learning approaches. Thus, this study contributes to the ongoing development of deep end-to-end methods for general EEG pathology classification.

Federated Learning (FL) marks a transformative approach to distributed model training by combining locally optimized models from various clients into a unified global model. While FL preserves data privacy by eliminating centralized storage, it encounters significant challenges such as performance degradation, slower convergence, and reduced robustness of the global model due to the heterogeneity in client data distributions. Among the various forms of data heterogeneity, label skew emerges as a particularly formidable and prevalent issue, especially in domains such as image classification. To address these challenges, we begin with comprehensive experiments to pinpoint the underlying issues in the FL training process, such as gradient instability and the emergence of sharp minima in the global model, both of which contribute to performance inconsistencies. Based on our findings, we introduce an innovative dual-strategy approach designed to effectively resolve these issues. First, we introduce an adaptive loss function for client-side training, meticulously crafted to preserve previously acquired knowledge while maintaining an optimal equilibrium between local optimization and global model coherence. Secondly, we develop a dynamic aggregation strategy for aggregating client models at the server. This approach adapts to each client's unique learning patterns, effectively addressing the challenges of diverse data across the network. Our comprehensive evaluation, conducted across three diverse real-world datasets, coupled with theoretical convergence guarantees, demonstrates the superior efficacy of our method compared to several established state-of-the-art approaches.

Scene graphs have proven to be highly effective for various scene understanding tasks due to their compact and explicit representation of relational information. However, current methods often overlook the critical importance of preserving symmetry when generating scene graphs from 3D point clouds, which can lead to reduced accuracy and robustness, particularly when dealing with noisy, multi-view data. Furthermore, a major limitation of prior approaches is the lack of temporal modeling to capture time-dependent relationships among dynamically evolving entities in a scene. To address these challenges, we propose Temporal Equivariant Scene Graph Neural Network (TESGNN), consisting of two key components: (1) an Equivariant Scene Graph Neural Network (ESGNN), which extracts information from 3D point clouds to generate scene graph while preserving crucial symmetry properties, and (2) a Temporal Graph Matching Network, which fuses scene graphs generated by ESGNN across multiple time sequences into a unified global representation using an approximate graph-matching algorithm. Our combined architecture TESGNN shown to be effective compared to existing methods in scene graph generation, achieving higher accuracy and faster training convergence. Moreover, we show that leveraging the symmetry-preserving property produces a more stable and accurate global scene representation compared to existing approaches. Finally, it is computationally efficient and easily implementable using existing frameworks, making it well-suited for real-time applications in robotics and computer vision. This approach paves the way for more robust and scalable solutions to complex multi-view scene understanding challenges.
We present and evaluate Vejde; a framework which combines data abstraction, graph learning and reinforcement learning to produce inductive policy functions for decision problems with richly structured states, such as object classes and relations. Markov decision process states are represented as data bases of facts about entities, and Vejde converts each state to a bipartite graph, which is mapped to latent states through neural message passing. The factored representation of both states and actions allows Vejde agents to handle problems of varying size and structure. We tested Vejde agents on eight problem domains defined in RDDL, with ten problem instances each, where policies were trained using both supervised and reinforcement learning. To test policy generalization, we separate problem instances in two sets, one for training and the other solely for testing. Test results on unseen instances for the Vejde agents were compared to MLP agents trained on each problem instance, as well as the online planning algorithm Prost. Our results show that Vejde policies in average generalize to the test instances without a significant loss in score. Additionally, the inductive agents received scores on unseen test instances that on average were close to the instance-specific MLP agents.

Training reinforcement learning agents with human feedback is crucial when task objectives are difficult to specify through dense reward functions. While prior methods rely on offline trajectory comparisons to elicit human preferences, such data is unavailable in online learning scenarios where agents must adapt on the fly. Recent approaches address this by collecting real-time scalar feedback to guide agent behavior and train reward models for continued learning after human feedback becomes unavailable. However, scalar feedback is often noisy and inconsistent, limiting the accuracy and generalization of learned rewards. We propose Pref-GUIDE, a framework that transforms real-time scalar feedback into preference-based data to improve reward model learning for continual policy training. Pref-GUIDE Individual mitigates temporal inconsistency by comparing agent behaviors within short windows and filtering ambiguous feedback. Pref-GUIDE Voting further enhances robustness by aggregating reward models across a population of users to form consensus preferences. Across three challenging environments, Pref-GUIDE significantly outperforms scalar-feedback baselines, with the voting variant exceeding even expert-designed dense rewards. By reframing scalar feedback as structured preferences with population feedback, Pref-GUIDE, offers a scalable and principled approach for harnessing human input in online reinforcement learning.
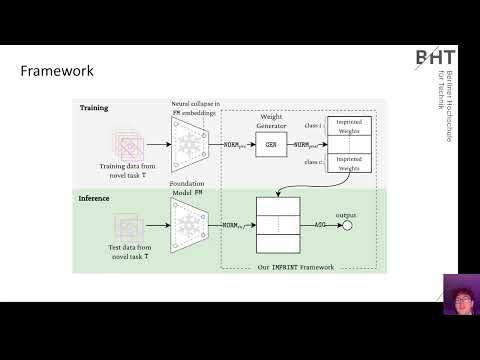
The capacity of foundation models allows for their application to new, unseen tasks. The adaptation to such tasks is called transfer learning. An efficient transfer learning method that circumvents parameter optimization is imprinting. The conceptual differences between studies on imprinting form the basis for our systematic investigation. In this work, we propose the general $\texttt{IMPRINT}$ framework, identifying three main components: generation, normalization, and aggregation. Through the lens of this framework, we conduct an in-depth analysis and a comparison of the existing methods. Our findings reveal the benefits of representing novel data with multiple proxies in the generation step and show the importance of proper normalization. Beyond an extensive analytical grounding, our framework enables us to propose a novel variant of imprinting which outperforms previous work on transfer learning tasks by $4\%$. This variant determines proxies through clustering motivated by the neural collapse phenomenon -- a connection that we draw for the first time. We publicly release our code at \url{https://github.com/DATEXIS/IMPRINT}.

Flow matching has emerged as a powerful generative modeling approach with flexible choices of source distribution. While Gaussian distributions are commonly used, the potential for better alternatives in high-dimensional data generation remains largely unexplored. In this paper, we propose a novel 2D simulation that captures high-dimensional geometric properties in an interpretable 2D setting, enabling us to analyze the learning dynamics of flow matching during training. Based on this analysis, we derive several key insights about flow matching behavior: (1) density approximation can paradoxically degrade performance due to mode discrepancy, (2) directional alignment suffers from path entanglement when overly concentrated, (3) Gaussian's omnidirectional coverage ensures robust learning, and (4) norm misalignment incurs substantial learning costs. Building on these insights, we propose a practical framework that combines norm-aligned training with directionally-pruned sampling. This approach maintains the robust omnidirectional supervision essential for stable flow learning, while eliminating initializations in data-sparse regions during inference. Importantly, our pruning strategy can be applied to any flow matching model trained with a Gaussian source, providing immediate performance gains without the need for retraining. Empirical evaluations demonstrate consistent improvements in both generation quality and sampling efficiency. Our findings provide practical insights and guidelines for source distribution design and introduce a readily applicable technique for improving existing flow matching models. Our code is available at https://github.com/kwanseokk/SourceFM.
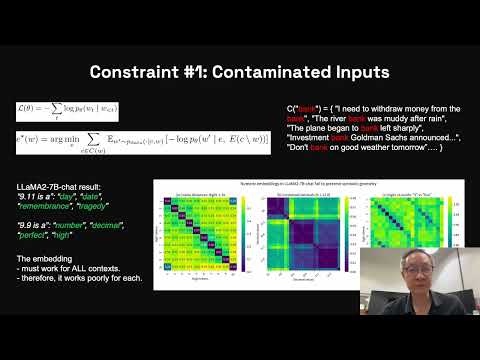
Large Language Models (LLMs) display striking surface fluency yet systematically fail at tasks requiring symbolic reasoning, arithmetic accuracy, and logical consistency. This paper offers a structural diagnosis of such failures, revealing a persistent gap between \textit{comprehension} and \textit{competence}. Through controlled experiments and architectural analysis, we demonstrate that LLMs often articulate correct principles without reliably applying them—a failure rooted not in knowledge access, but in computational execution. We term this phenomenon the computational \textit{split-brain syndrome}, where instruction and action pathways are geometrically and functionally dissociated. This core limitation recurs across domains, from mathematical operations to relational inferences, and explains why model behavior remains brittle even under idealized prompting. We argue that LLMs function as powerful pattern completion engines, but lack the architectural scaffolding for principled, compositional reasoning. Our findings delineate the boundary of current LLM capabilities and motivate future models with metacognitive control, principle lifting, and structurally grounded execution. This diagnosis also clarifies why mechanistic interpretability findings may reflect training-specific pattern coordination rather than universal computational principles, and why the geometric separation between instruction and execution pathways suggests limitations in neural introspection and mechanistic analysis.

A common strategy to enhance the predictive performance of graph neural networks (GNNs) for graph classification is to extend input graphs with node- and graph-level features. However, identifying the optimal feature set for a specific learning task remains a significant challenge, often requiring domain-specific expertise. To address this, we propose a general two-step method that automatically selects a compact, informative subset from a large pool of candidate features to improve classification accuracy. In the first step, a GNN is trained to estimate the importance of each feature for a given graph. In the second step, the model generates feature rankings for the training graphs, which are then aggregated into a global ranking. A top-ranked subset is selected from this global ranking and used to train a downstream graph classification GNN. Experiments on real-world and synthetic datasets show that our method outperforms various baselines, including models using all candidate features, and achieves state-of-the-art results on several benchmarks.

Graph Neural Networks (GNNs) have demonstrated impressive performance across various tasks, leading to their increased adoption in high-stakes decision-making systems. However, concerns have arisen about GNNs potentially generating unfair decisions for underprivileged groups or individuals when lacking fairness constraints. This work addresses this issue by introducing GraphGini, a novel approach that incorporates the Gini coefficient to enhance both individual and group fairness within the GNN framework. We rigorously establish that the Gini coefficient offers greater robustness and promotes equal opportunity among GNN outcomes, advantages not afforded by the prevailing Lipschitz constant methodology. Additionally, we employ the Nash social welfare program to ensure our solution yields a Pareto optimal distribution of group fairness. Extensive experimentation on real-world datasets demonstrates GraphGini's efficacy in significantly improving individual fairness compared to state-of-the-art methods while maintaining utility and group fairness.
Document summarization facilitates efficient identification and assimilation of user-relevant content, a process inherently influenced by individual subjectivity. Discerning $\textit{subjective}$ salient information within a document, particularly when it has multiple facets, poses significant challenges. This complexity underscores the necessity for $\textit{personalized summarization}$. However, training models for personalized summarization has so far been challenging, particularly because diverse training data containing both user preference history (i.e., $\textit{click-skip}$ trajectory) and expected (gold-reference) summaries are scarce. The MS/CAS PENS dataset is a rare resource in this direction. However, the training data only contains preference history $\textit{without any target summaries}$, thereby blocking end-to-end supervised learning. Also, the diversity in terms of topic transitions along the trajectory is relatively low, thereby leaving scope for better generalization. To address this, we propose PerAugy, a novel $\textit{cross-trajectory shuffling}$ and $\textit{summary-content perturbation}$-based data augmentation technique that significantly boosts the accuracy of four state-of-the-art (SOTA) baseline user-encoders commonly used in personalized summarization frameworks (\text{best result}: $\text{0.132}$$\uparrow$ w.r.t AUC). We select two such SOTA summarizer frameworks as baselines and observe that when augmented with their corresponding improved user-encoders, they consistently show an increase in personalization ($\text{avg. boost}$: ${61.2\%}\uparrow$ w.r.t. PSE-SU4 metric). As a post-hoc analysis of the role of induced diversity in the augmented dataset by PerAugy, we introduce three dataset diversity metrics -- $\mathrm{TP}$, $\mathrm{RTC}$, and DegreeD to quantify the induced diversity. We find that $\mathrm{TP}$ and DegreeD have a strong correlation with the user-encoder performance when trained on the PerAugy-generated dataset across all accuracy metrics, indicating that the increase in dataset diversity plays a major role in performance gain.

Recent advances in neural surrogate modeling offer the potential for transformative innovations in applications such as automotive aerodynamics. Yet, industrial-scale problems often involve volumetric meshes with cell counts reaching 100 million, presenting major scalability challenges. Complex geometries further complicate modeling through intricate surface-volume interactions, while quantities such as vorticity are highly nonlinear and must satisfy strict divergence-free constraints. To address these requirements, we introduce AB-UPT as a novel modeling scheme for building neural surrogates for CFD simulations. AB-UPT is designed to: (i) decouple geometry encoding and prediction tasks via multi-branch operators; (ii) enable scalability to high-resolution outputs via neural simulation in a low-dimensional latent space, coupled with anchored neural field decoders to predict high-fidelity outputs; (iii) enforce physics consistency by a divergence-free formulation. We show that AB-UPT yields state-of-the-art predictive accuracy of surface and volume fields on automotive CFD simulations ranging from 33 thousand up to 150 million mesh cells. Furthermore, our anchored neural field architecture enables the enforcement of hard physical constraints on the physics predictions without degradation in performance, exemplified by modeling divergence-free vorticity fields. Notably, the proposed models can be trained on a single GPU in less than a day and predict industry-standard surface and volume fields within seconds. Additionally, we show that the flexible design of our method enables neural simulation from a CAD geometry alone, thereby eliminating the need for costly CFD meshing procedures for inference.
Sentence representation learning is still an open challenge in Natural Language Processing. In this work, we propose a new self-supervised framework for learning sentence representations, using a special type of neural network called a recursive hypernetwork. Our proposed model composes the representation of a sentence from representations of words by applying a recursive composition through the parse tree. We maintain a separate syntactic and semantic representation, and the semantic composition is guided by the information from the syntactic representation. To train this model, we introduce a novel set of six self-supervised tasks. By analysing the performance on 7 probing tasks, we validate that the generated sentence representation encodes richer linguistic information than both averaging baselines and state-of-the-art alternatives. Furthermore, we assess the impact of the six proposed self-supervised training tasks through ablation studies. We also demonstrate that the representations generated by our model are stable for sentences of varying length and that the semantic composition operators adapt to different syntactic categories.

Adapting pre-trained foundation models to novel sensor modalities is a fundamental challenge. These models are pre-trained on large RGB datasets that typically lack exposure to the imaging characteristics of other modalities. Physical acquisition effects, such as photon statistics and sensor-specific noise, produce appearance shifts that are underrepresented in pre-training and can degrade transfer performance. We propose a noise-aware adaptation framework that conditions model adaptation on sensor-specific acquisition statistics. Central to our approach is a lightweight Noise Adapter that modulates pre-trained visual features using summary statistics of the sensor’s outputs, to decouple acquisition-induced appearance variation from semantics and improve robustness in low-label regimes. We instantiate this idea as a case study on single-photon LiDAR depth images by designing a Noise Adapter that leverages summary statistics computed from raw single-photon histograms for few-shot classification. We also present an exploratory analysis showing how learned modulation patterns correspond to noise-induced feature shifts, providing insight into the adapter’s role in feature robustness. Experiments on both synthetic and real single-photon datasets show that our method improves accuracy over baselines, with an average improvement of 3\% over the best baseline. These results suggest that explicitly conditioning adaptation on physical acquisition factors is a practical and promising strategy that may generalize to other non-standard modalities. The code is available at~\url{https://github.com/ZiTingW/noise_adapter}.
State-Space Models (SSMs) have re-emerged as a powerful tool for online function approximation, and as the backbone of machine learning models for long-range dependent data. However, to date, only a few polynomial bases have been explored for this purpose, and the state-of-the-art implementations were built upon the best of a few limited options. In this paper, we present a generalized method for building an SSM with any frame or basis, rather than being restricted to polynomials. This framework encompasses the approach known as HiPPO, but also permits an infinite diversity of other possible "species" within the SSM architecture. We dub this approach SaFARi: SSMs for Frame-Agnostic Representation.
We introduce D2AC, a new model-free reinforcement learning (RL) algorithm designed to train expressive diffusion policies online effectively. At its core is a policy improvement objective that avoids the high variance of typical policy gradients and the complexity of backpropagation through time. This stable learning process is critically enabled by our second contribution: a robust distributional critic, which we design through a fusion of distributional RL and clipped double Q-learning. The resulting algorithm is highly effective, achieving state-of-the-art performance on a benchmark of eighteen hard RL tasks, including Humanoid, Dog, and Shadow Hand domains, spanning both dense-reward and goal-conditioned RL scenarios. Beyond standard benchmarks, we also evaluate a biologically motivated predator-prey task to examine the behavioral robustness and generalization capacity of our approach.

The power of visual language models is showcased in visual understanding tasks, where language-guided models achieve impressive flexibility and precision. In this paper, we extend this capability to the challenging domain of image matting by framing it as a soft grounding problem, enabling a single diffusion model to handle diverse objects, textures, and transparencies, all directed by descriptive text prompts. Our method teaches the diffusion model to ground alpha mattes by guiding it through a process of instance-level localization and transparency estimation. First, we introduce an intermediate objective that trains the model to accurately localize semantic components of the matte based on natural language cues, establishing a robust spatial foundation. Building on this, the model progressively refines its transparency estimation abilities, using the learned semantic structure as a prior to enhance the precision of alpha matte predictions. By treating spatial localization and transparency estimation as distinct learning objectives, our approach allows the model to fully leverage the semantic depth of diffusion models, removing the need for rigid visual priors. Extensive experiments highlight our model’s adaptability, precision, and computational efficiency, setting a new benchmark for flexible, text-driven image matting solutions.
Neural networks can learn spurious correlations in the data, often leading to performance degradation for underrepresented subgroups. Studies have demonstrated that the disparity is amplified when knowledge is distilled from a complex teacher model to a relatively ``simple'' student model. Prior work has shown that ensemble deep learning methods can improve the performance of the worst-case subgroups; however, it is unclear if this advantage carries over when distilling knowledge from an ensemble of teachers, especially when the teacher models are debiased. This study demonstrates that traditional ensemble knowledge distillation can significantly drop the performance of the worst-case subgroups in the distilled student model even when the teacher models are debiased. To overcome this, we propose Adaptive Group Robust Ensemble Knowledge Distillation (\AGREKD), a simple ensembling strategy to ensure that the student model receives knowledge beneficial for unknown underrepresented subgroups. Leveraging an additional biased model, our method selectively chooses teachers whose knowledge would better improve the worst-performing subgroups by upweighting the teachers with gradient directions deviating from the biased model. Our experiments on several datasets demonstrate the superiority of the proposed ensemble distillation technique and show that it can even outperform classic model ensembles based on majority voting. Our source code is available at https://github.com/patrikken/AGRE-KD.

Pretrained models are ubiquitous in the current deep learning landscape, offering strong results on a broad range of tasks. Recent works have shown that models differing in various design choices exhibit categorically diverse generalization behavior, resulting in one model grasping distinct data-specific insights unavailable to the other. In this paper, we propose to leverage large publicly available model repositories as an auxiliary source of model improvements. We introduce a data partitioning strategy where pretrained models autonomously adopt either the role of a student, seeking knowledge, or that of a teacher, imparting knowledge. Experiments across various tasks demonstrate the effectiveness of our proposed approach. In image classification, we improved the performance of ViT-B by approximately 1.4\% through bidirectional knowledge transfer with ViT-T. For semantic segmentation, our method boosted all evaluation metrics by enabling knowledge transfer both within and across backbone architectures. In video saliency prediction, our approach achieved a new state-of-the-art. We further extend our approach to knowledge transfer between multiple models, leading to considerable performance improvements for all model participants.
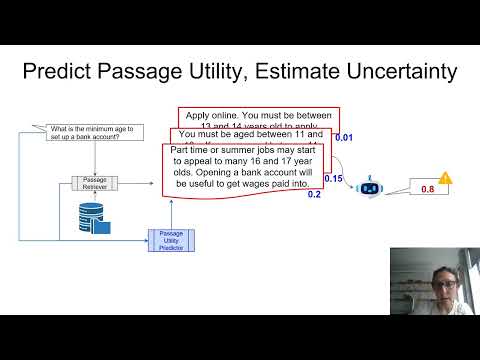
Retrieval augmented Question Answering (QA) helps QA models overcome knowledge gaps by incorporating retrieved evidence, typically a set of passages, alongside the question at test time. Previous studies show that this approach improves QA performance and reduces hallucinations, without, however, assessing whether the retrieved passages are indeed useful at answering correctly. In this work, we propose to quantify the uncertainty of a QA model via estimating the utility of the passages it is provided with. We train a lightweight neural model to predict passage utility for a target QA model and show that while simple information theoretic metrics can predict answer correctness up to a certain extent, our approach efficiently approximates or outperforms more expensive sampling-based methods.
Regularized models are often sensitive to the scales of the features in the data and it has therefore become standard practice to normalize (center and scale) the features before fitting the model. But there are many different ways to normalize the features and the choice may have dramatic effects on the resulting model. In spite of this, there has so far been no research on this topic. In this paper, we begin to bridge this knowledge gap by studying normalization in the context of lasso, ridge, and elastic net regression. We focus on binary features and show that their class balances (proportions of ones) directly influences the regression coefficients and that this effect depends on the combination of normalization and regularization methods used. We demonstrate that this effect can be mitigated by scaling binary features with their variance in the case of the lasso and standard deviation in the case of ridge regression, but that this comes at the cost of increased variance of the coefficient estimates. For the elastic net, we show that scaling the penalty weights, rather than the features, can achieve the same effect. Finally, we also tackle mixes of binary and normal features as well as interactions and provide some initial results on how to normalize features in these cases.

Data-to-text (D2T) generation is a core task in text generation that involves converting semi-structured data (e.g., tables, graphs) into text. Recent advances in large language models (LLMs) have led to significant improvements in D2T. Despite these gains, factual inconsistency remains a persistent issue in LLMs for D2T. Understanding how such inconsistencies scale with factors like model size, compute (FLOPs), and data size is crucial for building trustworthy systems. While prior scaling studies focus on generalization error via power law scaling, the impact of these factors on factual inconsistency in D2T remains unexplored. This paper addresses the gap by empirically investigating how factual inconsistency scales with various scaling factors. Unlike prior studies that focus solely on power law scaling, we also examine exponential scaling. To rigorously compare these models, we introduce \textit{VaCScal}, a three-stage statistical validation framework: (1) predictive performance estimation, (2) goodness-of-fit assessment, and (3) comparative analysis. Experiments are conducted across six diverse LLM families and five D2T datasets. Factual inconsistency is inversely measured using four state-of-the-art consistency metrics, including human evaluation. We employ QLoRA, Prefix-Tuning, and full fine-tuning to fine-tune the LLMs. Our analysis, validated through the \textit{VaCScal} framework, consistently shows that factual inconsistency in D2T generation follows exponential scaling with respect to model (LLM) size, compute (FLOPs), and fine-tuning data size---challenging the prevailing assumption of power law scaling. To support this finding, a mathematical rationale is also provided, demonstrating why exponential scaling behavior is expected in factual inconsistency under typical D2T conditions.

In many situations, the measurements of a studied phenomenon are provided sequentially, and the prediction of its class needs to be made as early as possible so as not to incur too high a time penalty, but not too early and risk paying the cost of misclassification. This problem has been particularly studied in the case of time series, and is known as Early Classification of Time Series (ECTS). Although it has been the subject of a growing body of literature, there is still a lack of a systematic, shared evaluation protocol to compare the relative merits of the various existing methods. In this paper, we highlight the two components of an ECTS system: \textit{decision} and \textit{prediction}, and focus on the approaches that separate them. This document begins by situating these methods within a principle-based taxonomy. It defines dimensions for organizing their evaluation and then reports the results of a very extensive set of experiments along these dimensions involving nine state-of-the-art ECTS algorithms. In addition, these and other experiments can be carried out using an open-source library in which most of the existing ECTS algorithms have been implemented (see https://github.com/ML-EDM/ml_edm).
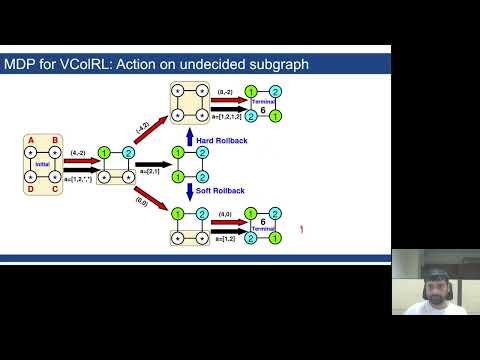
The Vertex Coloring Problem (VCP) is a fundamental NP-hard problem with applications in wireless networks, compiler design, scheduling, etc. We present VColRL, a deep reinforcement learning (DRL) framework that learns to color graphs quickly by leveraging a reduction-based approach that progressively reduces the graph at each step. The core novelty of VColRL is a new Markov Decision Process (MDP) formulation tailored for VCP that assigns colors to multiple vertices at each step, incorporates a rollback mechanism to revert all conflicting vertices to the undecided state, and employs a reward function designed to minimize the highest-indexed color used. Experiments on synthetic and benchmark graphs show that VColRL improves color usage over optimization solvers and prior learning-based methods, remains competitive with search-based heuristics and metaheuristics, and achieves fast runtime, while generalizing well to diverse graph families despite being trained only on synthetic graphs from a single family.

In this work, we present an adjoint-based method for discovering the underlying governing partial differential equations (PDEs) given data. The idea is to consider a parameterized PDE in a general form and formulate a PDE-constrained optimization problem aimed at minimizing the error of the PDE solution from data. Using variational calculus, we obtain an evolution equation for the Lagrange multipliers (adjoint equations), allowing us to compute the gradient of the objective function with respect to the parameters of PDEs given data in a straightforward manner. In particular, we consider a family of temporal parameterized PDEs that encompass linear, nonlinear, and spatial derivative candidate terms, and elegantly derive the corresponding adjoint equations. We show the efficacy of the proposed approach in identifying the form of the PDE up to machine accuracy, enabling the accurate discovery of PDEs from data. We also compare its performance with the famous PDE Functional Identification of Nonlinear Dynamics method known as PDE-FIND \cite{rudy2017data} among others, on both smooth and noisy data sets. Even though the proposed adjoint method relies on forward/backward solvers, it outperforms PDE-FIND in the limit of large data sets thanks to the analytic expressions for gradients of the cost function with respect to each PDE parameter.
Large-scale datasets invariably contain annotation noise. Re-labeling methods have been developed to handle annotation noise in large-scale datasets. Though various methodologies to alleviate annotation noise have been developed, these are particularly time-consuming and computationally intensive. The requirement of high computational power and longer time duration can be drastically reduced by selecting a representative coreset. In this work, we adapt a noise-free gradient-based coreset selection method towards re-labeling applications for noisy datasets with erroneous labels. We introduce ‘confidence score’ to the coreset selection method to cater for the presence of noisy labels. Through extensive evaluation over CIFAR-100N, Web Vision, and ImageNet-1K Datasets, we demonstrate that our method outperforms the SOTA coreset selection for re-labeling methods (DivideMix and SOP+). We have provided the codebase at URL.

In this paper, we delve into a new perspective to solve image matting by revealing the foreground with flash priors. Previous Background Matting frameworks require a clean background as input, and although demonstrated powerfully, they are not practical to handle real-world scenarios with dynamic camera or background movement. We introduce the flash/no-flash image pair to portray the foreground object while eliminating the influence of dynamic background. The rationale behind this is that the foreground object is closer to the camera and thus received more light than the background. We propose a cascaded end-to-end network to integrate flash prior knowledge into the alpha matte estimation process. Particularly, a transformer-based Foreground Correlation Module is presented to connect foregrounds exposed in different lightings, which can effectively filter out the perturbation from the dynamic background and also robust to foreground motion. The initial prediction is concatenated with a Boundary Matting Network to polish the details of previous predictions. To supplement the training and evaluation of our flash/no-flash framework, we construct the first flash/no-flash portrait image matting dataset with 3,025 well-annotated alpha mattes. Experimental evaluations show that our proposed model significantly outperforms existing trimap-free matting methods on scenes with dynamic backgrounds. Moreover, we detailedly discuss and analyze the effects of different prior knowledge on static and dynamic backgrounds. In contrast to the restricted scenarios of Background Matting, we demonstrate a flexible and reliable solution in real-world cases with the camera or background movements.
Following rapid advancements in text and image generation, research has increasingly shifted towards 3D generation. Unlike the well-established pixel-based representation in images, 3D representations remain diverse and fragmented, encompassing a wide variety of approaches such as voxel grids, neural radiance fields, signed distance functions, point clouds, or octrees, each offering distinct advantages and limitations. In this work, we present a unified evaluation framework designed to assess the performance of 3D representations in reconstruction and generation. We compare these representations based on multiple criteria: quality, computational efficiency, and generalization performance. Beyond standard model benchmarking, our experiments aim to derive best practices over all steps involved in the 3D generation pipeline, including preprocessing, mesh reconstruction, compression with autoencoders, and generation. Our findings highlight that reconstruction errors significantly impact overall performance, underscoring the need to evaluate generation and reconstruction jointly. We provide insights that can inform the selection of suitable 3D models for various applications, facilitating the development of more robust and application-specific solutions in 3D generation. The code for our framework is available at https://github.com/isl-org/unifi3d.
Multimodal models often experience a significant performance drop when one or more modalities are missing during inference. To address this challenge, we propose a simple yet effective approach that enhances robustness to missing modalities while maintaining strong performance when all modalities are available. Our method introduces cross-modal proxy tokens (CMPTs), which approximate the class token of a missing modality by attending only to the tokens of the available modality without requiring explicit modality generation or auxiliary networks. To efficiently learn these approximations with minimal computational overhead, we employ low-rank adapters in frozen unimodal encoders and jointly optimize an alignment loss with a task-specific loss. Extensive experiments on five multimodal datasets show that our method outperforms state-of-the-art baselines across various missing rates while achieving competitive results in complete-modality settings. Overall, our method offers a flexible and efficient solution for robust multimodal learning. The code for this paper is available at: https://github.com/CSIPlab/Cross-Modal-Proxy-Tokens.

A key challenge in the field of reinforcement learning is to develop agents that behave cautiously in novel situations. It is generally impossible to anticipate all situations that an autonomous system may face or what behavior would best avoid bad outcomes. An agent that could learn to be cautious would overcome this challenge by discovering for itself when and how to behave cautiously. In contrast, current approaches typically embed task-specific safety information or explicitly cautious behaviors into the system, which is error-prone and imposes extra burdens on practitioners. In this paper, we present both a sequence of tasks where cautious behavior becomes increasingly non-obvious, as well as an algorithm to demonstrate that it is possible for a system to learn to be cautious. The essential features of our algorithm are that it characterizes reward function uncertainty without task-specific safety information and uses this uncertainty to construct a robust policy. Specifically, we construct robust policies with a $k$-of-$N$ counterfactual regret minimization (CFR) subroutine given a learned reward function uncertainty represented by a neural network ensemble belief. These policies exhibit caution in each of our tasks without any task-specific safety tuning. Our code is available at https://github.com/montaserFath/Learning-to-be-Cautious
Sparse Mixture of Experts (SMoE) is an effective solution for scaling up model capacity without increasing the computational costs. A crucial component of SMoE is the router, responsible for directing the input to relevant experts; however, it also presents a major weakness, leading to routing inconsistencies and representation collapse issues. Instead of fixing the router like previous works, we propose an alternative that assigns experts to input via \emph{indirection}, which employs the discrete representation of input that points to the expert. The discrete representations are learned via vector quantization, resulting in a new architecture dubbed Vector-Quantized Mixture of Experts (VQMoE). We provide theoretical support and empirical evidence demonstrating the VQMoE's ability to overcome the challenges present in traditional routers. Through extensive evaluations on both large language models and vision tasks for pre-training and fine-tuning, we show that VQMoE achieves a 28\% improvement in robustness compared to other SMoE routing methods while maintaining strong performance in fine-tuning tasks.

Spuriousness arises when there is an association between two or more variables in a dataset that are not causally related. In this work, we propose an explainability framework to preemptively disentangle the nature of such spurious associations in a dataset before model training. We leverage a body of work in information theory called Partial Information Decomposition (PID) to decompose the total information about the target into four non-negative quantities, namely unique information (in core and spurious features, respectively), redundant information, and synergistic information. Our framework helps anticipate when the core or spurious feature is indispensable, when either suffices, and when both are jointly needed for an optimal classifier trained on the dataset. Next, we leverage this decomposition to propose a novel measure of the spuriousness of a dataset. We arrive at this measure systematically by examining several candidate measures, and demonstrating what they capture and miss through intuitive canonical examples and counterexamples. Our framework Spurious Disentangler consists of segmentation, dimensionality reduction, and estimation modules, with capabilities to specifically handle high-dimensional image data efficiently. Finally, we also perform empirical evaluation to demonstrate the trends of unique, redundant, and synergistic information, as well as our proposed spuriousness measure across $6$ benchmark datasets under various experimental settings. We observe an agreement between our preemptive measure of dataset spuriousness and post-training model generalization metrics such as worst-group accuracy, further supporting our proposition. The code is available at https://github.com/Barproda/spuriousness-disentangler.
Grounding the instruction in the environment is a key step in solving language-guided goal-reaching reinforcement learning problems. In automated reinforcement learning, a key concern is to enhance the model's ability to generalize across various tasks and environments. In goal-reaching scenarios, the agent must comprehend the different parts of the instructions within the environmental context in order to complete the overall task successfully. In this work, we propose \textbf{CAREL} (\textit{\textbf{C}ross-modal \textbf{A}uxiliary \textbf{RE}inforcement \textbf{L}earning}) as a new framework to solve this problem using auxiliary loss functions inspired by video-text retrieval literature and a novel method called instruction tracking, which automatically keeps track of progress in an environment. The results of our experiments suggest superior sample efficiency and systematic generalization for this framework in multi-modal reinforcement learning problems.

Inverse reinforcement learning is the problem of inferring a reward function from an optimal policy {or demonstrations by an expert}. In this work, it is assumed that the reward is expressed as a reward machine whose transitions depend on atomic propositions associated with the state of a Markov Decision Process (MDP). Our goal is to identify the true reward machine using finite information. To this end, we first introduce the notion of a prefix tree policy which associates a distribution of actions to each state of the MDP and each attainable finite sequence of atomic propositions. Then, we characterize an equivalence class of reward machines that can be identified given the prefix tree policy. Finally, we propose a SAT-based algorithm that uses information extracted from the prefix tree policy to solve for a reward machine. It is proved that if the prefix tree policy is known up to a sufficient (but finite) depth, our algorithm recovers the exact reward machine up to the equivalence class. This sufficient depth is derived as a function of the number of MDP states and (an upper bound on) the number of states of the reward machine.{These results are further extended to the case where we only have access to demonstrations from an optimal policy. Several examples, including discrete grid and block worlds, a continuous state-space robotic arm, and real data from experiments with mice, are used to demonstrate the effectiveness and generality of the approach.
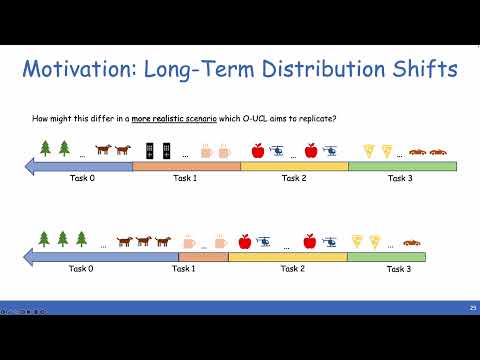
This paper addresses the Online Continual Unsupervised Learning (O-UCL) problem, where a learner must adapt to a stream of data arriving sequentially from a shifting distribution without storing past data or relying on labels. This challenge mirrors many real-world machine learning applications, where efficient training and updating of large or on device models is critical. We first explore the unique challenges of O-UCL and identify a secondary failure mode in addition to catastrophic forgetting. We demonstrate that the presence of transient, small-scale biases in an online data stream can significantly impair learning. Unlike traditional notions of distribution shift that manifest over long timescales, we highlight how biases occurring at the level of individual batches or short segments—while imperceptible in aggregate—can severely hinder a model’s ability to learn, a phenomenon we call ``catastrophic non-learning''. We further showcase how an auxiliary memory can be used to solve both catastrophic forgetting and catastrophic non-learning, but that the criteria for the ideal memory for each are in conflict. In response to these findings, we introduce a dual-memory framework which incorporates specifically designed modules to mitigate both catastrophic non-learning and forgetting. We validate our findings on challenging, realistic data streams derived from ImageNet and Places365, comparing against multiple baselines to highlight the distinct nature of this problem and the need for new approaches in O-UCL.
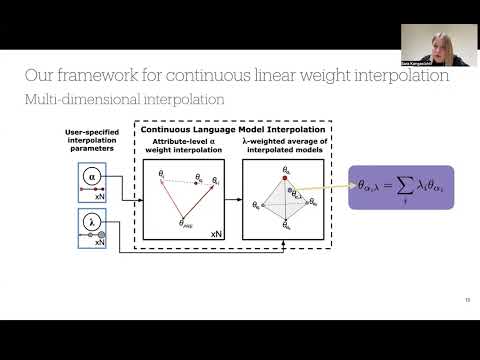
As large language models (LLMs) have gained popularity for a variety of use cases, making them adaptable and controllable has become increasingly important, especially for user-facing applications. In particular, linear interpolation between model parameters forms the backbone for many recent approaches to adapting models to user preferences. While the existing literature on LLM adaptation primarily focuses on finding methods that optimize for some set of performance criteria or user preferences, here we instead seek to better understand and characterize the behavior of dense, continuous interpolation between models. Specifically, we use low-rank updates to fine-tune a base model to various different domains, yielding a set of anchor models with distinct generation profiles. Then, we use the weight updates of these anchor models to parametrize the entire (infinite) class of models contained within their convex hull. We empirically show that varying the interpolation weights yields predictable and consistent change in the model outputs with respect to all of the controlled attributes simultaneously. We find that there is little entanglement between most attributes and identify and discuss the pairs of attributes for which this is not the case. Our results suggest that parameter merging facilitates flexible model adaptation due to its predictable behavior within the full interpolation region.
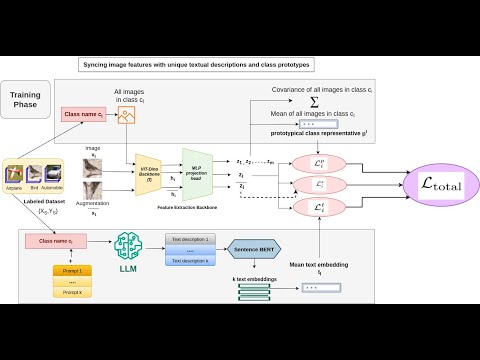
Contemporary deep learning models are very successful in recognizing predetermined categories, but often struggle when confronted with novel ones, constraining their utility in the real world. Identifying this research gap, On-the-fly Category Discovery aims to enable machine learning systems trained on closed labeled datasets to promptly discern between novel and familiar categories of the test-images encountered in an online manner (one image at a time), along with clustering the different new classes as and when they are encountered. To address this challenging task, we propose SynC, a pragmatic yet robust framework that capitalizes on the presence of category names within the labeled datasets and the powerful knowledge-base of Large Language Models to obtain unique feature representations for each class. It also dynamically updates the classifiers of both the seen and novel classes for improved class discriminability. An extended variant, SynC-AL incorporates a lightweight active learning module to mitigate errors during inference, for long-term model deployment. Extensive evaluation show that SynC and SynC-AL achieve state-of-the-art performance across a spectrum of classification datasets.

This paper introduces a cost-efficient active learning (AL) framework for classification, featuring a novel query design called candidate set query. Unlike traditional AL queries requiring the oracle to examine all possible classes, our method narrows down the set of candidate classes likely to include the ground-truth class, significantly reducing the search space and labeling cost. Moreover, we leverage conformal prediction to dynamically generate small yet reliable candidate sets, adapting to model enhancement over successive AL rounds. To this end, we introduce an acquisition function designed to prioritize data points that offer high information gain at lower cost. Empirical evaluations on CIFAR-10, CIFAR-100, and ImageNet64x64 demonstrate the effectiveness and scalability of our framework. Notably, it reduces labeling cost by 48% on ImageNet64x64. The project page can be found at https://yehogwon.github.io/csq-al.

While Large Language Models (LLMs) have revolutionized chatbot interactions, they often fall short of aligning responses with the nuanced preferences of individual users, a challenge rooted in the inherently subjective and proprietary nature of those preferences. Consequently, prompt-based learning, though effective in enhancing factual accuracy due to its emphasis on universal correctness, remains insufficient for achieving accurate personalised response alignment. Because user preferences vary widely across individuals and contexts, aligning responses requires a more personalized and context-aware approach. To address this limitation, we propose Consistent Marginalization (CM), a novel framework that aims to unlearn misalignment by constructing a personalised memory bank of instance-response-dependent discrepancies, built from a small set of user preference samples. This personalised memory bank equips LLMs with the ability to understand, recall, and adapt to individual preferences, enabling more consistent and personalized responses. Evaluated across a diverse range of domain-specific datasets and model architectures, CM yields notable improvements in response alignment and robustness. We believe Consistent Marginalization represents a valuable step toward enabling LLMs to become genuinely personable and adaptive conversational agents by understanding user preferences and generating responses that are better aligned with individual user expectations.
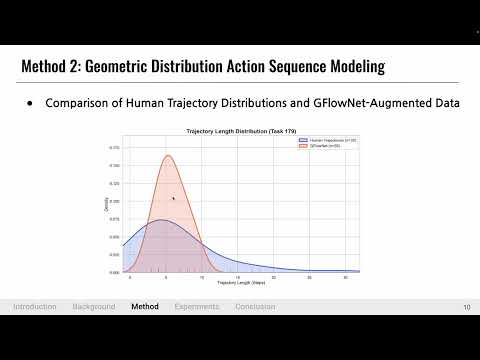
One of the core challenges in building general reasoning systems lies in generating diverse, human-aligned solution trajectories—different yet valid paths by which a problem can be solved. Prior approaches often rely on handcrafted templates, rule-based augmentations, or human demonstrations, which are limited in scalability and stylistic diversity. To address this, we explore the use of Generative Flow Networks (GFlowNets) for automated solution augmentation in reasoning tasks. We propose a framework that learns to generate diverse reasoning trajectories with probabilities proportional to their quality, guided by a human-inspired reward function and a novel geometric forward policy. This enables the generation of multiple plausible solution paths without relying on manual supervision. Moreover, our method supports efficient test-time augmentation from input-output examples alone, without access to ground-truth programs or external demonstrations—making it suitable for zero-shot settings. We evaluate our framework on the Abstraction and Reasoning Corpus (ARC-AGI), a benchmark designed to test compositional and abstract reasoning. Our results show that GFlowNets can effectively explore the space of valid reasoning processes, producing a variety of plausible reasoning trajectories, similar to how different individuals might solve the same problem using different intermediate steps. These trajectories are generated at scale-over 100k per task in under an hour, and follow a logarithmic yield trend, enabling practical tradeoffs between augmentation volume and novelty. Furthermore, fine-tuning a large language model (LLaMA 3.1 Instruct 8B) on these synthetic trajectories leads to a 28.6% improvement in reasoning accuracy on ARC tasks, demonstrating the downstream utility of our method. These findings suggest that GFlowNets offer a promising foundation for modeling structured reasoning in automated trajectory generation. Our code is here: https://github.com/GIST-DSLab/GFN_to_ARC
Recent text-to-image generative models have exhibited an impressive ability to generate fairly realistic images from some text prompts. In this work, we explore to leverage off-the-shelf text-to-image generative models to train non-specific downstream few-shot classification model architectures using synthetic dataset to classify real images. Current approaches use hand-crafted or model-generated text prompts of text-to-image generative models to generate desired synthetic images, however, they have limited capability of generating diverse images. Especially, their synthetic datasets have relatively limited relevance to the downstream classification tasks. This makes them fairly hard to guarantee training models from synthetic images are efficient in practice. To address this issue, we propose a method capable of adaptively learning proper text prompts for the off-the-shelf diffusion model to generate diverse and classification-aware synthetic images. Our approach shows consistently improvements in various classification datasets, with results comparable to existing prompt designing methods. We find that replacing data generation strategy of existing zero/few-shot methods with proposed method could consistently improve downstream classification performance across different network architectures, demonstrating its model-agnostic potential for few-shot learning. This makes it possible to train an efficient downstream few-shot learning model from synthetic images generated by proposed method for real problems.
How much is a node worth? We answer this question using an emerging set of data valuation techniques, where the value of a data point is measured via its marginal contribution when added to the (training) dataset. Data valuation has been primarily studied in the i.i.d. setting, giving rise to methods like influence functions, leave-one-out estimation, data Shapley, and data Banzhaf. We conduct a comprehensive study of data valuation approaches applied to graph-structured models such as graph neural networks in a semi-supervised transductive setting. Since all nodes (labeled and unlabeled) influence both training and inference we construct various scenarios to understand the diverse mechanisms by which nodes can impact learning. We show that the resulting node values can be used to identify (positively and negatively) influential nodes, quantify model brittleness, detect poisoned data, and accurately predict counterfactuals.

Causal effect identification using causal graphs is a fundamental challenge in causal inference. While extensive research has been conducted in this area, most existing methods assume the availability of fully specified directed acyclic graphs or acyclic directed mixed graphs. However, in complex domains such as medicine and epidemiology, complete causal knowledge is often unavailable, and only partial information about the system is accessible. This paper focuses on causal effect identification within partially specified causal graphs, with particular emphasis on cluster-directed mixed graphs (C-DMGs) which can represent many different acyclic directed mixed graphs (ADMGs). These graphs provide a higher-level representation of causal relationships by grouping variables into clusters, offering a more practical approach for handling complex systems. Unlike fully specified ADMGs, C-DMGs can contain cycles, which complicate their analysis and interpretation. Furthermore, their cluster-based nature introduces new challenges, as it gives rise to two distinct types of causal effects: macro causal effects and micro causal effects, each with different properties. In this work, we focus on macro causal effects, which describe the effects of entire clusters on other clusters. We establish that the do-calculus is both sound and complete for identifying these effects in C-DMGs over ADMGs when the cluster sizes are either unknown or of size greater than one. Additionally, we provide a graphical characterization of non-identifiability for macro causal effects in these graphs.

We introduce Large Language Model-Assisted Preference Prediction (LAPP), a novel framework for robot learning that enables efficient, customizable, and expressive behavior acquisition with minimum human effort. Unlike prior approaches that rely heavily on reward engineering, human demonstrations, motion capture, or expensive pairwise preference labels, LAPP leverages large language models (LLMs) to automatically generate preference labels from raw state-action trajectories collected during reinforcement learning (RL). These labels are used to train an online preference predictor, which in turn guides the policy optimization process toward satisfying high-level behavioral specifications provided by humans. Our key technical contribution is the integration of LLMs into the RL feedback loop through trajectory-level preference prediction, enabling robots to acquire complex skills including subtle control over gait patterns and rhythmic timing. We evaluate LAPP on a diverse set of quadruped locomotion and dexterous manipulation tasks and show that it achieves efficient learning, higher final performance, faster adaptation, and precise control of high-level behaviors. Notably, LAPP enables robots to master highly dynamic and expressive tasks such as quadruped backflips, which remain out of reach for standard LLM-generated or handcrafted rewards. Our results highlight LAPP as a promising direction for scalable preference-driven robot learning.
In this paper, we challenge the conventional view of dead neurons—neurons that cease to activate—during deep neural network training. Traditionally regarded as problematic due to their association with optimization challenges and reduced model adaptability over training epochs, dead neurons are often seen as a hindrance. However, we present a novel perspective, demonstrating that they can be effectively leveraged to enhance network sparsity. Specifically, we propose DNR-Pruning, dying neuron reactivation based sparsity-aware pruning approach for convolutional neural networks (CNNs) that exploits the behavior of individual neurons during training. Through a systematic exploration of hyperparameter configurations, we show that dying neurons can be harnessed to improve pruning algorithms. Our method dynamically monitors the occurrence of dying neurons, enabling adaptive sparsification throughout CNN training. Extensive experiments on diverse datasets demonstrate that DNR-Pruning outperforms existing sparsity-aware pruning techniques while achieving competitive results compared to state-of-the-art methods. These findings suggest that dying neurons can serve as an efficient mechanism for network compression and resource optimization in CNNs, opening new avenues for more efficient and high-performance deep learning models.
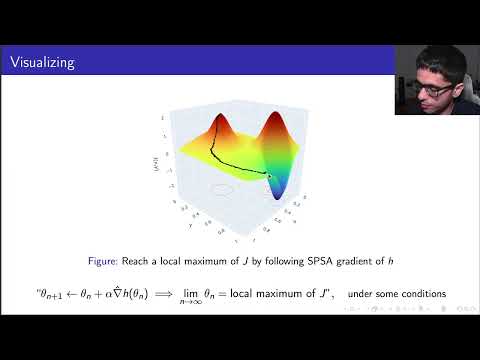
We revisit the REINFORCE policy gradient algorithm from the literature that works with reward (or cost) returns obtained over episodes or trajectories. We propose a major enhancement to the basic algorithm where we estimate the policy gradient using a smoothed functional (random perturbation) gradient estimator obtained from direct function measurements. To handle the issue of high variance that is typical of REINFORCE, we propose two independent enhancements to the basic scheme: (i) use the sign of the increment instead of the original (full) increment that results in smoother convergence and (ii) use clipped gradient estimates as proposed in the Proximal Policy Optimization (PPO) based scheme. We prove the asymptotic convergence of all algorithms and show the results of several experiments on various MuJoCo locomotion tasks wherein we compare the performance of our algorithms with the recently proposed ARS algorithms in the literature as well as other well known algorithms namely A2C, PPO and TRPO. Our algorithms are seen to be competitive against all algorithms and in fact show the best results on a majority of experiments.

Out-of-distribution (OOD) detection is crucial for ensuring the reliability of deep learning models in real-world applications. Existing methods typically focus on feature representations or output-space analysis, often assuming a distribution over these spaces or leveraging gradient norms with respect to model parameters. However, these approaches struggle to distinguish near-OOD samples and often require extensive hyper-parameter tuning, limiting their practicality. In this work, we propose GRadient-aware Out-Of-Distribution detection (GROOD), a method that derives an OOD prototype from synthetic samples and computes class prototypes directly from In-distribution (ID) training data. By analyzing the gradients of a nearest-class-prototype loss function concerning an artificial OOD prototype, our approach achieves a clear separation between in-distribution and OOD samples. Experimental evaluations demonstrate that gradients computed from the OOD prototype enhance the distinction between ID and OOD data, surpassing established baselines in robustness, particularly on ImageNet-1k. These findings highlight the potential of gradient-based methods and prototype-driven approaches in advancing OOD detection within deep neural networks.
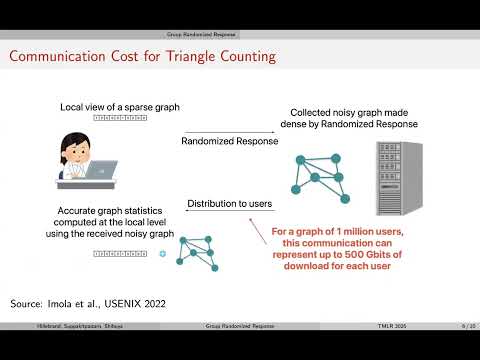
We suggest the use of hash functions to cut down the communication costs when counting subgraphs under edge local differential privacy. While various algorithms exist for computing graph statistics --- including the count of subgraphs --- under the edge local differential privacy, many suffer with high communication costs, making them less efficient for large graphs. Though data compression is a typical approach in differential privacy, its application in local differential privacy requires a form of compression that every node can reproduce. In our study, we introduce linear congruence hashing. Leveraging amplification by sub-sampling, with a sampling size of $s$, our method can cut communication costs by a factor of $s^2$, albeit at the cost of increasing variance in the published graph statistic by a factor of $s$. The experimental results indicate that, when matched for communication costs, our method achieves a reduction in the $\ell_2$-error by up to 1000 times for triangle counts and by up to $10^3$ times for 4-cycles counts compared to the performance of leading algorithms.
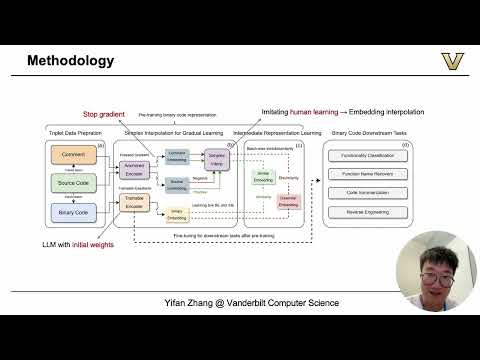
Binary code analysis and comprehension is critical to applications in reverse engineering and computer security tasks where source code is not available. Unfortunately, unlike source code, binary code lacks semantics and is more difficult for human engineers to understand and analyze. In this paper, we present ContraBin, a contrastive learning technique that integrates source code and comment information along with binaries to create an embedding capable of aiding binary analysis and comprehension tasks. Specifically, we present three components in ContraBin: (1) a primary contrastive learning method for initial pre-training, (2) a simplex interpolation method to integrate source code, comments, and binary code, and (3) an intermediate representation learning algorithm to train a binary code embedding. We further analyze the impact of human-written and synthetic comments on binary code comprehension tasks, revealing a significant performance disparity. While synthetic comments provide substantial benefits, human-written comments are found to introduce noise, even resulting in performance drops compared to using no comments. These findings reshape the narrative around the role of comment types in binary code analysis. We evaluate the effectiveness of ContraBin through four indicative downstream tasks related to binary code: algorithmic functionality classification, function name recovery, code summarization, and reverse engineering. The results show that ContraBin considerably improves performance on all four tasks, measured by accuracy, mean of average precision, and BLEU scores as appropriate. ContraBin is the first language representation model to incorporate source code, binary code, and comments into contrastive code representation learning and is intended to contribute to the field of binary code analysis. The dataset used in this study is available for further research.
Despite the impressive performance of recent Large Vision-Language Models (LVLMs), these models often produce inaccurate responses. To address this issue, previous studies have aimed to reduce hallucinations by using contrastive decoding (CD) with modified images, such as cropping objects related to query or adding noise, thereby contrasting with the original image. However, these methods have several limitations. First, employing fixed visual augmentation, such as adding noise, is a simple approach but too rigid to contrast on various queries. Conversely, using semantics in queries or images by leveraging external models can adaptively generate contrastive images, but it entails significant additional costs. To address these shortcomings, we explore using pre-defined visual augmentations to enable flexible adaptation to each query without relying on external models. We observe that each query achieves different contrasts through different visual augmentations. Based on this, we propose a novel method called VSCoDe, Visual-Augmentation Selection for Contrastive Decoding, which adaptively selects augmentations using a proposed distance metric to identify those with higher contrast. Our empirical evaluations demonstrate that VSCoDe outperforms previous methods and enhances the quality of various vision-language tasks without additional training or reliance on external models.
Deep learning involves navigating a high-dimensional loss landscape over the neural network parameter space. Over the course of training, complex computational structures form and re-form inside the neural network, leading to shifts in input/output behavior. It is a priority for the science of deep learning to uncover principles governing the development of neural network structure and behavior. Drawing on the framework of singular learning theory, we propose that model development is deeply linked to degeneracy in the local geometry of the loss landscape. We investigate this link by monitoring loss landscape degeneracy throughout training, as quantified by the local learning coefficient, for a transformer language model and an in-context linear regression transformer. We show that training can be divided into distinct periods of change in loss landscape degeneracy, and that these changes in degeneracy coincide with significant changes in the internal computational structure and the input/output behavior of the transformers. This finding provides suggestive evidence that degeneracy and development are linked in transformers, underscoring the potential of a degeneracy-based perspective for understanding modern deep learning.
The classical $k$-means clustering algorithm requires complete data and cannot be directly applied when observations contain missing entries. An intuitive and computationally efficient extension addresses this issue by minimizing the $k$-means loss over the observed entries only, a strategy considered in several studies. This method is known as $k$-POD clustering. In this paper, we provide a theoretical analysis of this approach and demonstrate that it is generally inconsistent, even under the missing completely at random (MCAR) assumption. Specifically, we show that the expected loss being minimized asymptotically differs from the original $k$-means objective, leading to biased estimates of cluster centers in the large-sample limit. This highlights a fundamental limitation: the method may fail to recover the true underlying cluster structure, even in settings where $k$-means performs well on fully observed data. Nevertheless, when the missing rate per variable is sufficiently low and the dimensionality is high, the method can still produce stable and practically useful results, making it a viable alternative when the complete-case analysis is ineffective.
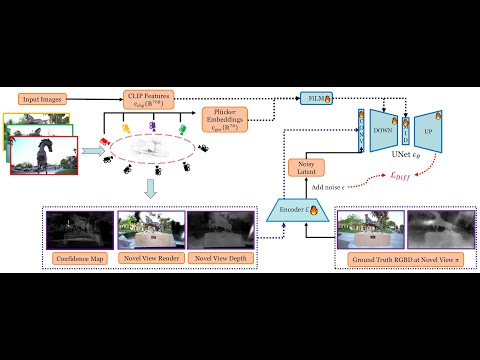
In this work, we introduce a generative approach for pose-free (without camera parameters) reconstruction of 360 scenes from a sparse set of 2D images. Pose-free scene reconstruction from incomplete, pose-free observations is usually regularized with depth estimation or 3D foundational priors. While recent advances have enabled sparse-view reconstruction of large complex scenes (with high degree of foreground and background detail) with known camera poses using view-conditioned generative priors, these methods cannot be directly adapted for the pose-free setting when ground-truth poses are not available during evaluation. To address this, we propose an image-to-image generative model designed to inpaint missing details and remove artifacts in novel view renders and depth maps of a 3D scene. We introduce context and geometry conditioning using Feature-wise Linear Modulation (FiLM) modulation layers as a lightweight alternative to cross-attention and also propose a novel confidence measure for 3D Gaussian splat representations to allow for better detection of these artifacts. By progressively integrating these novel views in a Gaussian-SLAM-inspired process, we achieve a multi-view-consistent 3D representation. Evaluations on the MipNeRF360 and DL3DV-10K benchmark dataset demonstrate that our method surpasses existing pose-free techniques and performs competitively with state-of-the-art posed (precomputed camera parameters are given) reconstruction methods in complex 360 scenes. Our code and datasets will be open-sourced upon acceptance.

Human teaching effort is a significant bottleneck for the broader applicability of interactive imitation learning. To reduce the number of required queries, existing methods employ active learning to query the human teacher only in uncertain, risky, or novel situations. However, during these queries, the novice’s planned actions are not utilized despite containing valuable information, such as the novice’s capabilities, as well as corresponding uncertainty levels. To this end, we allow the novice to say: “I plan to do this, but I am uncertain.” We introduce the Active Skill-level Data Aggregation (ASkDAgger) framework, which leverages teacher feedback on the novice plan in three key ways: (1) S-Aware Gating (SAG): Adjusts the gating threshold to track sensitivity, specificity, or a minimum success rate; (2) Foresight Interactive Experience Replay (FIER), which recasts valid and relabeled novice action plans into demonstrations; and (3) Prioritized Interactive Experience Replay (PIER), which prioritizes replay based on uncertainty, novice success, and demonstration age. Together, these components balance query frequency with failure incidence, reduce the number of required demonstration annotations, improve generalization, and speed up adaptation to changing domains. We validate the effectiveness of ASkDAgger through language-conditioned manipulation tasks in both simulation and real-world environments. Code, data, and videos are available at https://askdagger.github.io.

Detecting whether an LLM hallucinates is an important research challenge. One promising way of doing so is to estimate the semantic entropy (Farquhar et al., 2024) of the distribution of generated sequences. We propose a new algorithm for doing that, with two main advantages. First, due to us taking the Bayesian approach, we achieve a much better quality of semantic entropy estimates for a given budget of samples from the LLM. Second, we are able to tune the number of samples adaptively so that `harder' contexts receive more samples. We demonstrate empirically that our approach systematically beats the baselines, requiring only 53% of samples used by Farquhar et al. (2024) to achieve the same quality of hallucination detection as measured by AUROC. Moreover, quite counterintuitively, our estimator is useful even with just one sample from the LLM.

Generalization of machine learning models can be severely compromised by data poisoning, where adversarial changes are applied to the training data. This vulnerability has led to interest in certifying (i.e., proving) that such changes up to a certain magnitude do not affect test predictions. We, for the first time, certify Graph Neural Networks (GNNs) against poisoning attacks, including backdoors, targeting the node features of a given graph. Our certificates are white-box and based upon $(i)$ the neural tangent kernel, which characterizes the training dynamics of sufficiently wide networks; and $(ii)$ a novel reformulation of the bilevel optimization problem describing poisoning as a mixed-integer linear program. Consequently, we leverage our framework to provide fundamental insights into the role of graph structure and its connectivity on the worst-case robustness behavior of convolution-based and PageRank-based GNNs. We note that our framework is more general and constitutes the first approach to derive white-box poisoning certificates for NNs, which can be of independent interest beyond graph-related tasks.
Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored. In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be obtained efficiently by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow. Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to handle by existing methods. The common color drifting issue that occurs in 4D generation is also resolved with improved Guassian dynamics. Superior visual quality in extensive experiments demonstrates the effectiveness of our method. As shown in our evaluation, GaussianFlow can drastically improve both quantitative and qualitative results for 4D generation and 4D novel view synthesis.
Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multiagent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. Finally, we identify emerging trends, such as domain-specific reasoning systems, and open challenges, such as evaluation and data quality. This survey aims to provide AI researchers and practitioners with a comprehensive foundation for advancing reasoning in LLMs, paving the way for more sophisticated and reliable AI systems.
In this paper, we design two compressed decentralized algorithms for solving nonconvex stochastic optimization under two different scenarios. Both algorithms adopt a momentum technique to achieve fast convergence and a message-compression technique to save communication costs. Though momentum acceleration and compressed communication have been used in literature, it is highly nontrivial to theoretically prove the effectiveness of their composition in a decentralized algorithm that can maintain the benefits of both sides, because of the need to simultaneously control the consensus error, the compression error, and the bias from the momentum gradient. For the scenario where gradients are bounded, our proposal is a compressed decentralized adaptive method. To the best of our knowledge, this is the first decentralized adaptive stochastic gradient method with compressed communication. For the scenario of data heterogeneity without bounded gradients, our proposal is a compressed decentralized heavy-ball method, which applies a gradient tracking technique to address the challenge of data heterogeneity. Notably, both methods achieve an optimal convergence rate, and they can achieve linear speed up and adopt topology-independent algorithmic parameters within a certain regime of the user-specified error tolerance. Superior empirical performance is observed over state-of-the-art methods on training deep neural networks (DNNs) and Transformers.
Time becomes visible through illumination changes in what we see. Inspired by this, in this paper we explore the potential to learn time awareness from static images, trying to answer: *what time tells us?* To this end, we first introduce a Time-Oriented Collection (TOC) dataset, which contains 130,906 images with reliable timestamps. Leveraging this dataset, we propose a Time-Image Contrastive Learning (TICL) approach to jointly model timestamps and related visual representations through cross-modal contrastive learning. We found that the proposed TICL, 1) not only achieves state-of-the-art performance on the timestamp estimation task, over various benchmark metrics, 2) but also, interestingly, though only seeing static images, the time-aware embeddings learned from TICL show strong capability in several time-aware downstream tasks such as time-based image retrieval, video scene classification, and time-aware image editing. Our findings suggest that time-related visual cues can be learned from static images and are beneficial for various vision tasks, laying a foundation for future research on understanding time-related visual context. Project page: https://rathgrith.github.io/timetells_release/

The reasoning abilities of Large Language Models (LLMs) remain a topic of considerable interest and debate. Among the original papers arguing for emergent reasoning abilities of LLMs, ReAct became particularly popular by claiming to tease out LLM reasoning abilities with special prompting involving “interleaving reasoning trace with action execution". In this paper, we critically examine the claims of ReAct style prompting for planning and sequential decision-making problems. By introducing systematic variations to the input prompt, we perform a sensitivity analysis along the original claims of ReAct. Our experiments in AlfWorld and WebShop, domains that were used in the original ReAct work, show that the performance is minimally influenced by the interleaved reasoning trace or by the content of these generated reasoning traces. Instead, the performance of LLMs is primarily driven by the unreasonably high degree of similarity between input example tasks and queries, with shockingly little ability to generalize. In addition to raising questions on claims about reasoning abilities, this lack of generalization also implicitly forces the prompt designer to provide instance-specific examples, significantly increasing the cognitive burden on the human. Our empirical results show that the perceived reasoning abilities of LLMs stem from the exemplar-query similarity and approximate retrieval rather than any inherent reasoning abilities, thereby leading to severe lack of generalization beyond the few-shot examples given in the prompts. Our code and prompt settings can be found here on GitHub.
Representation Engineering (RepE) is a novel paradigm for controlling the behavior of LLMs. Unlike traditional approaches that modify inputs or fine-tune the model, RepE directly manipulates the model's internal representations. As a result, it may offer more effective, interpretable, data-efficient, and flexible control over models' behavior. We present the first comprehensive survey of RepE for LLMs, reviewing the rapidly growing literature to address key questions: What RepE methods exist and how do they differ? For what concepts and problems has RepE been applied? What are the strengths and weaknesses of RepE compared to other methods? To answer these, we propose a unified framework describing RepE as a pipeline comprising representation identification, operationalization, and control. We posit that while RepE methods offer significant potential, challenges remain, including managing multiple concepts, ensuring reliability, and preserving models' performance. Towards improving RepE, we identify opportunities for experimental and methodological improvements and construct a guide for best practices.
Graph Neural Networks (GNNs) are prominent in graph machine learning and have shown state-of-the-art performance in Link Prediction (LP) tasks. Nonetheless, recent studies show that GNNs struggle to produce good results on low-degree nodes despite their overall strong performance. In practical applications of LP, like recommendation systems, improving performance on low-degree nodes is critical, as it amounts to tackling the cold-start problem of improving the experiences of users with few observed interactions. In this paper, we investigate improving GNNs' LP performance on low-degree nodes while preserving their performance on high-degree nodes and propose a simple yet surprisingly effective augmentation technique called NodeDup. Specifically, NodeDup duplicates low-degree nodes and creates links between nodes and their own duplicates before following the standard supervised LP training scheme. By leveraging a ``multi-view'' perspective for low-degree nodes, NodeDup shows significant LP performance improvements on low-degree nodes without compromising any performance on high-degree nodes. Additionally, as a plug-and-play augmentation module, NodeDup can be easily applied on existing GNNs with very light computational cost. Extensive experiments show that NodeDup achieves 38.49%, 13.34%, and 6.76% relative improvements on isolated, low-degree, and warm nodes, respectively, on average across all datasets compared to GNNs and the existing cold-start methods.
In the knowledge distillation literature, feature-based methods have dominated due to their ability to effectively tap into extensive teacher models. In contrast, logit-based approaches, which aim to distill `dark knowledge' from teachers, typically exhibit inferior performance compared to feature-based methods. To bridge this gap, we present LumiNet, a novel knowledge distillation algorithm designed to enhance logit-based distillation. We introduce the concept of `perception', aiming to calibrate logits based on the model's representation capability. This concept addresses overconfidence issues in the logit-based distillation method while also introducing a novel method to distill knowledge from the teacher. It reconstructs the logits of a sample/instances by considering relationships with other samples in the batch. LumiNet excels on benchmarks like CIFAR-100, ImageNet, and MSCOCO, outperforming the leading feature-based methods, e.g., compared to KD with ResNet18 and MobileNetV2 on ImageNet, it shows improvements of 1.5\% and 2.05\%, respectively.

Training neural networks with high certified accuracy against adversarial examples remains an open challenge despite significant efforts. While certification methods can effectively leverage tight convex relaxations for bound computation, in training, these methods, perhaps surprisingly, can perform worse than looser relaxations. Prior work hypothesized that this phenomenon is caused by the discontinuity, non-smoothness, and perturbation sensitivity of the loss surface induced by tighter relaxations. In this work, we theoretically show that Gaussian Loss Smoothing (GLS) can alleviate these issues. We confirm this empirically by instantiating GLS with two variants: a zeroth-order optimization algorithm, called PGPE, which allows training with non-differentiable relaxations, and a first-order optimization algorithm, called RGS, which requires gradients of the relaxation but is much more efficient than PGPE. Extensive experiments show that when combined with tight relaxations, these methods surpass state-of-the-art methods when training on the same network architecture for many settings. Our results clearly demonstrate the promise of Gaussian Loss Smoothing for training certifiably robust neural networks and pave a path towards leveraging tighter relaxations for certified training.

Challenges remain in providing interpretable explanations for neural network decision-making in explainable AI (xAI). Existing methods like Integrated Gradients produce noisy maps, and LIME, while intuitive, may deviate from the model’s internal logic. We introduce a framework that uses hierarchical segmentation techniques for faithful and interpretable explanations of Convolutional Neural Networks (CNNs). Our method constructs model-based hierarchical segmentations that maintain fidelity to the model’s decision-making process and allow both human-centric and model-centric segmentation. This approach can be combined with various xAI methods and provides multiscale explanations that help identify biases and improve understanding of neural network predictive behavior. Experiments show that our framework, xAiTrees, delivers highly interpretable and faithful model explanations, not only surpassing traditional xAI methods but shedding new light on a novel approach to enhancing xAI interpretability.

Intelligent embodied agents (e.g. robots) need to perform complex semantic tasks in unfamiliar environments. Among many skills that the agents need to possess, building and maintaining a semantic map of the environment is most crucial in long-horizon tasks. A semantic map captures information about the environment in a structured way, allowing the agent to reference it for advanced reasoning throughout the task. While existing surveys in embodied AI focus on general advancements or specific tasks like navigation and manipulation, this paper provides a comprehensive review of semantic map-building approaches in embodied AI, specifically for indoor navigation. We categorize these approaches based on their structural representation (spatial grids, topological graphs, dense point-clouds or hybrid maps) and the type of information they encode (implicit features or explicit environmental data). We also explore the strengths and limitations of the map building techniques, highlight current challenges, and propose future research directions. We identify that the field is moving towards developing open-vocabulary, queryable, task-agnostic map representations, while high memory demands and computational inefficiency still remaining to be open challenges. This survey aims to guide current and future researchers in advancing semantic mapping techniques for embodied AI systems.

Considerable efforts have been dedicated to exploring methods that enhance the expressiveness of graph neural networks. Current endeavors primarily focus on modifying the message-passing process to overcome limitations imposed by the Weisfeiler-Leman test, often at the expense of increasing computational cost. In practical applications, message-passing layers are interleaved with pooling layers for graph-level tasks, enabling the learning of increasingly abstract and coarser representations of input graphs. In this work, we formally prove two directions that allow pooling methods to increase the expressive power of a graph neural network while keeping the message-passing method unchanged. We systemically assign eight frequently used pooling operators to our theoretical conditions for increasing expressivity and introduce a novel pooling method XP, short for eXpressive Pooling, as an additional simple method that satisfies our theoretical conditions. Experiments conducted on the Brec dataset confirm that those pooling methods that satisfy our conditions empirically increase the expressivity of graph neural networks.
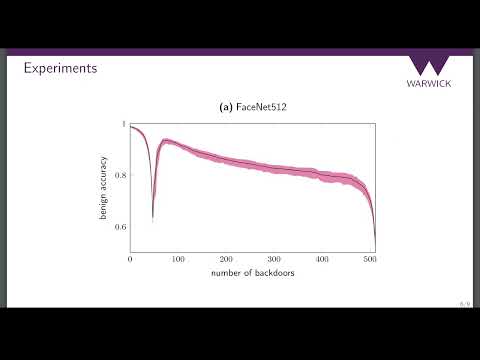
We show that several leading pretrained facial recognition systems exhibit a variance dichotomy in their feature space. In other words, the feature vectors approximately lie in a lower dimensional linear subspace. We demonstrate that this variance dichotomy degrades the performance of an otherwise powerful scheme for anonymity/unlinkability and confusion attacks on facial recognition system devised by Zehavi et al. (2024), which is based on simple weight manipulations in only the last hidden layer. Lastly, we propose a method for the attacker to overcome this intrinsic defense of these pretrained facial recognition systems.

Federated Learning (FL) has emerged as the state-of-the-art approach for learning from decentralized data in privacy-constrained scenarios. However, system and statistical challenges hinder its real-world applicability, requiring efficient learning from edge devices and robustness to data heterogeneity. Despite significant research efforts, existing approaches often degrade severely due to the joint effect of heterogeneity and partial client participation. In particular, while momentum appears as a promising approach for overcoming statistical heterogeneity, in current approaches its update is biased towards the most recently sampled clients. As we show in this work, this is the reason why it fails to outperform FedAvg, preventing its effective use in real-world large-scale scenarios. In this work, we propose a novel Generalized Heavy-Ball Momentum (GHBM) and theoretically prove it enables convergence under unbounded data heterogeneity in cyclic partial participation, thereby advancing the understanding of momentum's effectiveness in FL. We then introduce adaptive and communication-efficient variants of GHBM that match the communication complexity of FedAvg in settings where clients can be stateful. Extensive experiments on vision and language tasks confirm our theoretical findings, demonstrating that GHBM substantially improves state-of-the-art performance under random uniform client sampling, particularly in large-scale settings with high data heterogeneity and low client participation.

Optical flow estimation is a crucial computer vision task often applied to safety-critical real-world scenarios like autonomous driving and medical imaging. While optical flow estimation accuracy has greatly benefited from the emergence of deep learning, learning-based methods are also known for their lack of generalization and reliability. However, reliability is paramount when optical flow methods are employed in the real world, where safety is essential. Furthermore, a deeper understanding of the robustness and reliability of learning-based optical flow estimation methods is still lacking, hindering the research community from building methods safe for real-world deployment. Thus, we propose FlowBench, a robustness benchmark and evaluation tool for learning-based optical flow methods. FlowBench facilitates streamlined research into the reliability of optical flow methods by benchmarking their robustness to adversarial attacks and out-of-distribution samples. With FlowBench, we benchmark 57 checkpoints across 3 datasets under 9 diverse adversarial attacks and 23 established common corruptions, making it the most comprehensive robustness analysis of optical flow methods to date. Across this wide range of methods, we consistently find that methods with state-of-the-art performance on established standard benchmarks lack reliability and generalization ability. Moreover, we find interesting correlations between the performance, reliability, and generalization ability of optical flow estimation methods, under various lenses such as design choices used, number of parameters, etc. The open-source code and weights for FlowBench are available in this GitHub repository: https://github.com/shashankskagnihotri/FlowBench.

Recent innovations in architecture, pre-training, and fine-tuning have led to the remarkable in-context learning and reasoning abilities of large auto-regressive language models such as LLaMA and DeepSeek. In contrast, encoders like BERT and RoBERTa have not seen the same level of progress despite being foundational for many downstream NLP applications. To bridge this gap, we introduce NeoBERT, a next-generation encoder that redefines the capabilities of bidirectional models by integrating state-of-the-art advancements in architecture, modern data, and optimized pre-training methodologies. NeoBERT is designed for seamless adoption: it serves as a plug-and-play replacement for existing base models, relies on an optimal depth-to-width ratio, and leverages an extended context length of 4,096 tokens. Despite its compact 250M parameter footprint, it achieves state-of-the-art results on the massive MTEB benchmark, outperforming BERT$_{large}$, RoBERTa$_{large}$, NomicBERT, and ModernBERT under identical fine-tuning conditions. In addition, we rigorously evaluate the impact of each modification on GLUE and design a uniform fine-tuning and evaluation framework for MTEB. We release all code, data, checkpoints, and training scripts to accelerate research and real-world adoption.

We present a reproduction study of "Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals" (Ortu et al., 2024), which investigates competition of mechanisms in language models between factual recall and counterfactual in-context repetition. Our study successfully reproduces their primary findings regarding the localization of factual and counterfactual information, the dominance of attention blocks in mechanism competition, and the specialization of attention heads in handling competing information. We reproduce their results on both GPT-2 (Radford et al., 2019) and Pythia 6.9B (Biderman et al., 2023). We extend their work in three significant directions. First, we explore the generalizability of these findings to even larger models by replicating the experiments on Llama 3.1 8B (Grattafiori et al., 2024), discovering greatly reduced attention head specialization. Second, we investigate the impact of prompt structure by introducing variations where we avoid repeating the counterfactual statement verbatim or we change the premise word, observing a marked decrease in the logit for the counterfactual token. Finally, we test the validity of the authors’ claims for prompts of specific domains, discovering that certain categories of prompts skew the results by providing the factual prediction token as part of the subject of the sentence. Overall, we find that the attention head ablation proposed in Ortu et al. (2024) is ineffective for domains that are underrepresented in their dataset, and that the effectiveness varies based on model architecture, prompt structure, domain and task.

Recommendation systems are necessary to filter the abundance of information presented in our everyday lives. A recommendation system could exclusively recommend items that users prefer the most, potentially resulting in certain items never getting recommended. Conversely, an exclusive focus on including all items could hurt overall recommendation quality. This gives rise to the challenge of balancing user and item fairness. The paper “User-item fairness tradeoffs in recommendations” by Greenwood et al. (2024) explores this tradeoff by developing a theoretical framework that optimizes for user-item fairness constraints. Their theoretical framework suggests that the cost of item fairness is low when users have varying preferences compared to each other, and may be high for users whose preferences are misestimated. They empirically measured these phenomena by creating their own recommendation system on arXiv preprints, and confirmed that the cost of item fairness is low when users have preferences that differ from one another. However, contrary to their theoretical expectations, misestimated users do not encounter a higher cost of item fairness. This study investigates the reproducibility of their research by replicating the empirical study. Additionally, we extend their research in two ways: (i) verifying the generalizability of their findings on a different dataset (Amazon books reviews), and (ii) analyzing the tradeoffs when recommending multiple items to a user instead of a single item. Our results further validate the claims made in the original paper. We concluded the claims hold true when recommending multiple items, with the cost of item fairness decreasing as more items are recommended.
This paper studies the unsupervised change point detection problem in time series of networks using the Separable Temporal Exponential-family Random Graph Model (STERGM). Inherently, dynamic network patterns are complex due to dyadic and temporal dependence, and change points detection can identify the discrepancies in the underlying data generating processes to facilitate downstream analysis. In particular, the STERGM that utilizes network statistics and nodal attributes to represent the structural patterns is a flexible and parsimonious model to fit dynamic networks. We propose a new estimator derived from the Alternating Direction Method of Multipliers (ADMM) procedure and Group Fused Lasso (GFL) regularization to simultaneously detect multiple time points where the parameters of a time-heterogeneous STERGM have shifted. Experiments on both simulated and real data show good performance of the proposed framework, and an R package CPDstergm is developed to implement the method.

Spectral clustering is a widely used algorithm to find clusters in networks. Several researchers have studied the stability of spectral clustering under local differential privacy with the additional assumption that the underlying networks are generated from the stochastic block model (SBM). However, we argue that this assumption is too restrictive since social networks do not originate from the SBM. Thus, we delve into an analysis for general graphs in this work. Our primary focus is the edge flipping method -- a common technique for protecting local differential privacy. We show that, when the edges of an $n$-vertex graph satisfying some reasonable well-clustering assumptions are flipped with a probability of $O(\log n/n)$, the clustering outcomes are largely consistent. Empirical tests further corroborate these theoretical findings. Conversely, although clustering outcomes have been stable for non-sparse and well-clustered graphs produced from the SBM, we show that in general, spectral clustering may yield highly erratic results on certain graphs when the flipping probability is $\omega(\log n/n)$. This indicates that the best privacy budget obtainable for general graphs is $\Theta(\log n)$.
We introduce MarDini, a new family of video diffusion models that integrate the advantages of masked auto-regression (MAR) into a unified diffusion model (DM) framework. Here, MAR handles temporal planning, while DM focuses on spatial generation in an asymmetric network design: i) a MAR-based planning model containing most of the parameters generates planning signals for each masked frame using low-resolution input; ii) a lightweight generation model uses these signals to produce high-resolution frames via diffusion de-noising. MarDini’s MAR enables video generation conditioned on any number of masked frames at any frame positions: a single model can handle video interpolation (e.g., masking middle frames), image-to-video generation (e.g., masking from the second frame onward), and video expansion (e.g., masking half the frames). The efficient design allocates most of the computational resources to the low-resolution planning model, making computationally expensive but important spatio-temporal attention feasible at scale. MarDini sets a new state-of-the-art for video interpolation; meanwhile, within few inference steps, it efficiently generates videos on par with those of much more expensive advanced image-to-video models.
Large Language Models (LLMs) have been observed to perform well on a wide range of downstream tasks when fine-tuned on domain-specific data. However, such data may not be readily available in many applications, motivating zero-shot or few-shot approaches using existing domain or task adjacent (fine-tuned) models, which we call DAFT. While several fine-tuned models for various tasks are available, finding one appropriate DAFT model for a given task is often not straight forward. In this paper, we explore different utilization techniques of these existing DAFT models for data-scarce problems, i.e., tasks for which data is not available or limited. We observe that for zero-shot problems, ensembling of DAFT models provides an accuracy performance close to that of the single best model. With few-shot problems (few data from target domain available), this performance can be improved further by picking or putting more weights to the DAFT models that are expected to perform better on the target task.

In this paper, we propose a novel method for learning reward functions directly from offline demonstrations. Unlike traditional inverse reinforcement learning (IRL), our approach decouples the reward function from the learner's policy, eliminating the adversarial interaction typically required between the two. This results in a more stable and efficient training process. Our reward module, \textit{SR-Reward}, leverages successor representation (SR) to encode a state based on expected future states' visitation under the demonstration policy and transition dynamics. By utilizing the Bellman equation, SR-Reward can be learned concurrently with most reinforcement learning (RL) algorithms without altering the existing training pipeline. We also introduce a negative sampling strategy to mitigate overestimation errors by reducing rewards for out-of-distribution data, thereby enhancing robustness. This strategy introduces an inherent conservative bias into RL algorithms that employ the learned reward, encouraging them to stay close to the demonstrations where the consequences of the actions are better understood. We evaluate our method on D4RL as well as Maniskill Robot Manipulation environments, achieving competitive results compared to offline RL algorithms with access to true rewards and imitation learning (IL) techniques like behavioral cloning.

The rising successes of RL are propelled by combining smart algorithmic strategies and deep architectures to optimize the distribution of returns and visitations over the state-action space. A quantitative framework to compare the learning processes of these eclectic RL algorithms is currently absent but desired in practice. We address this gap by representing the learning process of an RL algorithm as a sequence of policies generated during training, and then studying the policy trajectory induced in the manifold of state-action occupancy measures. Using an optimal transport-based metric, we measure the length of the paths induced by the policy sequence yielded by an RL algorithm between an initial policy and a final optimal policy. Hence, we first define the Effort of Sequential Learning (ESL). ESL quantifies the relative distance that an RL algorithm travels compared to the shortest path from the initial to the optimal policy. Furthermore, we connect the dynamics of policies in the occupancy measure space and regret (another metric to understand the suboptimality of an RL algorithm), by defining the Optimal Movement Ratio (OMR). OMR assesses the fraction of movements in the occupancy measure space that effectively reduce an analogue of regret. Finally, we derive approximation guarantees to estimate ESL and OMR with a finite number of samples and without access to an optimal policy. Through empirical analyses across various environments and algorithms, we demonstrate that ESL and OMR provide insights into the exploration processes of RL algorithms and the hardness of different tasks in discrete and continuous MDPs.
This paper is concerned with the online bandit nonlinear control, which aims to learn the best stabilizing controller from a pool of stabilizing and destabilizing controllers of unknown types for a given nonlinear dynamical system. We develop an algorithm, named Dynamic Batch length and Adaptive learning Rate (DBAR), and study its stability and regret. Unlike the existing Exp3 algorithm requiring an exponentially stabilizing controller, DBAR only needs a significantly weaker notion of controller stability, in which case substantial time may be required to certify the system stability. Dynamic batch length in DBAR effectively addresses this issue and enables the system to attain asymptotic stability, where the algorithm behaves as if there were no destabilizing controllers. Moreover, adaptive learning rate in DBAR only uses the state norm information to achieve a tight regret bound even when none of the stabilizing controllers in the pool are exponentially stabilizing.

Pretraining and finetuning models has become increasingly popular in decision-making. But there are still serious impediments in Imitation Learning from Observation (ILfO) with pretrained models. This study identifies two primary obstacles: the Embodiment Knowledge Barrier (EKB) and the Demonstration Knowledge Barrier (DKB). The EKB emerges due to the pretrained models' limitations in handling novel observations, which leads to inaccurate action inference. Conversely, the DKB stems from the reliance on limited demonstration datasets, restricting the model's adaptability across diverse scenarios. We propose separate solutions to overcome each barrier and apply them to Action Inference by Maximising Evidence (AIME), a state-of-the-art algorithm. This new algorithm, AIME-NoB, integrates online interactions and a data-driven regulariser to mitigate the EKB. Additionally, it uses a surrogate reward function to broaden the policy's supported states, addressing the DKB. Our experiments on vision-based control tasks from the DeepMind Control Suite and MetaWorld benchmarks show that AIME-NoB significantly improves sample efficiency and converged performance, presenting a robust framework for overcoming the challenges in ILfO with pretrained models. Code available at https://github.com/IcarusWizard/AIME-NoB.
Graph Neural Networks (GNNs) often suffer from performance degradation as the network depth increases. This paper addresses this issue by introducing initialization methods that enhance signal propagation (SP) within GNNs. We propose three key metrics for effective SP in GNNs: forward propagation, backward propagation, and graph embedding variation (GEV). While the first two metrics derive from classical SP theory, the third is specifically designed for GNNs. We theoretically demonstrate that a broad range of commonly used initialization methods for GNNs, which exhibit performance degradation with increasing depth, fail to control these three metrics simultaneously. To deal with this limitation, a direct exploitation of the SP analysis--searching for weight initialization variances that optimize the three metrics--is shown to significantly enhance the SP in deep GCNs. This approach is called \textit{\textbf{S}ignal \textbf{P}ropagation \textbf{o}n \textbf{G}raph-guided \textbf{Init}ialization (\textbf{SPoGInit})}. Our experiments demonstrate that SPoGInit outperforms commonly used initialization methods on various tasks and architectures. Notably, SPoGInit enables performance improvements as GNNs deepen, which represents a significant advancement in addressing depth-related challenges and highlights the validity and effectiveness of the SP analysis framework.

This manuscript studies the unsupervised change point detection problem in time series of graphs using a decoder-only latent space model. The proposed framework consists of learnable prior distributions for low-dimensional graph representations and of a decoder that bridges the observed graphs and latent representations. The prior distributions of the latent spaces are learned from the observed data as empirical Bayes to assist change point detection. Specifically, the model parameters are estimated via maximum approximate likelihood, with a Group Fused Lasso regularization imposed on the prior parameters. The augmented Lagrangian is solved via Alternating Direction Method of Multipliers, and Langevin Dynamics are recruited for posterior inference. Simulation studies show good performance of the latent space model in supporting change point detection and real data experiments yield change points that align with significant events.

Concept-based models like Concept Bottleneck Models (CBMs) have garnered significant interest for improving model interpretability by first predicting human-understandable concepts before mapping them to the output classes. Early approaches required costly concept annotations. To alleviate this, recent methods utilized large language models to automatically generate class-specific concept descriptions and learned mappings from a pretrained black-box model’s raw features to these concepts using vision-language models. However, these approaches assume prior knowledge of which concepts the black-box model has learned. In this work, we discover the concepts encoded by the model through unsupervised concept discovery techniques instead. We further leverage a simple input-dependent concept selection mechanism that dynamically retains a sparse set of relevant concepts of each input, enhancing both sparsity and interpretability. Our approach not only improves downstream performance, but also needs significantly fewer concepts for accurate classification. Lastly, we show how large vision-language models can guide the editing of our models' weights to correct model errors.
One of the most common approaches for self-supervised representation learning is defining pre-text tasks to learn data representations. Existing works determine pre-text tasks in a "task-agnostic'' way, without considering the forthcoming downstream tasks. This offers an advantage of broad applicability across tasks, but can also lead to a mismatch between task objectives, potentially degrading performance on downstream tasks. In this paper, we introduce TST-LLM, a framework that effectively reduces this mismatch when the natural language-based description of the downstream task is given without any ground-truth labels. TST-LLM instructs the LLM to use the downstream task's description and meta-information of data to discover features relevant to the target task. These discovered features are then treated as ground-truth labels to define "target-specific'' pre-text tasks. TST-LLM consistently outperforms contemporary baselines, such as STUNT and LFR, with win ratios of 95% and 81%, when applied to 22 benchmark tabular datasets, including binary and multi-class classification, and regression tasks.

We consider a variant of the stochastic gradient descent (SGD) with a random learning rate and reveal its convergence properties. SGD is a widely used stochastic optimization algorithm in machine learning, especially deep learning. Numerous studies reveal the convergence properties of SGD and its theoretically favorable variants. Among these, the analysis of convergence using a stationary distribution of updated parameters provides generalizable results. However, to obtain a stationary distribution, the update direction of the parameters must not degenerate, which limits the applicable variants of SGD. In this study, we consider a novel SGD variant, Poisson SGD, which has degenerated parameter update directions and instead utilizes a random learning rate. Consequently, we demonstrate that a distribution of a parameter updated by Poisson SGD converges to a stationary distribution under weak assumptions on a loss function. Based on this, we further show that Poisson SGD finds global minima in non-convex optimization problems and also evaluate the generalization error using this method. As a proof technique, we approximate the distribution by Poisson SGD with that of the bouncy particle sampler (BPS) and derive its stationary distribution, using the theoretical advance of the piece-wise deterministic Markov process (PDMP).
Anomaly/Outlier detection (AD/OD) is often used in controversial applications to detect unusual behavior which is then further investigated or policed. This means an explanation of why something was predicted as an anomaly is desirable not only for individuals but also for the general population and policy-makers. However, existing explainable AI (XAI) methods are not well suited for Explainable Anomaly detection (XAD). In particular, most XAI methods provide instance-level explanations, whereas a model/global-level explanation is desirable for a complete understanding of the definition of normality or abnormality used by an AD algorithm. Further, existing XAI methods try to explain an algorithm’s behavior by finding an explanation of why an instance belongs to a category. However, by definition, anomalies/outliers are chosen because they are different from the normal instances. We propose a new style of model agnostic explanation, called contrastive explanation, that is designed specifically for AD algorithms. It addresses the novel challenge of providing a model-agnostic and global-level explanation by finding contrasts between the outlier group of instances and the normal group. We propose three formulations: (i) Contrastive Explanation, (ii) Strongly Contrastive Explanation, and (iii) Multiple Strong Contrastive Explanations. The last formulation is specifically for the case where a given dataset is believed to have many types of anomalies. For the first two formulations, we show the underlying problem is in the computational class P by presenting linear and polynomial time exact algorithms. We show that the last formulation is computationally intractable, and we use an integer linear program for that version to generate experimental results. We demonstrate our work on several data sets such as the CelebA image data set, the HateXplain language data set, and the COMPAS dataset on fairness. These data sets are chosen as their ground truth explanations are clear or well-known.
Controllable video generation has attracted significant attention, largely due to advances in video diffusion models. In domains such as autonomous driving, developing highly accurate predictions for object motions is essential. This paper addresses the key challenge of enabling fine-grained control over object motion in the context of driving video synthesis. To accomplish this, we 1) employ a distinct, specialized model to forecast the trajectories of object bounding boxes, 2) adapt and enhance a separate video diffusion network to create video content conditioned on these high-quality trajectory forecasts, and 3) we are able to exert precise control over object position/movements using bounding boxes in both 2D and 3D spaces. Our method, Ctrl-V, leverages modified and fine-tuned Stable Video Diffusion (SVD) models to solve both trajectory and video generation. Extensive experiments conducted on the KITTI, Virtual-KITTI 2, BDD100k, and nuScenes datasets validate the effectiveness of our approach in producing realistic and controllable video generation. Project page: \url{https://oooolga.github.io/ctrl-v.github.io/}

Recent studies have demonstrated that modern facial recognition systems, which are based on deep neural networks, are vulnerable to adversarial attacks, including the use of accessories, makeup patterns, or precision lighting. However, developing attacks that are both robust (resilient to changes in viewing angles and environmental conditions) and stealthy (do not attract suspicion by, for example, incorporating obvious facial features) remains a significant challenge. In this context, we introduce a novel diffusion-based method (DAFR) capable of generating robust and stealthy face masks for dodging recognition systems (where the system fails to identify the attacker). Specifically our approach is capable of producing high-fidelity printable textures using the guidance of textual prompts to determine the style. This method can also be adapted for impersonation purposes, where the system misidentifies the attacker as a specific other individual. Finally, we address a gap in the existing literature by presenting a comprehensive benchmark (FAAB) for evaluating adversarial accessories in three dimensions, assessing their robustness and stealthiness.
Learning a nonparametric system of ordinary differential equations from trajectories in a $d$-dimensional state space requires learning $d$ functions of $d$ variables. Explicit formulations often scale quadratically in $d$ unless additional knowledge about system properties, such as sparsity and symmetries, is available. In this work, we propose a linear approach, the multivariate occupation kernel method (MOCK), using the implicit formulation provided by vector-valued reproducing kernel Hilbert spaces. The solution for the vector field relies on multivariate occupation kernel functions associated with the trajectories and scales linearly with the dimension of the state space. We validate through experiments on a variety of simulated and real datasets ranging from 2 to 1024 dimensions, and provide an example with a divergence-free vector field. MOCK outperforms all other comparators on 3 of the 9 datasets on full trajectory prediction and 4 out of the 9 datasets on next-point prediction.

Recently, it has been observed that when training a deep neural net with SGD, the majority of the loss landscape's curvature quickly concentrates in a tiny *top* eigenspace of the loss Hessian, which remains largely stable thereafter. Independently, it has been shown that successful magnitude pruning masks for deep neural nets emerge early in training and remain stable thereafter. In this work, we study these two phenomena jointly and show that they are connected: We develop a methodology to measure the similarity between arbitrary parameter masks and Hessian eigenspaces via Grassmannian metrics. We identify *overlap* as the most useful such metric due to its interpretability and stability. To compute *overlap*, we develop a matrix-free algorithm based on sketched SVDs that allows us to compute over 1000 Hessian eigenpairs for nets with over 10M parameters --an unprecedented scale by several orders of magnitude. Our experiments reveal an *overlap* between magnitude parameter masks and top Hessian eigenspaces consistently higher than chance-level, and that this effect gets accentuated for larger network sizes. This result indicates that *top Hessian eigenvectors tend to be concentrated around larger parameters*, or equivalently, that *larger parameters tend to align with directions of larger loss curvature*. Our work provides a methodology to approximate and analyze deep learning Hessians at scale, as well as a novel insight on the structure of their eigenspace
Graph Neural Networks (GNNs) combine node attributes over a fixed granularity of the local graph structure around a node to predict its label. However, different nodes may relate to a node-level property with a different granularity of its local neighborhood, and using the same level of smoothing for all nodes can be detrimental to their classification. In this work, we challenge the common fact that a single GNN layer can classify all nodes of a graph by training GNNs with a distinct personalized layer for each node. Inspired by metric learning, we propose a novel algorithm, MetSelect, to select the optimal representation layer to classify each node. In particular, we identify a prototype representation of each class in a transformed GNN layer and then, classify using the layer where the distance is smallest to a class prototype after normalizing with that layer’s variance. Results on 10 datasets and 3 different GNNs show that we significantly improve the node classification accuracy of GNNs in a plug-and-play manner. We also find that using variable layers for prediction enables GNNs to be deeper and more robust to poisoning attacks. We hope this work can inspire future works to learn more adaptive and personalized graph representations.
As AI systems increasingly influence decision-making from consumer recommendations to educational opportunities, their accountability becomes paramount. This need for oversight has driven extensive research into algorithmic fairness, a body of work that has examined both allocative and representational harms. However, numerous works examining representational harms such as stereotypes encompass many different concepts measured by different criteria, yielding many, potentially conflicting, characterizations of harm. The abundance of measurement approaches makes the mitigation of stereotypes in downstream machine learning models highly challenging. Our work introduces and unifies a broad class of auditors through the framework of \textit{stereotype predictors}. We map notions of fairness with respect to these predictors to existing notions of group fairness. We give guidance, with theoretical foundations, for selecting one or a set of stereotype predictors and provide algorithms for achieving fairness with respect to stereotype predictors under various fairness notions. We demonstrate the effectiveness of our algorithms with different stereotype predictors in two empirical case studies.
Graph Neural Network (GNN) research is rapidly advancing due to GNNs’ capacity to learn distributed representations from graph-structured data. However, centralizing large volumes of real-world graph data for GNN training is often impractical due to privacy concerns, regulatory restrictions, and commercial competition. Federated learning (FL), a distributed learning paradigm, offers a solution by preserving data privacy with collaborative model training. Despite progress in training huge vision and language models, federated learning for GNNs remains underexplored. To address this challenge, we present a novel method for federated learning on GNNs based on spectral GNNs equipped with neural ordinary differential equations (ODE) for better information capture, showing promising results across both homophilic and heterophilic graphs. Our approach effectively handles non-Independent and Identically Distributed (non-IID) data, while also achieving performance comparable to existing methods that only operate on IID data. It is designed to be privacy-preserving and bandwidth-optimized, making it suitable for real-world applications such as social network analysis, recommendation systems, and fraud detection, which often involve complex, non-IID, and heterophilic graph structures. Our results in the area of federated learning on non-IID heterophilic graphs demonstrate significant improvements, while also achieving better performance on homophilic graphs. This work highlights the potential of federated learning in diverse and challenging graph settings.

Back-propagation is a widely used algorithm for training neural networks by adjusting weights based on error gradients. However, back-propagation is biologically implausible with global derivative computation and lacks robustness in long-term dynamic learning. A previously proposed alternative to back-propagation is the Forward-Forward algorithm, which bypasses global gradient dependency and localises computations, making it a more biologically plausible approach. However, Forward-Forward has been evaluated in limited environments, does not yet match back-propagation's performance, and only supports classification, not regression. This research introduces the Metamorphic Forward Adaptation Network (MFAN), using a contrastive learning property as its core, and retaining the layer-wise architecture of the Forward-Forward algorithm. Compared to the Forward-Forward model being limited to discrete classification, MFAN can process discrete and continuous data, showing stability, adaptability, and the ability to handle evolving data. MFAN performs well in continuous data stream scenarios, demonstrating superior adaptability and robustness compared to back-propagation, particularly in tasks requiring dynamic, long-term learning.

Literature reviews are an essential component of scientific research, but they remain time-intensive and challenging to write, especially due to the recent influx of research papers. This paper explores the zero-shot abilities of recent Large Language Models (LLMs) in assisting with the writing of literature reviews based on an abstract. We decompose the task into two components: (1) Retrieving related works given a query abstract and (2) Writing a literature review based on the retrieved results. We analyze how effective LLMs are for both components. For retrieval, we introduce a novel two-step search strategy that first uses an LLM to extract meaningful keywords from the abstract of a paper and then retrieves potentially relevant papers by querying an external knowledge base. Additionally, we study a prompting-based re-ranking mechanism with attribution and show that re-ranking doubles the normalized recall compared to naive search methods while providing insights into the LLM’s decision-making process. In the generation phase, we propose a two-step approach that first outlines a plan for the review and then executes steps in the plan to generate the actual review. To evaluate different LLM-based literature review methods, we create test sets from arXiv papers using a protocol designed for rolling use with newly released LLMs to avoid test set contamination in zero-shot evaluations. We release this evaluation protocol to promote additional research and development in this regard. Our empirical results suggest that LLMs show promising potential for writing literature reviews when the task is decomposed into smaller components of retrieval and planning. Particularly, we find that combining keyword-based and document-embedding-based search improves precision and recall during retrieval by 10% and 30%, respectively, compared to using either of the methods in isolation. Further, we demonstrate that our planning-based approach achieves higher-quality reviews by minimizing hallucinated references in the generated review by 18-26% compared to existing simpler LLM-based generation methods. Our project page including a demonstration system and toolkit can be accessed here: https://litllm.github.io.

Motivated by the progress of large language models (LLMs), we introduce the framework of verbalized machine learning (VML). In contrast to conventional machine learning (ML) models that are typically optimized over a continuous parameter space, VML constrains the parameter space to be human-interpretable natural language. Such a constraint leads to a new perspective of function approximation, where an LLM with a text prompt can be viewed as a function parameterized by the text prompt. Guided by this perspective, we revisit classical ML problems, such as regression and classification, and find that these problems can be solved by an LLM-parameterized learner and optimizer. The major advantages of VML include (1) easy encoding of inductive bias: prior knowledge about the problem and hypothesis class can be encoded in natural language and fed into the LLM-parameterized learner; (2) automatic model class selection: the optimizer can automatically select a model class based on data and verbalized prior knowledge, and it can update the model class during training; and (3) interpretable learner updates: the LLM-parameterized optimizer can provide explanations for why an update is performed. We empirically verify the effectiveness of VML, and hope that VML can serve as a stepping stone to stronger interpretability.

We present a method to control a text-to-image generative model to produce training data useful for supervised learning. Unlike previous works that employ an open-loop approach via pre-defined prompts to generate new data using either a language model or human expertise, we develop an automated closed-loop system that involves two feedback mechanisms. The first mechanism uses feedback from a given supervised model to find adversarial prompts that result in generated images that maximize the model's loss and, consequently, expose its vulnerabilities. While these adversarial prompts generate training examples curated for improving the given model, they are not curated for a specific target distribution of interest, which can be inefficient. Therefore, we introduce the second feedback mechanism that can optionally guide the generation process towards a desirable target distribution. We call the method combining these two mechanisms Guided Adversarial Prompts. The proposed closed-loop system allows us to control the training data generation for a given model and target image distribution. We evaluate on different tasks, datasets, and architectures, with different types of distribution shifts (corruptions, spurious correlations, unseen domains) and illustrate the advantages of the proposed feedback mechanisms compared to open-loop approaches.

Applying learning-based approaches to long-horizon sequential decision-making tasks requires a human teacher to carefully craft reward functions or curate demonstrations to elicit desired behaviors. To simplify this, we first introduce an alternative form of task-specification, Illustrated Landmark Graph (ILG), that represents the task as a directed graph where each vertex corresponds to a region of the state space (a landmark), and each edge represents an easier to achieve sub-task. A landmark in the ILG is conveyed to the agent through a few illustrative examples grounded in the agent’s observation space. Second, we propose ILG-Learn, a human in the loop algorithm that interleaves planning over the ILG and sub-task policy learning. ILG-Learn adaptively plans through the ILG by relying on the human teacher’s feedback to estimate the success rates of learned policies. We conduct experiments on long-horizon block stacking and point maze navigation tasks, and find that our approach achieves considerably higher success rates (~ 50% improvement) compared to hierarchical reinforcement learning and imitation learning baselines. Additionally, we highlight how the flexibility of the ILG specification allows the agent to learn a sequence of sub-tasks that is better suited to its limited capabilities.

This study introduces the Lower Ricci Curvature (LRC), a novel, scalable, and scale-free discrete curvature designed to enhance community detection in networks. Addressing the computational challenges posed by existing curvature-based methods, LRC offers a streamlined approach with linear computational complexity, which makes it well suited for large-scale network analysis. We further develop an LRC-based preprocessing method that effectively augments popular community detection algorithms. Through applications on multiple real-world datasets, including the NCAA football league network, the DBLP collaboration network, the Amazon product co-purchasing network, and the YouTube social network, we demonstrate the efficacy of our method in significantly improving the performance of various community detection algorithms.

Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. This approach ensures the temporal consistency in the edited videos while maintaining high fidelity to the editing text prompt. We further propose a recursive and ensembled refinement by revisiting the denoising step and guidance scale used in video diffusion process with Video-3DGS. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (×1.9, ×4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.

Subsampling is commonly used to mitigate costs associated with data acquisition, such as time or energy requirements, motivating the development of algorithms for estimating the fully-sampled signal of interest $x$ from partially observed measurements $y$. In maximum- entropy sampling, one selects measurement locations that are expected to have the highest entropy, so as to minimize uncertainty about $x$. This approach relies on an accurate model of the posterior distribution over future measurements, given the measurements observed so far. Recently, diffusion models have been shown to produce high-quality posterior samples of high-dimensional signals using guided diffusion. In this work, we propose Active Diffusion Subsampling (ADS), a method for designing intelligent subsampling masks using guided dif- fusion in which the model tracks a distribution of beliefs over the true state of $x$ throughout the reverse diffusion process, progressively decreasing its uncertainty by actively choosing to acquire measurements with maximum expected entropy, ultimately producing the pos- terior distribution $p(x | y)$. ADS can be applied using pre-trained diffusion models for any subsampling rate, and does not require task-specific retraining – just the specification of a measurement model. Furthermore, the maximum entropy sampling policy employed by ADS is interpretable, enhancing transparency relative to existing methods using black-box policies. Experimentally, we show that through designing informative subsampling masks, ADS significantly improves reconstruction quality compared to fixed sampling strategies on the MNIST and CelebA datasets, as measured by standard image quality metrics, includ- ing PSNR, SSIM, and LPIPS. Furthermore, on the task of Magnetic Resonance Imaging acceleration, we find that ADS performs competitively with existing supervised methods in reconstruction quality while using a more interpretable acquisition scheme design procedure. Code is available at https://active-diffusion-subsampling.github.io/.

Natural language is often the easiest and most convenient modality for humans to specify tasks for robots. However, learning to ground language to behavior typically requires impractical amounts of diverse, language-annotated demonstrations collected on each target robot. In this work, we aim to separate the problem of what to accomplish from how to accomplish it, as the former can benefit from substantial amounts of external observation-only data, and only the latter depends on a specific robot embodiment. To this end, we propose Video-Language Critic, a reward model that can be trained on readily available cross-embodiment data using contrastive learning and a temporal ranking objective, and use it to score behavior traces from a separate actor. When trained on Open X-Embodiment data, our reward model enables 2x more sample-efficient policy training on Meta-World tasks than a sparse reward only, despite a significant domain gap. Using in-domain data but in a challenging task generalization setting on Meta-World, we further demonstrate more sample-efficient training than is possible with prior language-conditioned reward models that are either trained with binary classification, use static images, or do not leverage the temporal information present in video data.

Machine learning models deployed in open-world scenarios often encounter unfamiliar conditions and perform poorly in unanticipated situations. As AI systems advance and find application in safety-critical domains, effectively handling out-of-distribution (OOD) data is crucial to building open-world learning systems. In this work, we introduce ALOE, a novel active learning algorithm for open-world environments designed to enhance model adaptation by incorporating new OOD classes via a two-stage approach. First, diversity sampling selects a representative set of examples, followed by energy-based OOD detection to prioritize likely unknown classes for annotation. This strategy accelerates class discovery and learning, even under constrained annotation budgets. Evaluations on three long-tailed image classification benchmarks demonstrate that ALOE outperforms traditional active learning baselines, effectively expanding known categories while balancing annotation cost. Our findings reveal a crucial tradeoff between enhancing known-class performance and discovering new classes, setting the stage for future advancements in open-world machine learning.
Large language models are finetuned to refuse questions about hazardous knowledge, but these protections can often be bypassed. Unlearning methods aim at completely removing hazardous capabilities from models and make them inaccessible to adversaries. This work challenges the fundamental differences between unlearning and traditional safety post-training from an adversarial perspective. We demonstrate that existing jailbreak methods, previously reported as ineffective against unlearning, can be successful when applied carefully. Furthermore, we develop a variety of adaptive methods that recover most supposedly unlearned capabilities. For instance, we show that finetuning on 10 unrelated examples or removing specific directions in the activation space can recover most hazardous capabilities for models edited with RMU, a state-of-the-art unlearning method. Our findings challenge the robustness of current unlearning approaches and question their advantages over safety training.

ImageNet was famously created by querying several image search engines such as Flickr. What if we recreated ImageNet instead by searching the massive LAION dataset based on image captions alone? In this work, we carry out this counterfactual investigation. We find that the resulting ImageNet recreation, which we call LAIONet, looks distinctly unlike the original. Specifically, the intra-class similarity of images in the original ImageNet is dramatically higher than it is for LAIONet. Consequently, models trained on ImageNet perform significantly worse on LAIONet. We propose a rigorous explanation for the discrepancy in terms of a subtle, yet important, difference in two plausible causal data-generating processes for the respective datasets, that we support with systematic experimentation. In a nutshell, searching based on an image caption alone creates an information bottleneck that mitigates the selection bias otherwise present in image-based filtering. Our explanation formalizes a long-held intuition in the community that ImageNet images are stereotypical, unnatural, and overly simple representations of the class category. At the same time, it provides a simple and actionable takeaway for future dataset creation efforts.

Stochastic heavy ball momentum (SHB) is commonly used to train machine learning models, and often provides empirical improvements over stochastic gradient descent. By primarily focusing on strongly-convex quadratics, we aim to better understand the theoretical advantage of SHB and subsequently improve the method. For strongly-convex quadratics, Kidambi et al. (2018) show that SHB (with a mini-batch of size $1$) cannot attain accelerated convergence, and hence has no theoretical benefit over SGD. They conjecture that the practical gain of SHB is a by-product of using larger mini-batches. We first substantiate this claim by showing that SHB can attain an accelerated rate when the mini-batch size is larger than a threshold $b^*$ that depends on the condition number $\kappa$. Specifically, we prove that with the same step-size and momentum parameters as in the deterministic setting, SHB with a sufficiently large mini-batch size results in an $O\left(\exp(-\frac{T}{\sqrt{\kappa}}) + \sigma \right)$ convergence when measuring the distance to the optimal solution in the $\ell_2$ norm, where $T$ is the number of iterations and $\sigma^2$ is the variance in the stochastic gradients. We prove a lower-bound which demonstrates that a $\kappa$ dependence in $b^*$ is necessary. To ensure convergence to the minimizer, we design a noise-adaptive multi-stage algorithm that results in an $O\left(\exp\left(-\frac{T}{\sqrt{\kappa}}\right) + \frac{\sigma}{\sqrt{T}}\right)$ rate when measuring the distance to the optimal solution in the $\ell_2$ norm. We also consider the general smooth, strongly-convex setting and propose the first noise-adaptive SHB variant that converges to the minimizer at an $O(\exp(-\frac{T}{\kappa}) + \frac{\sigma^2}{T})$ rate when measuring the distance to the optimal solution in the squared $\ell_2$ norm. We empirically demonstrate the effectiveness of the proposed algorithms.

The aim in many sciences is to understand the mechanisms that underlie the observed distribution of variables, starting from a set of initial hypotheses. Causal discovery allows us to infer mechanisms as sets of cause and effect relationships in a generalized way---without necessarily tailoring to a specific domain. Causal discovery algorithms search over a structured hypothesis space, defined by the set of Directed Acyclic Graphs (DAG), to find the graph that best explains the data. For high-dimensional problems, however, this search becomes intractable and scalable algorithms for causal discovery are needed to bridge the gap. In this paper, we define a novel causal graph partition that allows for divide-and-conquer causal discovery with theoretical guarantees under the Maximal Ancestral Graph (MAG) class. We leverage the idea of a superstructure---a set of learned or existing candidate hypotheses---to partition the search space. We prove under certain assumptions that learning with a causal graph partition always yields the Markov Equivalence Class of the true causal graph. We show our algorithm achieves comparable accuracy and a faster time to solution for biologically-tuned synthetic networks and networks up to ${10^4}$ variables. This makes our method applicable to gene regulatory network inference and other domains with high-dimensional structured hypothesis spaces.

Despite considerable progress in image classification tasks, classification models seem unaffected by the images that significantly deviate from those that appear natural to human eyes. Specifically, while human perception can easily identify abnormal appearances or compositions in images, classification models overlook any alterations in the arrangement of object parts as long as they are present in any order, even if unnatural. Hence, this work exposes the vulnerability of having semantic and syntactic discrepancy in images (SSDI) in the form of corruptions that remove or shuffle image patches or present images in the form of puzzles. To address this vulnerability, we propose the concept of "image grammar", comprising "image semantics" and "image syntax". Image semantics pertains to the interpretation of parts or patches within an image, whereas image syntax refers to the arrangement of these parts to form a coherent object. We present a semi-supervised two-stage method for learning the image grammar of visual elements and environments solely from natural images. While the first stage learns the semantic meaning of individual object parts, the second stage learns how their relative arrangement constitutes an entire object. The efficacy of the proposed approach is then demonstrated by achieving SSDI detection rates ranging from 70% to 90% on corruptions generated from CelebA and SUN-RGBD datasets. Code is publicly available at: https://github.com/ChunTao1999/SSDI/.

Robust statistics aims to compute quantities to represent data where a fraction of it may be arbitrarily corrupted. The most essential statistic is the mean, and in recent years, there has been a flurry of theoretical advancement for efficiently estimating the mean in high dimensions on corrupted data. While several algorithms have been proposed that achieve near-optimal error, they all rely on large data size requirements as a function of dimension. In this paper, we perform an extensive experimentation over various mean estimation techniques where data size might not meet this requirement due to the high-dimensional setting. For data with inliers generated from a Gaussian with known covariance, we find experimentally that several robust mean estimation techniques can practically improve upon the sample mean, with the quantum entropy scaling approach from Dong \etal (NeurIPS 2019) performing consistently the best. However, this consistent improvement is conditioned on a couple of simple modifications to how the steps to prune outliers work in the high-dimension low-data setting, and when the inliers deviate significantly from Gaussianity. In fact, with these modifications, they are typically able to achieve roughly the same error as taking the sample mean of the uncorrupted inlier data, even with very low data size. In addition to controlled experiments on synthetic data, we also explore these methods on large language models, deep pretrained image models, and non-contextual word embedding models that do not necessarily have an inherent Gaussian distribution. Yet, in these settings, a mean point of a set of embedded objects is a desirable quantity to learn, and the data exhibits the high-dimension low-data setting studied in this paper. We show both the challenges of achieving this goal, and that our updated robust mean estimation methods can provide significant improvement over using just the sample mean. We additionally publish a library of Python implementations of robust mean estimation algorithms, allowing practitioners and researchers to apply these techniques and to perform further experimentation.

Supervised classification traditionally assumes that training and testing samples are drawn from the same underlying distribution. However, practical scenarios are often affected by distribution shifts, such as covariate and label shifts. Most existing techniques for correcting distribution shifts are based on a reweighted approach that weights training samples, assigning lower relevance to the samples that are unlikely at testing. However, these methods may achieve poor performance when the weights obtained take large values at certain training samples. In addition, in multi-source cases, existing methods do not exploit complementary information among sources, and equally combine sources for all instances. In this paper, we establish a unified learning framework for distribution shift adaptation. We present a double-weighting approach to deal with distribution shifts, considering weight functions associated with both training and testing samples. For the multi-source case, the presented methods assign source-dependent weights for training and testing samples, where weights are obtained jointly using information from all sources. We also present generalization bounds for the proposed methods that show a significant increase in the effective sample size compared with existing approaches. Empirically, the proposed methods achieve enhanced classification performance in both synthetic and empirical experiments.

Best-of-N (BoN) sampling with a reward model has been shown to be an effective strategy for aligning Large Language Models (LLMs) with human preferences at the time of decoding. BoN sampling is susceptible to a problem known as reward hacking. Since the reward model is an imperfect proxy for the true objective, an excessive focus on optimizing its value can lead to a compromise of its performance on the true objective. Previous work proposes Regularized BoN sampling (RBoN), a BoN sampling with regularization to the objective, and shows that it outperforms BoN sampling so that it mitigates reward hacking and empirically (Jinnai et al., 2024). However, Jinnai et al. (2024) introduce RBoN based on a heuristic and they lack the analysis of why such regularization strategy improves the performance of BoN sampling. The aim of this study is to analyze the effect of BoN sampling on regularization strategies. Using the regularization strategies corresponds to robust optimization, which maximizes the worst case over a set of possible perturbations in the proxy reward. Although the theoretical guarantees are not directly applicable to RBoN, RBoN corresponds to a practical implementation. This paper proposes an extension of the RBoN framework, called Stochastic RBoN sampling (SRBoN), which is a theoretically guaranteed approach to worst-case RBoN in proxy reward. We then perform an empirical evaluation using the AlpacaFarm and Anthropic’s hh-rlhf datasets to evaluate which factors of the regularization strategies contribute to the improvement of the true proxy reward. In addition, we also propose another simple RBoN method, the Sentence Length Regularized BoN, which has a better performance in the experiment as compared to the previous methods.

Sim2real, the transfer of control policies from simulation to the real world, is crucial for efficiently solving robotic tasks without the risks associated with real-world learning. However, discrepancies between simulated and real environments, especially due to unmodeled dynamics and latencies, significantly impact the performance of these transferred policies. In this paper, we address the challenges of sim2real transfer caused by latency and asynchronous dynamics in real-world robotic systems. Our approach involves developing a novel framework, REX (Robotic Environments with jaX), that uses a graph-based simulation model to incorporate latency effects while optimizing for parallelization on accelerator hardware. Our framework simulates the asynchronous, hierarchical nature of real-world systems, while simultaneously estimating system dynamics and delays from real-world data and implementing delay compensation strategies to minimize the sim2real gap. We validate our approach on two real-world systems, demonstrating its effectiveness in improving sim2real performance by accurately modeling both system dynamics and delays. Our results show that the proposed framework supports both accelerated simulation and real-time processing, making it valuable for robot learning.

Natural gradients have been widely studied from both theoretical and empirical perspectives, and it is commonly believed that natural gradients have advantages over standard (Euclidean) gradients in capturing the intrinsic geometric structure of the underlying function space and being invariant under reparameterization. However, for function optimization, a fundamental theoretical issue regarding the existence of natural gradients on the function space remains underexplored. We address this issue by providing a geometric perspective and mathematical framework for studying both natural gradient and standard gradient that is more complete than existing studies. The key tool that unifies natural gradient and standard gradient is a generalized form of the Neural Tangent Kernel (NTK), which we name the Generalized Tangent Kernel (GTK). Using a novel orthonormality property of GTK, we show that for a fixed parameterization, GTK determines a Riemannian metric on the entire function space which makes the standard gradient as “natural" as the natural gradient in capturing the intrinsic structure of the parameterized function space. Many aspects of this approach relate to RKHS theory. For the practical side of this theory paper, we showcase that our framework motivates new solutions to the non-immersion/degenerate case of natural gradient and leads to new families of natural/standard gradient descent methods.

With the increasing deployment of artificial intelligence (AI) technologies, the potential of humans working with AI agents has been growing at a great speed. Human-AI teaming is an important paradigm for studying various aspects when humans and AI agents work together. The unique aspect of Human-AI teaming research is the need to jointly study humans and AI agents, demanding multidisciplinary research efforts from machine learning to human-computer interaction, robotics, cognitive science, neuroscience, psychology, social science, and complex systems. However, existing platforms for Human-AI teaming research are limited, often supporting oversimplified scenarios and a single task, or specifically focusing on either human-teaming research or multi-agent AI algorithms. We introduce \textbf{CREW}, a platform to facilitate Human-AI teaming research in real-time decision-making scenarios and engage collaborations from multiple scientific disciplines, with a strong emphasis on human involvement. It includes pre-built tasks for cognitive studies and Human-AI teaming with expandable potentials from our modular design. Following conventional cognitive neuroscience research, CREW also supports multimodal human physiological signal recording for behavior analysis. Moreover, CREW benchmarks real-time human-guided reinforcement learning agents using state-of-the-art algorithms and well-tuned baselines. With CREW, we were able to conduct 50 human subject studies within a week to verify the effectiveness of our benchmark.

Models driven by spurious correlations often yield poor generalization performance. We propose the counterfactual (CF) alignment method to detect and quantify spurious correlations of black box classifiers. Our methodology is based on counterfactual images generated with respect to one classifier being input into other classifiers to see if they also induce changes in the outputs of these classifiers. The relationship between these responses can be quantified and used to identify specific instances where a spurious correlation exists. This is validated by observing intuitive trends in face-attribute and waterbird classifiers, as well as by fabricating spurious correlations and detecting their presence, both visually and quantitatively. Furthermore, utilizing the CF alignment method, we demonstrate that we can evaluate robust optimization methods (GroupDRO, JTT, and FLAC) by detecting a reduction in spurious correlations.

Systems characterized by evolving interactions, prevalent in social, financial, and biological domains, are effectively modeled as continuous-time dynamic graphs (CTDGs). To manage the scale and complexity of these graph datasets, machine learning (ML) approaches have become essential. However, CTDGs pose challenges for ML because traditional static graph methods fail to account for event timings naturally. Newer approaches, such as graph recurrent neural networks (GRNNs), are inherently time-aware and offer advantages over static methods for CTDGs. Yet, GRNNs face another issue: the short truncation of backpropagation-through-time (BPTT) whose impact has never been properly examined until now. In this work, we demonstrate that this truncation can limit the learning of dependencies more than a hop away, resulting in reduced performance. Through experiments on a novel synthetic task as well as real-world datasets, we reveal that there exists a performance gap between full backpropagation-through-time (F-BPTT) and the truncated backpropagation-through-time (T-BPTT) commonly used to train GRNN models. We term this gap the "truncation gap" and argue that understanding and addressing it is essential as the importance of CTDGs grows, discussing potential future directions of research for this type of models.

Concept-based explanations translate the internal representations of deep learning models into a language that humans are familiar with: concepts. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs: (1) inconsistency across layers, (2) entanglement with other concepts, and (3) spatial dependency. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how each property can lead to misleading explanations, and provide recommendations to mitigate their impact. To demonstrate practical applications, we apply our recommendations to a melanoma classification task, showing how entanglement can lead to uninterpretable results and that the choice of negative probe set can have a substantial impact on the meaning of a CAV. Further, we show that understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on natural images (ImageNet), skin lesions (ISIC 2019), and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.

AI agents have the potential to aid users on a variety of consequential tasks, including conducting scientific research. To spur the development of useful agents, we need benchmarks that are challenging, but more crucially, directly correspond to real-world tasks of interest. This paper introduces such a benchmark, designed to measure the accuracy of AI agents in tackling a crucial yet surprisingly challenging aspect of scientific research: computational reproducibility. This task, fundamental to the scientific process, involves reproducing the results of a study using the provided code and data. We introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark consisting of 270 tasks based on 90 scientific papers across three disciplines (computer science, social science, and medicine). Tasks in CORE-Bench consist of three difficulty levels and include both language-only and vision-language tasks. We provide an evaluation system to measure the accuracy of agents in a fast and parallelizable way, saving days of evaluation time for each run compared to a sequential implementation. We evaluated two baseline agents: the general-purpose AutoGPT and a task-specific agent called CORE-Agent. We tested both variants using two underlying language models: GPT-4o and GPT-4o-mini. The best agent achieved an accuracy of 19% on the hardest level of tasks, showing the vast scope for improvement in automating routine scientific tasks. Having agents that can reproduce existing work is a necessary step toward building agents that can conduct novel research and could verify and improve the performance of other research agents. We hope that CORE-Bench can improve the state of reproducibility and spur the development of future research agents.
The creation of manufacturable and editable 3D shapes through Computer-Aided Design (CAD) remains a highly manual and time-consuming task, hampered by the complex topology of boundary representations of 3D solids and unintuitive design tools. While most work in the 3D shape generation literature focuses on representations like meshes, voxels, or point clouds, practical engineering applications demand the modifiability and manufacturability of CAD models and the ability for multi-modal conditional CAD model generation. This paper introduces GenCAD, a generative model that employs autoregressive transformers with a contrastive learning framework and latent diffusion models to transform image inputs into parametric CAD command sequences, resulting in editable 3D shape representations. Extensive evaluations demonstrate that GenCAD significantly outperforms existing state-of-the-art methods in terms of the unconditional and conditional generations of CAD models. Additionally, the contrastive learning framework of GenCAD facilitates the retrieval of CAD models using image queries from large CAD databases, which is a critical challenge within the CAD community. Our results provide a significant step forward in highlighting the potential of generative models to expedite the entire design-to-production pipeline and seamlessly integrate different design modalities.
The exponential rise in size and complexity of deep learning models and datasets have resulted in a considerable demand for computational resources. Coreset selection is one of the methods to alleviate this rising demand. The goal is to select a subset from a large dataset to train a model that performs almost at par with the one trained on the large dataset while reducing computational time and resource requirements. Existing approaches either attempt to identify remarkable samples (e.g., Forgetting, Adversarial Deepfool, EL2N, etc.) that stand out from the rest or solve complex optimization (e.g., submodular maximization, OMP) problems to compose the coresets. This paper proposes a novel and intuitive approach to efficiently select a coreset based on the similarity of loss gradients. Our method works on the hypothesis that gradients of samples belonging to a given class will point in similar directions during the early training phase. Samples with most neighbours that produce similar gradient directions, in other words, that produce noise-free gradients, will represent that class. Through extensive experimentation, we have demonstrated the effectiveness of our approach in out-performing state-of-the-art coreset selection algorithms on a range of benchmark datasets from CIFAR-10 to ImageNet with architectures of varied complexity (ResNet-18, ResNet-50, VGG-16, ViT).We have also demonstrated the effectiveness of our approach in Generative Modelling by implementing coreset selection to reduce training time for various GAN models (DCGAN, MSGAN, SAGAN, SNGAN) for different datasets (CIFAR-10, CIFAR-100, Tiny ImageNet) while not impacting the performance metrics significantly. Source code is provided at URL.

Shapley values are widely used in machine learning to interpret model predictions. However, they have an important drawback in their computational time, which is exponential in the number of variables in the data. Recent work has yielded algorithms that can efficiently and exactly calculate the Shapley values of specific model families, such as Decision Trees and Generalized Additive Models (GAMs). Unfortunately, these model families are fairly restricted. Consequently, we present STAR-SHAP, an algorithm for efficiently calculating the Shapley values of Structured Additive Regression (STAR) models, a generalization of GAMs which allow any number of variable interactions. While the computational cost of STAR-SHAP scales exponentially in the size of these interactions, it is independent of the total number of variables. This allows the interpretation of more complex and flexible models. As long as the variable interactions are moderately-sized, the computation of the Shapley values will be fast, even on high-dimensional datasets. Since STAR models with more than pairwise interactions (e.g. GA2Ms) are seldom used in practice, we also present a new class of STAR models built on the RKHS Weightings of Functions paradigm. More precisely, we introduce a new RKHS Weighting instantiation, and show how to transform it and other RKHS Weightings into STAR models. We therefore introduce a new family of STAR models, as well as the means to interpret their outputs in a timely manner.

In deep Reinforcement Learning (RL), value functions are typically approximated using deep neural networks and trained via mean squared error regression objectives to fit the true value functions. Recent research has proposed an alternative approach, utilizing the cross-entropy classification objective, which has demonstrated improved performance and scalability of RL algorithms. However, existing study have not extensively benchmarked the effects of this replacement across various domains, as the primary objective was to demonstrate the efficacy of the concept across a broad spectrum of tasks, without delving into in-depth analysis. Our work seeks to empirically investigate the impact of such a replacement in an offline RL setup and analyze the effects of different aspects on performance. Through large-scale experiments conducted across a diverse range of tasks using different algorithms, we aim to gain deeper insights into the implications of this approach. Our results reveal that incorporating this change can lead to superior performance over state-of-the-art solutions for some algorithms in certain tasks, while maintaining comparable performance levels in other tasks, however for other algorithms this modification might lead to the dramatic performance drop. This findings are crucial for further application of classification approach in research and practical tasks.

Deep Neural Networks (DNNs) are susceptible to adversarial inputs, such as imperceptible noise and naturally occurring challenging samples. This vulnerability likely arises from their passive, one-shot processing approach. In contrast, neuroscience suggests that human vision robustly identifies salient object features by actively switching between multiple fixation points (saccades) and processing surroundings with non-uniform resolution (foveation). This information is processed via two pathways: the dorsal (where) and ventral (what) streams, which identify relevant input portions and discard irrelevant details. Building on this perspective, we outline a deep learning-based active dorsal-ventral vision system and adapt two prior methods, FALcon and GFNet, within this framework to evaluate their robustness. We conduct a comprehensive robustness analysis across three categories: adversarially crafted inputs evaluated under transfer attack scenarios, natural adversarial images, and foreground-distorted images. By learning from focused, downsampled glimpses at multiple distinct fixation points, these active methods significantly enhance the robustness of passive networks, achieving a 2-21 % increase in accuracy. This improvement is demonstrated against state-of-the-art transferable black-box attack. On ImageNet-A, a benchmark for naturally occurring hard samples, we show how distinct predictions from multiple fixation points yield performance gains of 1.5-2 times for both CNN and Transformer based networks. Lastly, we qualitatively demonstrate how an active vision system aligns more closely with human perception for structurally distorted images. This alignment leads to more stable and resilient predictions, with lesser catastrophic mispredictions. In contrast, passive methods, which rely on single-shot learning and inference, often lack the necessary structural understanding.

This work studies the problem of time series analysis with generalist (or foundation) models, which are models trained across many data domains. Drawing inspiration from the widespread success of large language models, we consider the simple strategy of discretely tokenizing time series data drawn from a myriad of datasets via self-supervision, then using the fixed tokenization to solve a variety of tasks across many data domains. Canonically, time series models are either trained on a single dataset or built in a task-specific manner (e.g., a forecasting-only model), where many use patches of time as inputs to the model. As such, performant generalist, discrete representation time series models explored across many tasks are of value. Our method, TOkenized Time Series EMbeddings (TOTEM), produces such generalist time series models with minimal or no fine-tuning while exhibiting strong zero-shot performance. We evaluate TOTEM extensively over nearly 500 experiments on three commonly-studied time series tasks with real-world data: imputation (17 baselines, 12 datasets), anomaly detection (19 baselines, 25 datasets), and forecasting (14 baselines, 12 datasets). We conclude that TOTEM matches or outperforms existing state-of-the-art models in both the canonical specialist setting (i.e., training one model on one domain) as well as the generalist setting (i.e., training a single model on many domains), which demonstrates the efficacy of tokenization for general time series analysis. The open-source implementation is available here: https://github.com/SaberaTalukder/TOTEM; a video summary is available here: https://www.youtube.com/watch?v=OqrCpdb6MJk.

Edge applications, such as collaborative robotics and spacecraft rendezvous, demand efficient 6D object pose estimation on resource-constrained embedded platforms. Existing 6D object pose estimation networks are often too large for such deployments, necessitating compression while maintaining reliable performance. To address this challenge, we introduce Modular Quantization-Aware Training (MQAT), an adaptive and mixed-precision quantization-aware training strategy that exploits the modular structure of modern 6D object pose estimation architectures. MQAT guides a systematic gradated modular quantization sequence and determines module-specific bit precisions, leading to quantized models that outperform those produced by state-of-the-art uniform and mixed-precision quantization techniques. Our experiments showcase the generality of MQAT across datasets, architectures, and quantization algorithms. Additionally, we observe that MQAT quantized models can achieve an accuracy boost (>7% ADI-0.1d) over the baseline full-precision network while reducing model size by a factor of 4x or more. Project Page: https://saqibjaved1.github.io/MQAT_
Reinforcement learning (RL) and causal reasoning naturally complement each other. The goal of causal reasoning is to predict the effects of interventions in an environment, while the goal of reinforcement learning is to select interventions that maximize the rewards the agent receives from the environment. Reinforcement learning includes the two most powerful sources of information for estimating causal relationships: temporal ordering and the ability to act on an environment. This paper provides a theoretical study examining which reinforcement learning settings we can expect to benefit from causal reasoning, and how. According to our analysis, the key factor is {\em whether the behavioral policy---which generates the data---can be executed by the learning agent}, meaning that the observation signal available to the learning agent comprises all observations used by the behavioral policy. Common RL settings with behavioral policies that are executable by the learning agent include on-policy learning and online exploration, where the learning agent uses a behavioral policy to explore the environment. Common RL settings with behavioral policies that are not executable by the learning agent include offline learning with a partially observable state space and asymmetric imitation learning where the demonstrator has access to more observations than the imitator. Using the theory of causal graphs, we show formally that when the behavioral policy is executable by the learning agent, conditional probabilities are causal, and can therefore be used to estimate expected rewards as done in traditional RL. However, when the behavioral policy is not executable by the learning agent, conditional probabilities may be confounded and provide misleading estimates of expected rewards. For confounded settings, we describe previous and new methods for leveraging causal reasoning.
Obtaining accurate probabilistic forecasts is an operational challenge in many applications, such as energy management, climate forecasting, supply chain planning, and resource allocation. Many of these applications present a natural hierarchical structure over the forecasted quantities; and forecasting systems that adhere to this hierarchical structure are said to be coherent. Furthermore, operational planning benefits from the accuracy at all levels of the aggregation hierarchy. However, building accurate and coherent forecasting systems is challenging: classic multivariate time series tools and neural network methods are still being adapted for this purpose. In this paper, we augment an MQForecaster neural network architecture with a modified multivariate Gaussian factor model that achieves coherence by construction. The factor model samples can be differentiated with respect to the model parameters, allowing optimization on arbitrary differentiable learning objectives that align with the forecasting system's goals, including quantile loss and the scaled Continuous Ranked Probability Score (CRPS). We call our method the Coherent Learning Objective Reparametrization Neural Network (CLOVER). In comparison to state-of-the-art coherent forecasting methods, CLOVER achieves significant improvements in scaled CRPS forecast accuracy, with average gains of 15%, as measured on six publicly-available datasets.

Vision-based imitation learning has shown promising capabilities of endowing robots with various motion skills given visual observation. However, current visuomotor policies fail to adapt to drastic changes in their visual observations. We present Perception Stitching that enables strong zero-shot adaptation to large visual changes by directly stitching novel combinations of visual encoders. Our key idea is to enforce modularity of visual encoders by aligning the latent visual features among different visuomotor policies. Our method disentangles the perceptual knowledge with the downstream motion skills and allows the reuse of the visual encoders by directly stitching them to a policy network trained with partially different visual conditions. We evaluate our method in various simulated and real-world manipulation tasks. While baseline methods failed at all attempts, our method could achieve zero-shot success in real-world visuomotor tasks. Our quantitative and qualitative analysis of the learned features of the policy network provides more insights into the high performance of our proposed method.
Efficient class forgetting has attracted significant interest due to the high computational cost of retraining models from scratch whenever classes need to be forgotten. This need arises from data privacy regulations, the necessity to remove outdated information, and the possibility to enhance model robustness and security. In this paper we address class forgetting in vision-language CLIP model. Modern class forgetting methods for CLIP have demonstrated that zero-shot forgetting is achievable by generating synthetic data and fine-tuning both visual and textual encoders with a regularization loss. Our approach shows that class forgetting in CLIP can be accomplished in a zero-shot manner without any visual data by adapting the shared vision-text space of CLIP, thereby making the class forgetting process more efficient. Our method delivers superior results, demonstrating strong performance and complete class removal, regardless of the visual encoder used in CLIP. Furthermore, we explore what exactly is being targeted by the class forgetting algorithm discovering some interesting properties of CLIP features.

Despite their great practical successes, the understanding of neural network behavior is still a topical research issue. In particular, the class of functions learnable in the context of a finite precision configuration is an open question. In this paper, we propose to study the limits of gradient descent when such a configuration is set for the class of Simple Recurrent Networks (SRN). We exhibit conditions under which the gradient descend will provably fail. We also design a class of SRN based on Deterministic finite State Automata (DFA) that fulfills the failure requirements. The definition of this class is constructive: we propose an algorithm that, from any DFA, constructs a SRN that computes exactly the same function, a result of interest by its own.

Vision-language foundation models such as CLIP have showcased impressive zero-shot capabilities. However, their applicability in resource-constrained environments is limited due to their size and the resulting latency. Knowledge distillation allows to mitigate these challenges by distilling small image encoders that can replace the large CLIP image encoder. In a zero-shot setting, where only the class names are known, no real domain images can be used for this process. Instead, we investigate the use of synthetic images for this purpose. Unlike existing works that focus on improving the quality of synthetic images to bridge the performance gap compared to training on natural images, we find the choice of loss to be a crucial factor. Specifically, minimizing only the distance between the student and teacher image features, without incorporating image captions in the loss function, increases the robustness to spurious features and data corruptions. As a result, this feature distillation approach greatly improves the transfer performance from synthetic to real images. Leveraging these insights, we are able to train domain-specific students that achieve zero-shot performance comparable to a ViT-B/32 teacher on six fine-grained classification datasets while using up to 92% fewer parameters.
In online convex optimization, some efficient algorithms have been designed for each of the individual classes of objective functions, e.g., convex, strongly convex, and exp-concave. However, existing regret analyses, including those of universal algorithms, are limited to cases in which the objective functions in all rounds belong to the same class and cannot be applied to cases in which the property of objective functions may change in each time step. This paper introduces a novel approach to address such cases, proposing a new regime we term as \textit{contaminated} online convex optimization. For the contaminated case, we demonstrate that the regret is lower bounded by $\Omega(\log T + \sqrt{k})$. Here, $k$ signifies the level of contamination in the objective functions. We also demonstrate that the regret is bounded by $O(\log T+\sqrt{k\log T})$ when universal algorithms are used. When our proposed algorithms with additional information are employed, the regret is bounded by $O(\log T+\sqrt{k})$, which matches the lower bound. These are intermediate bounds between a convex case and a strongly convex or exp-concave case.

Regression is a powerful tool to accurately predict the outcome metric of a system given a set of parameters, but has traditionally been restricted to methods which are only applicable to a specific task. In this paper, we propose OmniPred, a framework for training language models as universal end-to-end regressors over (x,y) data from arbitrary formats. Using data sourced from Google Vizier, one of the largest proprietary blackbox optimization databases in the world, our extensive experiments demonstrate that language models are capable of very precise numerical regression using only textual representations of mathematical parameters and values, and if given the opportunity to train at scale over multiple tasks, can significantly outperform traditional regression models.

We propose a linear time graph transformation that enables the Weisfeiler-Leman (WL) algorithm and message passing graph neural networks (MPNNs) to be maximally expressive on outerplanar graphs. Our approach is motivated by the fact that most pharmaceutical molecules correspond to outerplanar graphs. Existing research predominantly enhances the expressivity of graph neural networks without specific graph families in mind. This often leads to methods that are impractical due to their computational complexity. In contrast, the restriction to outerplanar graphs enables us to encode the Hamiltonian cycle of each biconnected component in linear time. As the main contribution of the paper we prove that our method achieves maximum expressivity on outerplanar graphs. Experiments confirm that our graph transformation improves the predictive performance of MPNNs on molecular benchmark datasets at negligible computational overhead.

In this paper we investigate transformer architectures designed for partially observable online reinforcement learning. The self-attention mechanism in the transformer architecture is capable of capturing long-range dependencies and it is the main reason behind its effectiveness in processing sequential data. Nevertheless, despite their success, transformers have two significant drawbacks that still limit their applicability in online reinforcement learning: (1) in order to remember all past information, the self-attention mechanism requires access to the whole history to be provided as context. (2) The inference cost in transformers is expensive. In this paper, we introduce recurrent alternatives to the transformer self-attention mechanism that offer context-independent inference cost, leverage long-range dependencies effectively, and performs well in online reinforcement learning task. We quantify the impact of the different components of our architecture in a diagnostic environment and assess performance gains in 2D and 3D pixel-based partially-observable environments (e.g. T-Maze, Mystery Path, Craftax, and Memory Maze). Compared with a state-of-the-art architecture, GTrXL, inference in our approach is at least 40% cheaper while reducing memory use more than 50%. Our approach either performs similarly or better than GTrXL, improving more than 37% upon GTrXL performance in harder tasks.

Point Cloud Registration (PCR) estimates the relative rigid transformation between two point clouds of the same scene. Despite significant progress with learning-based approaches, existing methods still face challenges when the overlapping region between the two point clouds is small. In this paper, we propose an adaptive multi-step refinement network that refines the registration quality at each step by leveraging the information from the preceding step. To achieve this, we introduce a training procedure and a refinement network. Firstly, to adapt the network to the current step, we utilize a generalized one-way attention mechanism, which prioritizes the last step's estimated overlapping region, and we condition the network on step indices. Secondly, instead of training the network to map either random transformations or a fixed pre-trained model's estimations to the ground truth, we train it on transformations with varying registration qualities, ranging from accurate to inaccurate, thereby enhancing the network's adaptiveness and robustness. Despite its conceptual simplicity, our method achieves state-of-the-art performance on both the 3DMatch/3DLoMatch and KITTI benchmarks. Notably, on 3DLoMatch, our method reaches 80.4% recall rate, with an absolute improvement of 1.2%.

An interactive robot framework accomplishes long-horizon task planning and can easily generalize to new goals or distinct tasks, even during execution. However, most traditional methods require predefined module design, which makes it hard to generalize to different goals. Recent large language model based approaches can allow for more open-ended planning but often require heavy prompt engineering or domain specific pretrained models. To tackle this, we propose a simple framework that achieves interactive task planning with language models by incorporating both high-level planning and low-level skill execution through function calling, leveraging pretrained vision models to ground the scene in language. We verify the robustness of our system on the real world task of making milk tea drinks. Our system is able to generate novel high-level instructions for unseen objectives and successfully accomplishes user tasks. Furthermore, when the user sends a new request, our system is able to replan accordingly with precision based on the new request, task guidelines and previously executed steps. Our approach is easy to adapt to different tasks by merely substituting the task guidelines, without the need for additional complex prompt engineering.

Continuous-time dynamic graphs (CTDGs) are essential for modeling interconnected, evolving systems. Traditional methods for extracting knowledge from these graphs often depend on feature engineering or deep learning. Feature engineering is limited by the manual and time-intensive nature of crafting features, while deep learning approaches suffer from high inference latency, making them impractical for real-time applications. This paper introduces Deep-Graph-Sprints (DGS), a novel deep learning architecture designed for efficient representation learning on CTDGs with low-latency inference requirements. We benchmark DGS against state-of-the-art (SOTA) feature engineering and graph neural network methods using five diverse datasets. The results indicate that DGS achieves competitive performance while inference speed improves between 4x and 12x compared to other deep learning approaches on our benchmark datasets. Our method effectively bridges the gap between deep representation learning and low-latency application requirements for CTDGs.

State-of-the-art self-supervised representation learning methods for Graphs are typically based on contrastive learning (CL) principles. These CL objective functions can be posed as a supervised discriminative task using *'hard'* labels that consider any minor augmented pairs of graphs as 'equally positive'. However, such a notion of 'equal' pairs is incorrect for graphs as even a smaller 'discrete' perturbation may lead to large semantic changes that should be carefully encapsulated within the learned representations. This paper proposes a novel CL framework for GNNs, called *Teacher-guided Graph Contrastive Learning (TGCL)*, that incorporates 'soft' pseudo-labels to facilitate a more regularized discrimination. In particular, we propose a teacher-student framework where the student learns the representation by distilling the teacher's perception. Our TGCL framework can be adapted to existing CL methods to enhance their performance. Our empirical findings validate these claims on both inductive and transductive settings across diverse downstream tasks, including molecular graphs and social networks. Our experiments on benchmark datasets demonstrate that our framework consistently improves the average AUROC scores for molecules' property prediction and social network link prediction. Our code is available at: https://github.com/jayjaynandy/TGCL.

Combining the strengths of many existing predictors to obtain a Mixture of Experts which is superior to its individual components is an effective way to improve the performance without having to develop new architectures or train a model from scratch. However, surprisingly, we find that naively combining off-the-shelf object detectors in a similar way to Deep Ensembles, can often lead to degraded performance. We identify that the primary cause of this issue is that the predictions of the experts do not match their performance, a term referred to as miscalibration. Consequently, the most confident detector dominates the final predictions, preventing the mixture from leveraging all the predictions from the experts appropriately. To address this, when constructing the Mixture of Experts for object detection, we propose to combine their predictions in a manner which reflects the individual performance of the experts; an objective we achieve by first calibrating the predictions before filtering and refining them. We term this approach the Mixture of Calibrated Experts (MoCaE) and demonstrate its effectiveness through extensive experiments on 5 different detection tasks, showing that it: (i) improves object detectors on COCO and instance segmentation methods on LVIS by up to $\sim 2.5$ AP; (ii) reaches state-of-the-art on COCO test-dev with $65.1$ AP and on DOTA with $82.62$ $\mathrm{AP_{50}}$; (iii) outperforms single models consistently on recent detection tasks such as Open Vocabulary Object Detection. Code is available at: https://github.com/fiveai/MoCaE

We introduce a method for flexible and efficient continual learning in open-vocabulary image classification, drawing inspiration from the complementary learning systems observed in human cognition. Specifically, we propose to combine predictions from a CLIP zero-shot model and the exemplar-based model, using the zero-shot estimated probability that a sample's class is within the exemplar classes. We also propose a ``tree probe'' method, an adaption of lazy learning principles, which enables fast learning from new examples with competitive accuracy to batch-trained linear models. We test in data incremental, class incremental, and task incremental settings, as well as ability to perform flexible inference on varying subsets of zero-shot and learned categories. Our proposed method achieves a good balance of learning speed, target task effectiveness, and zero-shot effectiveness. Code is available at https://github.com/jessemelpolio/TreeProbe.
Large Language Models (LLMs) trained on massive datasets may inadvertently acquire sensitive information such as personal details and potentially harmful content. This risk is further heightened in multimodal LLMs (aka MLLMs) as they integrate information from multiple modalities (image and text). Adversaries can exploit this stored knowledge by crafting inputs across modalities to extract sensitive details. Evaluating how effectively MLLMs can forget such information (targeted unlearning) necessitates the creation of high-quality, well-annotated image-text pairs. While significant research has addressed the creation of datasets for unlearning within LLMs, it has primarily concentrated on text modality. Creation of analogous datasets for multimodal data and models remain an understudied area. To address this gap, we first introduce a multimodal unlearning benchmark, UnLOK-VQA (Unlearning Outside Knowledge VQA), as well as an “attack and-defense” framework to evaluate methods for deleting specific multimodal knowledge from MLLMs. Our dataset generation process involves an automated pipeline to create samples of varied proximity levels to the target data point for evaluation of generalization and specificity, followed by manual filtering to retain only the high-quality data points. We use this process to extend a visual question-answering dataset for evaluating multimodal information deletion. Next, we present a comprehensive unlearning evaluation involving an attack-and-defense framework consisting of four white box and three blackbox attacks against six unlearning defense objectives. We also design a whitebox attack based on the interpretability of hidden states in LLMs motivated by past work. Our experimental results demonstrate that multimodal extraction attacks (with an attack success rate of 45.5%) are more successful than either image-only (32%) or text-only attacks (39%). The best overall defense mechanism, which removes answer information from internal model hidden states, reduces the success rate of multimodal attack to 15.7%. Furthermore, our findings suggest that larger models exhibit greater resilience to attacks, implying that model scaling could be a valuable strategy for enhancing robustness and developing safer models. UnLOK-VQA thus facilitates a comprehensive evaluation of unlearning in MLLMs and serves as a challenging benchmark for future research in unlearning.

Symmetries of input and latent vectors have provided valuable insights for disentanglement learning in VAEs. However, only a few works were proposed as an unsupervised method, and even these works require known factor information in training data. We propose a novel method, Composite Factor-Aligned Symmetry Learning (CFASL), which is integrated into VAEs for learning symmetry-based disentanglement in unsupervised learning without any knowledge of the dataset factor information. CFASL incorporates three novel features for learning symmetry-based disentanglement: 1) Injecting inductive bias to align latent vector dimensions to factor-aligned symmetries within an explicit learnable symmetry code-book 2) Learning a composite symmetry to express unknown factors change between two random samples by learning factor-aligned symmetries within the codebook 3) Inducing group equivariant encoder and decoder in training VAEs with the two conditions. In addition, we propose an extended evaluation metric for multi-factor changes in comparison to disentanglement evaluation in VAEs. In quantitative and in-depth qualitative analysis, CFASL demonstrates a significant improvement of disentanglement in single-factor change, and multi-factor change conditions compared to state-of-the-art methods.

In this article, we introduce \textit{audio-visual dataset distillation}, a task to construct a smaller yet representative synthetic audio-visual dataset that maintains the cross-modal semantic association between audio and visual modalities. Dataset distillation techniques have primarily focused on image classification. However, with the growing capabilities of audio-visual models and the vast datasets required for their training, it is necessary to explore distillation methods beyond the visual modality. Our approach builds upon the foundation of Distribution Matching (DM), extending it to handle the unique challenges of audio-visual data. A key challenge is to jointly learn synthetic data that distills both the modality-wise information and natural alignment from real audio-visual data. We introduce a vanilla audio-visual distribution matching framework that separately trains visual-only and audio-only DM components, enabling us to investigate the effectiveness of audio-visual integration and various multimodal fusion methods. To address the limitations of unimodal distillation, we propose two novel matching losses: implicit cross-matching and cross-modal gap matching. These losses work in conjunction with the vanilla unimodal distribution matching loss to enforce cross-modal alignment and enhance the audio-visual dataset distillation process. Extensive audio-visual classification and retrieval experiments on four audio-visual datasets, AVE, MUSIC-21, VGGSound, and VGGSound-10K, demonstrate the effectiveness of our proposed matching approaches and validate the benefits of audio-visual integration with condensed data. This work establishes a new frontier in audio-visual dataset distillation, paving the way for further advancements in this exciting field. \textit{Our source code and pre-trained models will be released}.

Machine learning tasks are generally formulated as optimization problems, where one searches for an optimal function within a certain functional space. In practice, parameterized functional spaces are considered, in order to be able to perform gradient descent. Typically, a neural network architecture is chosen and fixed, and its parameters (connection weights) are optimized, yielding an architecture-dependent result. This way of proceeding however forces the evolution of the function during training to lie within the realm of what is expressible with the chosen architecture, and prevents any optimization across architectures. Costly architectural hyper-parameter optimization is often performed to compensate for this. Instead, we propose to adapt the architecture on the fly during training. We show that the information about desirable architectural changes, due to expressivity bottlenecks when attempting to follow the functional gradient, can be extracted from backpropagation. To do this, we propose a mathematical definition of expressivity bottlenecks, which enables us to detect, quantify and solve them while training, by adding suitable neurons. Thus, while the standard approach requires large networks, in terms of number of neurons per layer, for expressivity and optimization reasons, we provid tools and properties to develop an architecture starting with a very small number of neurons. As a proof of concept, we show results~on the CIFAR dataset, matching large neural network accuracy, with competitive training time, while removing the need for standard architectural hyper-parameter search.

Mislabeled examples are ubiquitous in real-world machine learning datasets, advocating the development of techniques for automatic detection. We show that most mislabeled detection methods can be viewed as probing trained machine learning models using a few core principles. We formalize a modular framework that encompasses these methods, parameterized by only 4 building blocks, as well as a Python library that demonstrates that these principles can actually be implemented. The focus is on classifier-agnostic concepts, with an emphasis on adapting methods developed for deep learning models to non-deep classifiers for tabular data. We benchmark existing methods on (artificial) Completely At Random (NCAR) as well as (realistic) Not At Random (NNAR) labeling noise from a variety of tasks with imperfect labeling rules. This benchmark provides new insights as well as limitations of existing methods in this setup.

The growing deployment of Machine Learning systems has increased interest in systems optimized for other important criteria along with the expected task performance. For instance, machine learning models often exhibit biases that lead to unfair outcomes for certain protected subpopulations. This work aims to handle the bias in machine learning models and enhance their fairness by aligning the loss gradients. Specifically, leveraging the meta-learning technique, we propose a novel training framework that aligns the gradients computed across different subpopulations for learning fair classifiers. Aligning the gradients enables our framework to regularize the training process, thereby prioritizing fairness over predictive accuracy. Our experiments on multiple benchmark datasets demonstrate significant improvements in fairness metrics without having any exclusive regularizers for fairness. Thus our work contributes to developing fairer machine learning models with broader societal benefits.

We study a class of distributed optimization algorithms that aim to alleviate high communication costs by allowing clients to perform multiple local gradient-type training steps before communication. In a recent breakthrough, Mishchenko et al. (2022) proved that local training, when properly executed, leads to provable communication acceleration, and this holds in the strongly convex regime without relying on any data similarity assumptions. However, their ProxSkip method requires all clients to take the same number of local training steps in each communication round. We propose a redesign of the ProxSkip method, allowing clients with ``less important'' data to get away with fewer local training steps without impacting the overall communication complexity of the method. In particular, we prove that our modified method, GradSkip, converges linearly under the same assumptions and has the same accelerated communication complexity, while the number of local gradient steps can be reduced relative to a local condition number. We further generalize our method by extending the randomness of probabilistic alternations to arbitrary unbiased compression operators and by considering a generic proximable regularizer. This generalization, which we call GradSkip+, recovers several related methods in the literature as special cases. Finally, we present an empirical study on carefully designed toy problems that confirm our theoretical claims.

Graphs serve as generic tools to encode the underlying relational structure of data. Often this graph is not given, and so the task of inferring it from nodal observations becomes important. Traditional approaches formulate a convex inverse problem with a smoothness promoting objective and rely on iterative methods to obtain a solution. In supervised settings where graph labels are available, one can unroll and truncate these iterations into a deep network that is trained end-to-end. Such a network is parameter efficient and inherits inductive bias from the optimization formulation, an appealing aspect for data constrained settings in, e.g., medicine, finance, and the natural sciences. But typically such settings care equally about \textit{uncertainty} over edge predictions, not just point estimates. Here we introduce novel iterations with \textit{independently interpretable parameters}, i.e., parameters whose values - independent of other parameters' settings - proportionally influence characteristics of the estimated graph, such as edge sparsity. After unrolling these iterations, prior knowledge over such graph characteristics shape \textit{prior distributions} over these independently interpretable network parameters to yield a Bayesian neural network (BNN) capable of graph structure learning (GSL) from smooth signal observations. Fast execution and parameter efficiency allow for high-fidelity posterior approximation via Markov Chain Monte Carlo (MCMC) and thus uncertainty quantification on edge predictions. Informative priors unlock modeling tools from Bayesian statistics like prior predictive checks. Synthetic and real data experiments corroborate this model's ability to provide well-calibrated estimates of uncertainty, in test cases that include unveiling economic sector modular structure from S$\&$P$500$ data and recovering pairwise digit similarities from MNIST images. Overall, this framework enables GSL in modest-scale applications where uncertainty on the data structure is paramount.

In advancing the understanding of natural decision-making processes, inverse reinforcement learning (IRL) methods have proven instrumental in reconstructing animal's intentions underlying complex behaviors. Given the recent development of a continuous-time multi-intention IRL framework, there has been persistent inquiry into inferring discrete time-varying rewards with IRL. To address this challenge, we introduce the class of hierarchical inverse Q-learning (HIQL) algorithms. Through an unsupervised learning process, HIQL divides expert trajectories into multiple intention segments, and solves the IRL problem independently for each. Applying HIQL to simulated experiments and several real animal behavior datasets, our approach outperforms current benchmarks in behavior prediction and produces interpretable reward functions. Our results suggest that the intention transition dynamics underlying complex decision-making behavior is better modeled by a step function instead of a smoothly varying function. This advancement holds promise for neuroscience and cognitive science, contributing to a deeper understanding of decision-making and uncovering underlying brain mechanisms.
Node embedding algorithms produce low-dimensional latent representations of nodes in a graph. These embeddings are often used for downstream tasks, such as node classification and link prediction. In this paper, we investigate the following two questions: (Q1) Can we explain each embedding dimension with human-understandable graph features (e.g. degree, clustering coefficient and PageRank). (Q2) How can we modify existing node embedding algorithms to produce embeddings that can be easily explained by human-understandable graph features? We find that the answer to Q1 is yes and introduce a new framework called XM (short for eXplain eMbedding) to answer Q2. A key aspect of XM involves minimizing the nuclear norm of the generated explanations. We show that by minimizing the nuclear norm, we minimize the lower bound on the entropy of the generated explanations. We test XM on a variety of real-world graphs and show that XM not only preserves the performance of existing node embedding methods, but also enhances their explainability.

Current machine learning methods struggle to solve Bongard problems, which are a type of IQ test that requires deriving an abstract “concept” from a set of positive and negative “support” images, and then classifying whether or not a new query image depicts the key concept. On Bongard-HOI, a benchmark for natural-image Bongard problems, most existing methods have reached at best 69% accuracy (where chance is 50%). Low accuracy is often attributed to neural nets’ lack of ability to find human-like symbolic rules. In this work, we point out that many existing methods are forfeiting accuracy due to a much simpler problem: they do not adapt image features given information contained in the support set as a whole, and rely instead on information extracted from individual supports. This is a critical issue, because the “key concept” in a typical Bongard problem can often only be distinguished using multiple positives and multiple negatives. We explore simple methods to incorporate this context and show substantial gains over prior works, leading to new state-of-the-art accuracy on Bongard-LOGO (75.3%) and Bongard-HOI (76.4%) compared to methods with equivalent vision backbone architectures and strong performance on the original Bongard problem set (60.8%). Code is available at https://github.com/nraghuraman/bongard-context.

Generative models have recently achieved remarkable success and widespread adoption in society, yet they still often struggle to generate realistic and accurate outputs. This challenge extends beyond language and vision into fields like engineering design, where safety-critical engineering standards and non-negotiable physical laws tightly constrain what outputs are considered acceptable. In this work, we introduce two approaches to guide models toward constraint-satisfying outputs using `negative data' -- examples of what to avoid. Our negative data generative models (NDGMs) outperform state-of-the-art NDGMs by 4x in constraint satisfaction and easily outperform classic generative models using 8x less data in certain problems. To demonstrate this, we rigorously benchmark our NDGMs against 14 baseline models across numerous synthetic and real engineering problems, such as ship hulls with hydrodynamic constraints and vehicle design with impact safety constraints. Our benchmarks showcase both the best-in-class performance of our new NDGM models and the widespread dominance of NDGMs over classic generative models in general. In doing so, we advocate for the more widespread use of NDGMs in engineering design tasks.

Object-centric scene decompositions are important representations for downstream tasks in fields such as computer vision and robotics. The recently proposed Slot Attention module, already leveraged by several derivative works for image segmentation and object tracking in videos, is a deep learning component which performs unsupervised object-centric scene decomposition on input images. It is based on an attention architecture, in which latent slot vectors, which hold compressed information on objects, attend to localized perceptual features from the input image. In this paper, we demonstrate that design decisions on normalizing the aggregated values in the attention architecture have considerable impact on the capabilities of Slot Attention to generalize to a higher number of slots and objects as seen during training. We propose and investigate alternatives to the original normalization scheme which increase the generalization capabilities of Slot Attention to varying slot and object counts, resulting in performance gains on the task of unsupervised image segmentation. The newly proposed normalizations represent minimal and easy to implement modifications of the usual Slot Attention module, changing the value aggregation mechanism from a weighted mean operation to a scaled weighted sum operation.

\textbf{How can balance be quantified in game settings?} This question is crucial for game designers, especially in player-versus-player (PvP) games, where analyzing the strength relations among predefined team compositions—such as hero combinations in multiplayer online battle arena (MOBA) games or decks in card games—is essential for enhancing gameplay and achieving balance. We have developed two advanced measures that extend beyond the simplistic win rate to quantify balance in zero-sum competitive scenarios. These measures are derived from win value estimations, which employ strength rating approximations via the Bradley-Terry model and counter relationship approximations via vector quantization, significantly reducing the computational complexity associated with traditional win value estimations. Throughout the learning process of these models, we identify useful categories of compositions and pinpoint their counter relationships, aligning with the experiences of human players without requiring specific game knowledge. Our methodology hinges on a simple technique to enhance codebook utilization in discrete representation with a deterministic vector quantization process for an extremely small state space. Our framework has been validated in popular online games, including \textit{Age of Empires II}, \textit{Hearthstone}, \textit{Brawl Stars}, and \textit{League of Legends}. The accuracy of the observed strength relations in these games is comparable to traditional pairwise win value predictions, while also offering a more manageable complexity for analysis. Ultimately, our findings contribute to a deeper understanding of PvP game dynamics and present a methodology that significantly improves game balance evaluation and design.

Efficient inference of Deep Neural Networks (DNNs) on resource-constrained edge devices is essential. Quantization and sparsity are key techniques that translate to repetition and sparsity within tensors at the hardware-software interface. This paper introduces the concept of repetition-sparsity trade-off that helps explain computational efficiency during inference. We propose PLUM, a unified co-design framework that integrates DNN inference systems and quantization (forward and backward pass) to leverage the repetition-sparsity trade-off to improve inference efficiency. Our results demonstrate that PLUM’s quantization method is more accurate than binary quantization with the same number of non-zero weights. Detailed analysis indicates that signed binarization generates a smaller distribution of effectual (non-zero) parameters nested within a larger distribution of total parameters of latent full-precision weights for a DNN block. Finally, the proposed PLUM framework achieves a 26% speedup on real hardware, doubles energy efficiency, and reduces density by 2.8× compared to binary methods while retaining top-1 accuracy when compared to prior-art methods for ResNets on ImageNet (by achieving 66.2% top-1 accuracy), presenting an alternative solution for deploying efficient models in resource-limited environments
We present a method to construct sparse neural networks using the theory of expander graphs. Expanders are sparse but well connected graph structures that are used for designing resilient networks. A Ramanujan graph is an extremal expander in terms of the spectral gap of its eigenvalues. In this work, bipartite Ramanujan expanders are deterministically constructed and used as connection structures of the convolutional and fully connected layers of a neural network. The Ramanujan graphs occur either as Cayley graphs of certain algebraic groups or as Ramanujan $r$-coverings of the full $(k,l)$ bi-regular bipartite graph on $k + l$ vertices. The proposed sparse networks are found to provide comparable performance to a fully dense network on benchmark datasets achieving an extremely low network density.

State-of-the-art semi-supervised learning (SSL) approaches rely on highly confident predictions to serve as pseudo-labels that guide the training on unlabeled samples. An inherent drawback of this strategy stems from the quality of the uncertainty estimates, as pseudo-labels are filtered only based on their degree of uncertainty, regardless of the correctness of their predictions. Thus, assessing and enhancing the uncertainty of network predictions is of paramount importance in the pseudo-labeling process. In this work, we empirically demonstrate that SSL methods based on pseudo-labels are significantly miscalibrated, and formally demonstrate the minimization of the min-entropy, a lower bound of the Shannon entropy, as a potential cause for miscalibration. To alleviate this issue, we integrate a simple penalty term, which enforces the logit distances of the predictions on unlabeled samples to remain low, preventing the network predictions to become overconfident. Comprehensive experiments on a variety of SSL image classification benchmarks demonstrate that the proposed solution systematically improves the calibration performance of relevant SSL models, while also enhancing their discriminative power, being an appealing addition to tackle SSL tasks.

Most existing works on fairness assume the model has full access to demographic information. However, there exist scenarios where demographic information is partially available because a record was not maintained throughout data collection or for privacy reasons. This setting is known as demographic scarce regime. Prior research has shown that training an attribute classifier to replace the missing sensitive attributes (proxy) can still improve fairness. However, using proxy-sensitive attributes worsens fairness-accuracy tradeoffs compared to true sensitive attributes. To address this limitation, we propose a framework to build attribute classifiers that achieve better fairness-accuracy tradeoffs. Our method introduces uncertainty awareness in the attribute classifier and enforces fairness on samples with demographic information inferred with the lowest uncertainty. We show empirically that enforcing fairness constraints on samples with uncertain sensitive attributes can negatively impact the fairness-accuracy tradeoff. Our experiments on five datasets showed that the proposed framework yields models with significantly better fairness-accuracy tradeoffs than classic attribute classifiers. Surprisingly, our framework can outperform models trained with fairness constraints on the true sensitive attributes in most benchmarks. We also show that these findings are consistent with other uncertainty measures such as conformal prediction.

The predominant method for computing confidence intervals (CI) in few-shot learning (FSL) is based on sampling the tasks with replacement, i.e. allowing the same samples to appear in multiple tasks. This makes the CI misleading in that it takes into account the randomness of the sampler but not the data itself. To quantify the extent of this problem, we conduct a comparative analysis between CIs computed with and without replacement. These reveal a notable underestimation by the predominant method. This observation calls for a reevaluation of how we interpret confidence intervals and the resulting conclusions in FSL comparative studies. Our research demonstrates that the use of paired tests can partially address this issue. Additionally, we explore methods to further reduce the (size of the) CI by strategically sampling tasks of a specific size. We also introduce a new optimized benchmark, which can be accessed at https://github.com/RafLaf/FSL-benchmark-again

Federated Learning (FL) is a machine learning paradigm that enables clients to jointly train a global model by aggregating the locally trained models without sharing any local training data. In practice, there can often be substantial heterogeneity (e.g., class imbalance) across the local data distributions observed by each of these clients. Under such non-iid label distributions across clients, FL suffers from the `client-drift’ problem where every client drifts to its own local optimum. This results in slower convergence and poor performance of the aggregated model. To address this limitation, we propose a novel regularization technique based on adaptive self-distillation (ASD) for training models on the client side. Our regularization scheme adaptively adjusts to each client's training data based on the global model's prediction entropy and the client-data label distribution. We show in this paper that our proposed regularization (ASD) can be easily integrated atop existing, state-of-the-art FL algorithms, leading to a further boost in the performance of these off-the-shelf methods. We theoretically explain how incorporation of ASD regularizer leads to reduction in client-drift and empirically justify the generalization ability of the trained model. We demonstrate the efficacy of our approach through extensive experiments on multiple real-world benchmarks and show substantial gains in performance when the proposed regularizer is combined with popular FL methods. The code is provided as supplementary material.

Identifying latent interactions within complex systems is key to unlocking deeper insights into their operational dynamics, including how their elements affect each other and contribute to the overall system behavior. For instance, in neuroscience, discovering neuron-to-neuron interactions is essential for understanding brain function; in ecology, recognizing the interactions among populations is key for understanding complex ecosystems. Such systems, often modeled as dynamical systems, typically exhibit noisy high-dimensional and non-stationary temporal behavior that renders their identification challenging. Existing dynamical system identification methods often yield operators that accurately capture short-term behavior but fail to predict long-term trends, suggesting an incomplete capture of the underlying process. Methods that consider extended forecasts (e.g., recurrent neural networks) lack explicit representations of element-wise interactions and require substantial training data, thereby failing to capture interpretable network operators. Here we introduce Lookahead-driven Inference of Networked Operators for Continuous Stability (LINOCS), a robust learning procedure for identifying hidden dynamical interactions in noisy time-series data. LINOCS integrates several multi-step predictions with adaptive weights during training to recover dynamical operators that can yield accurate long-term predictions. We demonstrate LINOCS' ability to recover the ground truth dynamical operators underlying synthetic time-series data for multiple dynamical systems models (including linear, piece-wise linear, time-changing linear systems' decomposition, and regularized linear time-varying systems) as well as its capability to produce meaningful operators with robust reconstructions through various real-world examples.

Fourier Neural Operators (FNO) offer a principled approach to solving challenging partial differential equations (PDE) such as turbulent flows. At the core of FNO is a spectral layer that leverages a discretization-convergent representation in the Fourier domain, and learns weights over a fixed set of frequencies. However, training FNO presents two significant challenges, particularly in large-scale, high-resolution applications: (i) Computing Fourier transform on high-resolution inputs is computationally intensive but necessary since fine-scale details are needed for solving many PDEs, such as fluid flows, (ii) selecting the relevant set of frequencies in the spectral layers is challenging, and too many modes can lead to overfitting, while too few can lead to underfitting. To address these issues, we introduce the Incremental Fourier Neural Operator (iFNO), which progressively increases both the number of frequency modes used by the model as well as the resolution of the training data. We empirically show that iFNO reduces total training time while maintaining or improving generalization performance across various datasets. Our method demonstrates a 38% lower testing error, using 20% fewer frequency modes compared to the existing FNO, while also achieving up to 46% faster training and a 2.8x reduction in model size.

Current state-of-the-art diffusion models employ U-Net architectures containing convolutional and (qkv) self-attention layers. The U-Net processes images while being conditioned on the time embedding input for each sampling step and the class or caption embedding input corresponding to the desired conditional generation. Such conditioning involves scale-and-shift operations to the convolutional layers but does not directly affect the attention layers. While these standard architectural choices are certainly effective, not conditioning the attention layers feels arbitrary and potentially suboptimal. In this work, we show that simply adding LoRA conditioning to the attention layers without changing or tuning the other parts of the U-Net architecture improves the image generation quality. For example, a drop-in addition of LoRA conditioning to EDM diffusion model yields FID scores of 1.91/1.75 for unconditional and class-conditional CIFAR-10 generation, improving upon the baseline of 1.97/1.79.

Defining and measuring decision-making styles, also known as playstyles, is crucial in gaming, where these styles reflect a broad spectrum of individuality and diversity. However, finding a universally applicable measure for these styles poses a challenge. Building on $\textit{Playstyle Distance}$, the first unsupervised metric to measure playstyle similarity based on game screens and raw actions by identifying comparable states with discrete representations for computing policy distance, we introduce three enhancements to increase accuracy: multiscale analysis with varied state granularity, a perceptual kernel rooted in psychology, and the utilization of the intersection-over-union method for efficient evaluation. These innovations not only advance measurement precision but also offer insights into human cognition of similarity. Across two racing games and seven Atari games, our techniques significantly improve the precision of zero-shot playstyle classification, achieving an accuracy exceeding 90\% with fewer than 512 observation-action pairs—less than half an episode of these games. Furthermore, our experiments with $\textit{2048}$ and $\textit{Go}$ demonstrate the potential of discrete playstyle measures in puzzle and board games. We also develop an algorithm for assessing decision-making diversity using these measures. Our findings improve the measurement of end-to-end game analysis and the evolution of artificial intelligence for diverse playstyles.
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
Bayesian Neural Networks (BNNs) offer a principled and natural framework for proper uncertainty quantification in the context of deep learning. They address the typical challenges associated with conventional deep learning methods, such as data insatiability, ad-hoc nature, and susceptibility to overfitting. However, their implementation typically either relies on Markov chain Monte Carlo (MCMC) methods, which are characterized by their computational intensity and inefficiency in a high-dimensional space, or variational inference methods, which tend to underestimate uncertainty. To address this issue, we propose a novel Calibration-Emulation-Sampling (CES) strategy to significantly enhance the computational efficiency of BNN. In this framework, during the initial calibration stage, we collect a small set of samples from the parameter space. These samples serve as training data for the emulator, which approximates the map between parameters and posterior probability. The trained emulator is then used for sampling from the posterior distribution at substantially higher speed compared to the standard BNN. Using simulated and real data, we demonstrate that our proposed method improves computational efficiency of BNN, while maintaining similar performance in terms of prediction accuracy and uncertainty quantification.

Animals and robots navigate through environments by building and refining maps of space. These maps enable functions including navigation back to home, planning, search and foraging. Here, we use observations from neuroscience, specifically the observed fragmentation of grid cell map in compartmentalized spaces, to propose and apply the concept of Fragmentation-and-Recall (FARMap) in the mapping of large spaces. Agents solve the mapping problem by building local maps via a surprisal-based clustering of space, which they use to set subgoals for spatial exploration. Agents build and use a local map to predict their observations; high surprisal leads to a "fragmentation event" that truncates the local map. At these events, the recent local map is placed into long-term memory (LTM) and a different local map is initialized. If observations at a fracture point match observations in one of the stored local maps, that map is recalled (and thus reused) from LTM. The fragmentation points induce a natural online clustering of the larger space, forming a set of intrinsic potential subgoals that are stored in LTM as a topological graph. Agents choose their next subgoal from the set of near and far potential subgoals from within the current local map or LTM, respectively. Thus, local maps guide exploration locally, while LTM promotes global exploration. We demonstrate that FARMap replicates the fragmentation points observed in animal studies. We evaluate FARMap on complex procedurally-generated spatial environments and realistic simulations to demonstrate that this mapping strategy much more rapidly covers the environment (number of agent steps and wall clock time) and is more efficient in active memory usage, without loss of performance.
In the last decades, the capacity to generate large amounts of data in science and engineering applications has been growing steadily. Meanwhile, machine learning has progressed to become a suitable tool to process and utilise the available data. Nonetheless, many relevant scientific and engineering problems present challenges where current machine learning methods cannot yet efficiently leverage the available data and resources. For example, in scientific discovery, we are often faced with the problem of exploring very large, structured and high-dimensional spaces. Moreover, the high fidelity, black-box objective function is often very expensive to evaluate. Progress in machine learning methods that can efficiently tackle such challenges would help accelerate currently crucial areas such as drug and materials discovery. In this paper, we propose a multi-fidelity active learning algorithm with GFlowNets as a sampler, to efficiently discover diverse, high-scoring candidates where multiple approximations of the black-box function are available at lower fidelity and cost. Our evaluation on molecular discovery tasks shows that multi-fidelity active learning with GFlowNets can discover high-scoring candidates at a fraction of the budget of its single-fidelity counterpart while maintaining diversity, unlike RL-based alternatives. These results open new avenues for multi-fidelity active learning to accelerate scientific discovery and engineering design.

Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key real-world aspects that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type I and type II errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset; and iii) not dealing with human work-capacity constraints. To address these issues, we propose the \textit{deferral under cost and capacity constraints framework} (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost, subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work-capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average $8.4\%$ reduction in the misclassification cost. The code used for the experiments is available at https://github.com/feedzai/deccaf

Deep convolutional neural networks (CNNs) have achieved impressive performance in many computer vision tasks. However, their large model sizes require heavy computational resources, making pruning redundant filters from existing pre-trained CNNs an essential task in developing efficient models for resource-constrained devices. Whole-network filter pruning algorithms prune varying fractions of filters from each layer, hence providing greater flexibility. State-of-the-art whole-network pruning methods are either computationally expensive due to the need to calculate the loss for each pruned filter using a training dataset, or use various heuristic / learned criteria for determining the pruning fractions for each layer. Hence there is a need for a simple and efficient technique for whole network pruning. This paper proposes a two-level hierarchical approach for whole-network filter pruning which is efficient and uses the classification loss as the final criterion. The lower-level algorithm (called filter-pruning) uses a sparse-approximation formulation based on linear approximation of filter weights. We explore two algorithms: orthogonal matching pursuit-based greedy selection and a greedy backward pruning approach. The backward pruning algorithm uses a novel closed-form error criterion for efficiently selecting the optimal filter at each stage, thus making the whole algorithm much faster. The higher-level algorithm (called layer-selection) greedily selects the best-pruned layer (pruning using the filter-selection algorithm) using a global pruning criterion. We propose algorithms for two different global-pruning criteria: (1) layerwise-relative error (HBGS), and (2) final classification error (HBGTS). Our suite of algorithms outperforms state-of-the-art pruning methods on ResNet18, ResNet32, ResNet56, VGG16, and ResNext101. Our method reduces the RAM requirement for ResNext101 from 7.6 GB to 1.5 GB and achieves a 94% reduction in FLOPS without losing accuracy on CIFAR-10.

Large language models (LLMs) are routinely pre-trained on billions of tokens, only to start the process over again once new data becomes available. A much more efficient solution is to continually pre-train these models—saving significant compute compared to re-training. However, the distribution shift induced by new data typically results in degraded performance on previous data or poor adaptation to the new data. In this work, we show that a simple and scalable combination of learning rate (LR) re-warming, LR re-decaying, and replay of previous data is sufficient to match the performance of fully re-training from scratch on all available data, as measured by the final loss and the average score on several language model (LM) evaluation benchmarks. Specifically, we show this for a weak but realistic distribution shift between two commonly used LLM pre-training datasets (English$\rightarrow$English) and a stronger distribution shift (English$\rightarrow$German) at the $405$M parameter model scale with large dataset sizes (hundreds of billions of tokens). Selecting the weak but realistic shift for larger-scale experiments, we also find that our continual learning strategies match the re-training baseline for a 10B parameter LLM. Our results demonstrate that autoregressive transformer-based LLMs can be successfully updated via simple and scalable continual learning strategies, matching the re-training baseline using only a fraction of the compute. Finally, inspired by previous work, we propose alternatives to the cosine learning rate schedule that help circumvent forgetting induced by LR re-warming and that are not bound to a fixed token budget.

Simulation-based inference techniques are indispensable for parameter estimation of mechanistic and simulable models with intractable likelihoods. While traditional statistical approaches like approximate Bayesian computation and Bayesian synthetic likelihood have been studied under well-specified and misspecified settings, they often suffer from inefficiencies due to wasted model simulations. Neural approaches, such as sequential neural likelihood (SNL) avoid this wastage by utilising all model simulations to train a neural surrogate for the likelihood function. However, the performance of SNL under model misspecification is unreliable and can result in overconfident posteriors centred around an inaccurate parameter estimate. In this paper, we propose a novel SNL method, which through the incorporation of additional adjustment parameters, is robust to model misspecification and capable of identifying features of the data that the model is not able to recover. We demonstrate the efficacy of our approach through several illustrative examples, where our method gives more accurate point estimates and uncertainty quantification than SNL.

In this paper, we propose a novel optimization algorithm for training machine learning models called Input Normalized Stochastic Gradient Descent (INSGD), inspired by the Normalized Least Mean Squares (NLMS) algorithm used in adaptive filtering. When training complex models on large datasets, choosing optimizer parameters, particularly the learning rate, is crucial to avoid divergence. Our algorithm updates the network weights using stochastic gradient descent with $\ell_1$ and $\ell_2$-based normalizations applied to the learning rate, similar to NLMS. However, unlike existing normalization methods, we exclude the error term from the normalization process and instead normalize the update term using the input vector to the neuron. Our experiments demonstrate that our optimization algorithm achieves higher accuracy levels compared to different initialization settings. We evaluate the efficiency of our training algorithm on benchmark datasets using a toy neural network and several mature modern deep networks including ResNet-20, ResNet-50, MobileNetV3, WResNet-18, and Vision Transformer. Our INSGD algorithm improves ResNet-20's CIFAR-10 test accuracy from 92.57\% to 92.67\%, MobileNetV3's CIFAR-10 test accuracy from 90.83\% to 91.13\%, WResNet-18 on CIFAR-100 from 78.24\% to 78.47\%, and ResNet-50's accuracy on ImageNet-1K validation dataset from 75.60\% to 75.92\%.

Active Learning (AL) is a user-interactive approach aimed at reducing annotation costs by selecting the most crucial examples to label. Although AL has been extensively studied for image classification tasks, the specific scenario of interactive image retrieval has received relatively little attention. This scenario presents unique characteristics, including an open-set and class-imbalanced binary classification, starting with very few labeled samples. We introduce a novel batch-mode Active Learning framework named GAL (Greedy Active Learning) that better copes with this application. It incorporates new acquisition functions for sample selection that measure the impact of each unlabeled sample on the classifier. We further embed this strategy in a greedy selection approach, better exploiting the samples within each batch. We evaluate our framework with both linear (SVM) and non-linear MLP/Gaussian Process classifiers. For the Gaussian Process case, we show a theoretical guarantee on the greedy approximation. Finally, we assess our performance for the interactive content-based image retrieval task on several benchmarks and demonstrate its superiority over existing approaches and common baselines. Code is available at https://github.com/barleah/GreedyAL.

Disentangled representations are those in which distinct features, such as size or shape, are represented by distinct neurons. Quantifying the extent to which a given representation is disentangled is not straightforward; multiple metrics have been proposed. In this paper, we identify two failings of existing metrics, which mean they can assign a high score to a model which is still entangled, and we propose two new metrics, which redress these problems. First, we use hypothetical toy examples to demonstrate the failure modes we identify for existing metrics. Then, we show that similar situations occur in practice. Finally, we validate our metrics on the downstream task of compositional generalization. We measure the performance of six existing disentanglement models on this downstream compositional generalization task, and show that performance is (a) generally quite poor, (b) correlated, to varying degrees, with most disentanglement metrics, and (c) most strongly correlated with our newly proposed metrics. Anonymous code to reproduce our results is available at https://github.com/anon296/anon.

In this paper, we address the problem of capturing graph directionality using transformers. Most existing graph transformers typically capture distances between graph nodes and do not take edge direction into account. This is a limiting assumption since many graph applications need to exploit sophisticated relationships in graph data, such as time, causality, or generic dependency constraints. We introduce a novel graph transformer architecture that explicitly takes into account the directionality between connected graph nodes. To achieve this, we make use of dual encodings to represent both potential roles, i.e., source or target, of each pair of vertices linked by a directed edge. These encodings are learned by leveraging the latent adjacency information extracted from a directional attention module, localized with $k$-hop neighborhood information. Extensive experiments on synthetic and real graph datasets show that our approach can have significant accuracy gains over previous graph transformer (GT) and graph neural network (GNN) approaches, providing state-of-the-art (SOTA) results on inherently directed graphs.

Continual learning research has shown that neural networks suffer from catastrophic forgetting "at the output level", but it is debated whether this is also the case at the level of learned representations. Multiple recent studies ascribe representations a certain level of innate robustness against forgetting - that they only forget minimally in comparison with forgetting at the output level. We revisit and expand upon the experiments that revealed this difference in forgetting and illustrate the coexistence of two phenomena that affect the quality of continually learned representations: knowledge accumulation and feature forgetting. Taking both aspects into account, we show that, even though forgetting in the representation (i.e. feature forgetting) can be small in absolute terms, when measuring relative to how much was learned during a task, forgetting in the representation tends to be just as catastrophic as forgetting at the output level. Next we show that this feature forgetting is problematic as it substantially slows down the incremental learning of good general representations (i.e. knowledge accumulation). Finally, we study how feature forgetting and knowledge accumulation are affected by different types of continual learning methods.

Decentralized learning enables serverless training of deep neural networks (DNNs) in a distributed manner on multiple nodes. One of the key challenges with decentralized learning is heterogeneity in the data distribution across the nodes. Data heterogeneity results in slow and unstable global convergence and therefore poor generalization performance. In this paper, we propose In-Distribution Knowledge Distillation (IDKD) to address the challenge of heterogeneous data distribution. The goal of IDKD is to homogenize the data distribution across the nodes. While such data homogenization can be achieved by exchanging data among the nodes sacrificing privacy, IDKD achieves the same objective using a common public dataset across nodes without breaking the privacy constraint. This public dataset is different from the training dataset and is used to distill the knowledge from each node and communicate it to its neighbors through the generated labels. With traditional knowledge distillation, the generalization of the distilled model is reduced due to misalignment between the private and public data distribution. Thus, we introduce an Out-of-Distribution (OoD) detector at each node to label a subset of the public dataset that maps close to the local training data distribution. Our experiments on multiple image classification datasets and graph topologies show that the proposed IDKD scheme is more effective than traditional knowledge distillation and achieves state-of-the-art generalization performance on heterogeneously distributed data with minimal communication overhead.

This paper addresses the problem of decentralized cooperative monitoring of an agile target using a swarm of robots undergoing dynamic sensor failures. Each robot is equipped with a proprioceptive sensor suite for the estimation of its own pose and an exteroceptive sensor suite for target detection and position estimation with a limited field of view. Further, the robots use broadcast-based communication modules with a limited communication radius and bandwidth. The uncertainty in the system and the environment can lead to intermittent communication link drops, target visual loss, and large biases in the sensors’ estimation output due to temporary or permanent failures. Robotic swarms often operate without leaders, supervisors, or landmarks, i.e., without the availability of ground truth regarding pose information. In such scenarios, each robot is required to exhibit autonomous learning by taking charge of its own learning process while making the most out of available information. In this regard, a novel Autonomous Online Learning (AOL) framework has been proposed, in which a decentralized online learning mechanism driven by reward-like signals, is intertwined with an implicit adaptive consensus-based, two-layered, weighted information fusion process that utilizes the robots’ observations and their shared information, thereby ensuring resilience in the robotic swarm. In order to study the effect of loss or reward design in the local and social learning layers, three AOL variants are presented. A novel perturbation-greedy reward design is introduced in the learning layers of two variants, leading to exploration-exploitation in their information fusion's weights' space. Convergence analysis of the weights is carried out, showing that the weights converge under reasonable assumptions. Simulation results show that the AOL variant using the perturbation-greedy reward in its local learning layer performs the best, doing $182.2\%$ to $652\%$ and $94.7\%$ to $150.4\%$ better than the baselines in terms of detection score and closeness score per robot, respectively, as the total number of robots is increased from $5$ to $30$. Further, AOL's Sim2Real implementation has been validated using a ROS-Gazebo setup.

This paper seeks to reproduce and extend the results of the paper “Explaining Temporal Graph Models Through an Explorer-Navigator Framework” by (Xia et al., 2023). The main contribution of the original authors is a novel explainer for temporal graph networks, the Temporal GNN Explainer (T-GNNExplainer), which finds a subset of preceding events that “explain” a prediction made by a temporal graph model. The explorer is tested on two temporal graph models that are trained on two real-world and two synthetic datasets. The explorer is evaluated using a newly proposed metric for explanatory graph models. The authors compare the performance of their explorer to three baseline explainer methods, either adapted from a GNN explainer or developed by the authors. The authors claim that T-GNNExplainer achieves superior performance compared to the baselines when evaluated with their proposed metric. This work reproduces the original experiments by using the code (with minor adjustments), model specifications, and hyperparameters provided by the original authors. To evaluate the robustness of these claims, the method was extended to one new dataset (MOOC). Results show that the T-GNNexplainer performs best on some, but not all metrics as reported in the original findings. We conclude that the main lines of this paper hold up even though all results are less pronounced than claimed. Results show that the T-GNNExplainer does not perform similarly across different T-GNN models, precise dataset specifications are needed to obtain high performance, and there are simpler, less computationally costly explainer methods (like PBONE) that could offer competitive results.

We propose NeuFace, a 3D face mesh pseudo annotation method on videos via neural re-parameterized optimization. Despite the huge progress in 3D face reconstruction methods, generating reliable 3D face labels for in-the-wild dynamic videos remains challenging. Using NeuFace optimization, we annotate the per-view/-frame accurate and consistent face meshes on large-scale face videos, called the NeuFace-dataset. We investigate how neural re-parameterization helps to reconstruct image-aligned facial details on 3D meshes via gradient analysis. By exploiting the naturalness and diversity of 3D faces in our dataset, we demonstrate the usefulness of our dataset for 3D face-related tasks: improving the reconstruction accuracy of an existing 3D face reconstruction model and learning 3D facial motion prior.

Continual learning (CL) remains one of the long-standing challenges for deep neural networks due to catastrophic forgetting of previously acquired knowledge. Although rehearsal-based approaches have been fairly successful in mitigating catastrophic forgetting, they suffer from overfitting on buffered samples and prior information loss, hindering generalization under low-buffer regimes. Inspired by how humans learn using strong inductive biases, we propose \textbf{IMEX-Reg} to improve the generalization performance of experience rehearsal in CL under low buffer regimes. Specifically, we employ a two-pronged implicit-explicit regularization approach using contrastive representation learning (CRL) and consistency regularization. To further leverage the global relationship between representations learned using CRL, we propose a regularization strategy to guide the classifier toward the activation correlations in the unit hypersphere of the CRL. Our results show that IMEX-Reg significantly improves generalization performance and outperforms rehearsal-based approaches in several CL scenarios. It is also robust to natural and adversarial corruptions with less task-recency bias. Additionally, we provide theoretical insights to support our design decisions further.

We introduce the Lennard-Jones layer (LJL) for the equalization of the density of 2D and 3D point clouds through systematically rearranging points without destroying their overall structure (distribution normalization). LJL simulates a dissipative process of repulsive and weakly attractive interactions between individual points by considering the nearest neighbor of each point at a given moment in time. This pushes the particles into a potential valley, reaching a well-defined stable configuration that approximates an equidistant sampling after the stabilization process. We apply LJLs to redistribute randomly generated point clouds into a randomized uniform distribution. Moreover, LJLs are embedded in the generation process of point cloud networks by adding them at later stages of the inference process. The improvements in 3D point cloud generation utilizing LJLs are evaluated qualitatively and quantitatively. Finally, we apply LJLs to improve the point distribution of a score-based 3D point cloud denoising network. In general, we demonstrate that LJLs are effective for distribution normalization which can be applied at negligible cost without retraining the given neural network.

Pre-trained foundation models, due to their enormous capacity and exposure to vast amounts of data during pre-training, are known to have learned plenty of real-world concepts. An important step in making these pre-trained models effective on downstream tasks is to fine-tune them on related datasets. While various fine-tuning methods have been devised and have been shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks different from the downstream one is reduced significantly compared to its pre-trained counterpart. This is an undesirable effect of fine-tuning as a substantial amount of resources was used to learn these pre-trained concepts in the first place. We call this phenomenon "concept forgetting'' and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we propose a simple fix to this problem by designing a new fine-tuning method called LDIFS (short for $\ell_2$ distance in feature space) that, while learning new concepts related to the downstream task, allows a model to preserve its pre-trained knowledge as well. Through extensive experiments on 10 fine-tuning tasks we show that LDIFS significantly reduces concept forgetting. Additionally, we show that LDIFS is highly effective in performing continual fine-tuning on a sequence of tasks as well, in comparison with both fine-tuning as well as continual learning baselines.

Source-free domain adaptation (SFDA) involves adapting a model originally trained using a labeled dataset (source domain) to perform effectively on an unlabeled dataset (target domain) without relying on any source data during adaptation. This adaptation is especially crucial when significant disparities in data distributions exist between the two domains and when there are privacy concerns regarding the source model's training data. The absence of access to source data during adaptation makes it challenging to analytically estimate the domain gap. To tackle this issue, various techniques have been proposed, such as unsupervised clustering, contrastive learning, and continual learning. In this paper, we first conduct an extensive theoretical analysis of SFDA based on contrastive learning, primarily because it has demonstrated superior performance compared to other techniques. Motivated by the obtained insights, we then introduce a straightforward yet highly effective latent augmentation method tailored for contrastive SFDA. This augmentation method leverages the dispersion of latent features within the neighborhood of the query sample, guided by the source pre-trained model, to enhance the informativeness of positive keys. Our approach, based on a single InfoNCE-based contrastive loss, outperforms state-of-the-art SFDA methods on widely recognized benchmark datasets.

Advancements in accelerated physics simulations have greatly reduced training times for reinforcement learning policies, yet the conventional step-by-step agent-simulator interaction undermines simulation accuracy. In the real-world, interactions are asynchronous, with sensing, acting and processing happening simultaneously. Failing to capture this widens the sim2real gap and results in suboptimal real-world performance. In this paper, we address the challenges of simulating realistic asynchronicity and delays within parallelized simulations, crucial to bridging the sim2real gap in complex cyber-physical systems. Our approach efficiently parallelizes cyber-physical system simulations on accelerator hardware, including physics, sensors, actuators, processing components and their asynchronous interactions. We extend existing accelerated physics simulations with latency simulation capabilities by constructing a `supergraph' that encodes all data dependencies across parallelized simulation steps, ensuring accurate simulation. By finding the smallest supergraph, we minimize redundant computation. We validate our approach on two real-world systems and perform an extensive ablation, demonstrating superior performance compared to baseline methods.
In this paper, we propose FastDoc (Fast Continual Pre-training Technique using Document Level Metadata and Taxonomy), a novel, compute-efficient framework that utilizes Document metadata and Domain-Specific Taxonomy as supervision signals to continually pre-train transformer encoder on a domain-specific corpus. The main innovation is that during domain-specific pretraining, an open-domain encoder is continually pre-trained using sentence-level embeddings as inputs (to accommodate long documents), however, fine-tuning is done with token-level embeddings as inputs to this encoder. We perform such domain-specific pre-training on three different domains namely customer support, scientific, and legal domains, and compare performance on 6 different downstream tasks and 9 different datasets. The novel use of document-level supervision along with sentence-level embedding input for pre-training reduces pre-training compute by around 1,000, 4,500, and 500 times compared to MLM and/or NSP in Customer Support, Scientific, and Legal Domains, respectively. The reduced training time does not lead to a deterioration in performance. In fact we show that FastDoc either outperforms or performs on par with several competitive transformer-based baselines in terms of character-level F1 scores and other automated metrics in the Customer Support, Scientific, and Legal Domains. Moreover, reduced training aids in mitigating the risk of catastrophic forgetting. Thus, unlike baselines, FastDoc shows a negligible drop in performance on open domain.

Nonstationary phenomena, such as satiation effects in recommendations, have mostly been modeled using bandits with finitely many arms. However, the richer action space provided by linear bandits is often preferred in practice. In this work, we introduce a novel nonstationary linear bandit model, where current rewards are influenced by the learner's past actions in a fixed-size window. Our model, which recovers stationary linear bandits as a special case, leverages two parameters: the window size $m \ge 0$, and an exponent $\gamma$ that captures the rotting ($\gamma < 0)$ or rising ($\gamma > 0$) nature of the phenomenon. When both $m$ and $\gamma$ are known, we propose and analyze a variant of OFUL which minimizes regret against cyclic policies. By choosing the cycle length so as to trade-off approximation and estimation errors, we then prove a bound of order $\sqrt{d}\,(m+1)^{\frac{1}{2}+\max\{\gamma,0\}}\,T^{3/4}$ (ignoring log factors) on the regret against the optimal sequence of actions, where $T$ is the horizon and $d$ is the dimension of the linear action space. Through a bandit model selection approach, our results are then extended to the case where both $m$ and $\gamma$ are unknown. Finally, we complement our theoretical results with experiments comparing our approach to natural baselines.
We consider the best arm identification problem in a fixed budget stochastic multi-armed bandit in which arm means exhibit unimodal structure, i.e., there is only one local maximum. We establish that the probability of misidentifying the optimal arm within a budget of $T$ is lower bounded as $\mathcal{O}\left(\exp\left\{-T/\bar{H}\right\}\right)$, where $\bar{H}$ depends on the sub-optimality gaps of arms in the neighborhood of the optimal arm. % where $\bar{H}\leq 2\Delta^{-2}$. In contrast to the lower bound for the unstructured case, the error exponent in this bound does not depend on the number of arms $K$ and is smaller by a factor $\log K$, which captures the gain achievable by exploiting the unimodal structure. We then develop an algorithm named {\it Fixed Budget Best Arm Unimodal Bandits ( FB-BAUB)} that exploits unimodality to achieve the gain. Specifically, we show that the error probability of \algo{} is upper bounded as $\mathcal{O}\left(\log_2 K\exp\left\{-T\Delta^2\right\}\right)$, where $\Delta$ is the gap between the neighboring arms and $\bar{H}\leq 2\Delta^{-2}$. We demonstrate that \algo{} outperforms the state-of-the-art algorithms through extensive simulations. Moreover, \algo{} is parameter-free and simple to implement.

Most modern reinforcement learning algorithms optimize a cumulative single-step cost along a trajectory. The optimized motions are often ‘unnatural’, representing, for example, behaviors with sudden accelerations that waste energy and lack predictability. In this work, we present a novel paradigm of controlling nonlinear systems via the minimization of the Koopman spectrum cost: a cost over the Koopman operator of the controlled dynamics. This induces a broader class of dynamical behaviors that evolve over stable manifolds such as nonlinear oscillators, closed loops, and smooth movements. We demonstrate that some dynamics characterizations that are not possible with a cumulative cost are feasible in this paradigm, which generalizes the classical eigenstructure and pole assignments to nonlinear decision making. Moreover, we present a sample efficient online learning algorithm for our problem that enjoys a sub-linear regret bound under some structural assumptions.

Modern deep learning models have the ability to generate high-dimensional vectors whose similarity reflects semantic resemblance. Thus, similarity search, i.e., the operation of retrieving those vectors in a large collection that are similar to a given query, has become a critical component of a wide range of applications that demand highly accurate and timely answers. In this setting, the high vector dimensionality puts similarity search systems under compute and memory pressure, leading to subpar performance. Additionally, cross-modal retrieval tasks have become increasingly common, e.g., where a user inputs a text query to find the most relevant images for that query. However, these queries often have different distributions than the database embeddings, making it challenging to achieve high accuracy. In this work, we present LeanVec, a framework that combines linear dimensionality reduction with vector quantization to accelerate similarity search on high-dimensional vectors while maintaining accuracy. We present LeanVec variants for in-distribution (ID) and out-of-distribution (OOD) queries. LeanVec-ID yields accuracies on par with those from recently introduced deep learning alternatives whose computational overhead precludes their usage in practice. LeanVec-OOD uses a novel technique for dimensionality reduction that considers the query and database distributions to simultaneously boost the accuracy and the performance of the framework even further (even presenting competitive results when the query and database distributions match). All in all, our extensive and varied experimental results show that LeanVec produces state-of-the-art results, with up to 3.7x improvement in search throughput and up to 4.9x faster index build time over the state of the art.

We propose a strategy for training a wide range of graph neural networks (GNNs) under tight Lipschitz bound constraints. Specifically, by leveraging graph spectral theory, we derive computationally tractable expressions of a tight Lipschitz constant. This allows us to propose a constrained-optimization approach to control the constant, ensuring robustness to adversarial perturbations. Unlike the existing methods for controlling the Lipschitz constant, our approach reduces the size of the handled matrices by a factor equal to the square of the number of nodes in the graph. We employ a stochastic projected subgradient algorithm, which operates in a block-coordinate manner, with the projection step performed via an accelerated iterative proximal algorithm. We focus on defending against attacks that perturb features while keeping the topology of the graph constant. This contrasts with most of the existing defenses, which tackle perturbations of the graph structure. We report experiments on various datasets in the context of node classification tasks, showing the effectiveness of our constrained GNN model.

We release VisionAD, an anomaly detection library in the domain of images. The library forms the largest and most performant collection of such algorithms to date. Each algorithm is written through a standardised API, for ease of use. The library has a focus on fair benchmarking intended to mitigate the issue of cherry-picked results. It enables rapid experimentation and straightforward integration of new algorithms. In addition, we propose a new metric, Proportion Localised (PL). This reports the proportion of anomalies that are sufficiently localised via classifying each discrete anomaly as localised or not. The metric is far more intuitive as it has a real physical relation, meaning it is attractive to industry-based professionals. We also release the VisionADIndustrial (VADI) benchmark, a thorough benchmarking of the top anomaly detection algorithms. This benchmark calculates the mean across the pooled classes of the MVTec and VisA datasets. We are committed to hosting an updated version of this leaderboard online, and encourage researchers to add, tweak and improve algorithms to climb this leaderboard. VisionAD code is found at https://github.com/alext1995/VisionAD, and Proportion Localised code is found at https://github.com/alext1995/proportion_localised.

This work tackles the dynamic structure estimation problems for periodically behaved discrete dynamical system in the Euclidean space. We assume the observations become sequentially available in a form of bandit feedback contaminated by a sub-Gaussian noise. Under such fairly general assumptions on the noise distribution, we carefully identify a set of recoverable information of periodic structures. Our main results are the (computation and sample) efficient algorithms that exploit asymptotic behaviors of exponential sums to effectively average out the noise effect while preventing the information to be estimated from vanishing. In particular, the novel use of the Weyl sum, a variant of exponential sums, allows us to extract spectrum information for linear systems. We provide sample complexity bounds for our algorithms, and we experimentally validate our theoretical claims on simulations of toy examples, including Cellular Automata.

Enhancing the generalisation abilities of neural networks (NNs) through integrating noise such as MixUp or Dropout during training has emerged as a powerful and adaptable technique. Despite the proven efficacy of noise in NN training, there is no consensus regarding which noise sources, types and placements yield maximal benefits in generalisation and confidence calibration. This study thoroughly explores diverse noise modalities to evaluate their impacts on NN's generalisation and calibration under in-distribution or out-of-distribution settings, paired with experiments investigating the metric landscapes of the learnt representations, across a spectrum of NN architectures, tasks, and datasets. Our study shows that AugMix and weak augmentation exhibit cross-task effectiveness in computer vision, emphasising the need to tailor noise to specific domains. Our findings emphasise the efficacy of combining noises and successful hyperparameter transfer within a single domain but the difficulties in transferring the benefits to other domains. Furthermore, the study underscores the complexity of simultaneously optimising for both generalisation and calibration, emphasising the need for practitioners to carefully consider noise combinations and hyperparameter tuning for optimal performance in specific tasks and datasets.

We present a novel edge-level ego-network encoding for learning on graphs that can boost Message Passing Graph Neural Networks (MP-GNNs) by providing additional node and edge features or extending message-passing formats. The proposed encoding is sufficient to distinguish Strongly Regular Graphs, a family of challenging 3-WL equivalent graphs. We show theoretically that such encoding is more expressive than node-based sub-graph MP-GNNs. In an empirical evaluation on four benchmarks with 10 graph datasets, our results match or improve previous baselines on expressivity, graph classification, graph regression, and proximity tasks---while reducing memory usage by 18.1x in certain real-world settings.
Selective prediction aims to learn a reliable model that abstains from making predictions when uncertain. These predictions can then be deferred to humans for further evaluation. As an everlasting challenge for machine learning, in many real-world scenarios, the distribution of test data is different from the training data. This results in more inaccurate predictions, and often increased dependence on humans, which can be difficult and expensive. Active learning aims to lower the overall labeling effort, and hence human dependence, by querying the most informative examples. Selective prediction and active learning have been approached from different angles, with the connection between them missing. In this work, we introduce a new learning paradigm, active selective prediction, which aims to query more informative samples from the shifted target domain while increasing accuracy and coverage. For this new paradigm, we propose a simple yet effective approach, ASPEST, that utilizes ensembles of model snapshots with self-training with their aggregated outputs as pseudo labels. Extensive experiments on numerous image, text and structured datasets, which suffer from domain shifts, demonstrate that ASPEST can significantly outperform prior work on selective prediction and active learning (e.g. on the MNIST$\to$SVHN benchmark with the labeling budget of 100, ASPEST improves the AUACC metric from 79.36% to 88.84%) and achieves more optimal utilization of humans in the loop.

One of the primary objectives in modern artificial intelligence researches is to empower agents to effectively coordinate with diverse teammates, particularly human teammates. Previous studies focused on training agents either with a fixed population of pre-generated teammates or through the co-evolution of distinct populations of agents and teammates. However, it is challenging to enumerate all possible teammates in advance, and it is costly, or even impractical to maintain such a sufficiently diverse population and repeatedly interact with previously encountered teammates. Additional design considerations, such as prioritized sampling, are also required to ensure efficient training. To address these challenges and obtain an efficient human-AI coordination paradigm, we propose a novel approach called \textbf{Concord}. Considering that human participants tend to occur in a sequential manner, we model the training process with different teammates as a continual learning framework, akin to how humans learn and adapt in the real world. We propose a mechanism based on hyper-teammate identification to prevent catastrophic forgetting while promoting forward knowledge transfer. Concretely, we introduce a teammate recognition module that captures the identification of corresponding teammates. Leveraging the identification, a well-coordinated AI policy can be generated via the hyper-network. The entire framework is trained in a decomposed policy gradient manner, allowing for effective credit assignment among agents. This approach enables us to train agents with each generated teammate or humans one by one, ensuring that agents can coordinate effectively with concurrent teammates without forgetting previous knowledge. Our approach outperforms multiple baselines in various multi-agent benchmarks, either with generated human proxies or real human participants.
We present a comprehensive experimental study on pre-trained feature extractors for visual out-of-distribution (OOD) detection, focusing on leveraging contrastive language-image pre-trained (CLIP) models. Without fine-tuning on the training data, we are able to establish a positive correlation ($R^2\geq0.92$) between in-distribution classification and unsupervised OOD detection for CLIP models in $4$ benchmarks. We further propose a new simple and scalable method called \textit{pseudo-label probing} (PLP) that adapts vision-language models for OOD detection. Given a set of label names of the training set, PLP trains a linear layer using the pseudo-labels derived from the text encoder of CLIP. Intriguingly, we show that without modifying the weights of CLIP or training additional image/text encoders (i) PLP outperforms the previous state-of-the-art on all $5$ large-scale benchmarks based on ImageNet, specifically by an average AUROC gain of 3.4\% using the largest CLIP model (ViT-G), (ii) linear probing outperforms fine-tuning by large margins for CLIP architectures (i.e. CLIP ViT-H achieves a mean gain of 7.3\% AUROC on average on all ImageNet-based benchmarks), and (iii) billion-parameter CLIP models still fail at detecting feature-based adversarially manipulated OOD images. The code is available at https://github.com/HHU-MMBS/plp-official-tmlr2024.
Training at the edge utilizes continuously evolving data generated at different locations. Privacy concerns prohibit the co-location of this spatially as well as temporally distributed data, deeming it crucial to design training algorithms that enable efficient continual learning over decentralized private data. Decentralized learning allows serverless training with spatially distributed data. A fundamental barrier in such setups is the high bandwidth cost of communicating model updates between agents. Moreover, existing works under this training paradigm are not inherently suitable for learning a temporal sequence of tasks while retaining the previously acquired knowledge. In this work, we propose CoDeC, a novel communication-efficient decentralized continual learning algorithm that addresses these challenges. We mitigate catastrophic forgetting while learning a distributed task sequence by incorporating orthogonal gradient projection within a gossip-based decentralized learning algorithm. Further, CoDeC includes a novel lossless communication compression scheme based on the gradient subspaces. We theoretically analyze the convergence rate for our algorithm and demonstrate through an extensive set of experiments that CoDeC successfully learns distributed continual tasks with minimal forgetting. The proposed compression scheme results in up to 4.8× reduction in communication costs without any loss in performance.
Prior work on Private Inference (PI)---inferences performed directly on encrypted input---has focused on minimizing a network's ReLUs, which have been assumed to dominate PI latency rather than FLOPs. Recent work has shown that FLOPs for PI can no longer be ignored and incur high latency penalties. In this paper, we develop DeepReShape, a technique that optimizes neural network architectures under PI's constraints, optimizing for both ReLUs {\em and} FLOPs for the first time. The key insight is strategically allocating channels to position the network's ReLUs in order of their criticality to network accuracy, simultaneously optimizes ReLU and FLOPs efficiency. DeepReShape automates network development with an efficient process, and we call generated networks HybReNets. We evaluate DeepReShape using standard PI benchmarks and demonstrate a 2.1% accuracy gain with a 5.2$\times$ runtime improvement at iso-ReLU on CIFAR-100 and an 8.7$\times$ runtime improvement at iso-accuracy on TinyImageNet. Furthermore, we investigate the significance of network selection in prior ReLU optimizations and shed light on the key network attributes for superior PI performance.

Recent advancements in text-to-image diffusion models have yielded impressive results in generating realistic and diverse images. However, these models still struggle with complex prompts, such as those that involve numeracy and spatial reasoning. This work proposes to enhance prompt understanding capabilities in diffusion models. Our method leverages a pretrained large language model (LLM) for grounded generation in a novel two-stage process. In the first stage, the LLM generates a scene layout that comprises captioned bounding boxes from a given prompt describing the desired image. In the second stage, a novel controller guides an off-the-shelf diffusion model for layout-grounded image generation. Both stages utilize existing pretrained models without additional model parameter optimization. Our method significantly outperforms the base diffusion model and several strong baselines in accurately generating images according to prompts that require various capabilities, doubling the generation accuracy across four tasks on average. Furthermore, our method enables instruction-based multi-round scene specification and can handle prompts in languages not supported by the underlying diffusion model. We anticipate that our method will unleash users' creativity by accurately following more complex prompts. Our code, demo, and benchmark are available at: https://llm-grounded-diffusion.github.io

We establish a connection between stochastic optimal control and generative models based on stochastic differential equations (SDEs), such as recently developed diffusion probabilistic models. In particular, we derive a Hamilton--Jacobi--Bellman equation that governs the evolution of the log-densities of the underlying SDE marginals. This perspective allows to transfer methods from optimal control theory to generative modeling. First, we show that the evidence lower bound is a direct consequence of the well-known verification theorem from control theory. Further, we can formulate diffusion-based generative modeling as a minimization of the Kullback--Leibler divergence between suitable measures in path space. Finally, we develop a novel diffusion-based method for sampling from unnormalized densities -- a problem frequently occurring in statistics and computational sciences. We demonstrate that our time-reversed diffusion sampler (DIS) can outperform other diffusion-based sampling approaches on multiple numerical examples.
In some settings neural networks exhibit a phenomenon known as \textit{grokking}, where they achieve perfect or near-perfect accuracy on the validation set long after the same performance has been achieved on the training set. In this paper, we discover that grokking is not limited to neural networks but occurs in other settings such as Gaussian process (GP) classification, GP regression, linear regression and Bayesian neural networks. We also uncover a mechanism by which to induce grokking on algorithmic datasets via the addition of dimensions containing spurious information. The presence of the phenomenon in non-neural architectures shows that grokking is not restricted to settings considered in current theoretical and empirical studies. Instead, grokking may be possible in any model where solution search is guided by complexity and error.

When analyzing real-world data it is common to work with event ensembles, which comprise sets of observations that collectively constrain the parameters of an underlying model of interest. Such models often have a hierarchical structure, where ``local'' parameters impact individual events and ``global'' parameters influence the entire dataset. We introduce practical approaches for frequentist and Bayesian dataset-wide probabilistic inference in cases where the likelihood is intractable, but simulations can be realized via a hierarchical forward model. We construct neural estimators for the likelihood(-ratio) or posterior and show that explicitly accounting for the model's hierarchical structure can lead to significantly tighter parameter constraints. We ground our discussion using case studies from the physical sciences, focusing on examples from particle physics and cosmology.
This paper presents Predictive Pipelined Decoding (PPD), an approach that speeds up decoding in Large Language Models (LLMs) while maintaining the exact same output as the original decoding. Unlike conventional strategies, PPD employs additional compute resources to parallelize the initiation of subsequent token decoding during the current token decoding. This method reduces decoding latency and reshapes the understanding of trade-offs in LLM decoding strategies. We have developed a theoretical framework that allows us to analyze the trade-off between computation and latency. Using this framework, we can analytically estimate the potential reduction in latency associated with our proposed method, achieved through the assessment of the match rate, represented as $p_\text{correct}$. The results demonstrate that the use of extra computational resources has the potential to accelerate LLM decoding. Additionally, we implement PPD and conduct preliminary experiments to empirically validate its efficacy, addressing potential practical overheads not covered by theoretical analysis.

Compact and energy-efficient models have become essential in this era when deep learning-based solutions are widely used for various real-life tasks. In this paper, we propose rotating the ReLU activation to give an additional degree of freedom in conjunction with the appropriate initialization of the rotation. This combination leads to implicit sparsification without the use of a regularizer. We show that this rotated ReLU (RReLU) activation improves the representation capability of the parameters/filters in the network and eliminates those parameters/filters that are not crucial for the task, giving rise to significant savings in memory and computation. While the state-of-the-art regularization-based Network-Slimming method achieves $32.33\%$ saving in memory and $26.38\%$ saving in computation with ResNet-$164$, RReLU achieves a saving of $35.92\%$ in memory and $25.97\%$ in the computation with a better accuracy. The savings in memory and computation further increase by $64.67\%$ and $52.96\%$, respectively, with the introduction of $L_1$ regularization to the RReLU slopes. We note that the slopes of the rotated ReLU activations act as coarse feature extractors and can eliminate unnecessary features before retraining. Our studies indicate that features always choose to pass through a lesser number of filters. We demonstrate the results with popular datasets such as MNIST, CIFAR-10, CIFAR-100, SVHN, and Imagenet with different architectures, including Vision Transformers and EfficientNet. We also briefly study the impact of adversarial attacks on RReLU-based ResNets and observe that we get better adversarial accuracy for the architectures with RReLU than ReLU. We also demonstrate how this concept of rotation can be applied to the GELU and SiLU activation functions, commonly utilized in Transformer and EfficientNet architectures, respectively. The proposed method can be utilized by combining with other structural pruning methods resulting in better sparsity. For the GELU-based multi-layer perceptron (MLP) part of the Transformer, we obtain $2.6\%$ improvement in accuracy with $6.32\%$ saving in both memory and computation.

We propose a new object-centric video prediction algorithm based on the deep latent particle (DLP) representation of Daniel and Tamar (2022). In comparison to existing slot- or patch-based representations, DLPs model the scene using a set of keypoints with learned parameters for properties such as position and size, and are both efficient and interpretable. Our method, \textit{deep dynamic latent particles} (DDLP), yields state-of-the-art object-centric video prediction results on several challenging datasets. The interpretable nature of DDLP allows us to perform ``what-if'' generation -- predict the consequence of changing properties of objects in the initial frames, and DLP's compact structure enables efficient diffusion-based unconditional video generation. Videos, code and pre-trained models are available: https://taldatech.github.io/ddlp-web

A common approach to program synthesis is to use a learned function to guide the search for a program that satisfies the user's intent. In this paper, we propose a method that offers search guidance, through a domain-dependent auxiliary function, that can be orthogonal to the guidance previous functions provide. Our method, which we call Auxiliary-Based Library Learning (Aulile), searches for a solution in the program space using a base algorithm. If this search does not produce a solution, Aulile enhances the language with a library of programs discovered in the search that optimizes for the auxiliary function. Then, it repeats the search with this library-augmented language. This process is repeated until a solution is found or the system reaches a timeout. We evaluate Aulile in string manipulation tasks. Aulile improved, in some cases by a large margin, the performance of several base algorithms that use different search and learning strategies: Bus, Bustle, Crossbeam, and Bee Search. Our results suggest that Aulile offers an effective method of injecting domain knowledge into existing systems through a library learning scheme that optimizes for an auxiliary function.
Persistent homology (PH) is a method for generating topology-inspired representations of data. Empirical studies that investigate the properties of PH, such as its sensitivity to perturbations or ability to detect a feature of interest, commonly rely on training and testing an additional model on the basis of the PH representation. To gain more intrinsic insights about PH, independently of the choice of such a model, we propose a novel methodology based on the pull-back geometry that a PH encoding induces on the data manifold. The spectrum and eigenvectors of the induced metric help to identify the most and least significant information captured by PH. Furthermore, the pull-back norm of tangent vectors provides insights about the sensitivity of PH to a given perturbation, or its potential to detect a given feature of interest, and in turn its ability to solve a given classification or regression problem. Experimentally, the insights gained through our methodology align well with the existing knowledge about PH. Moreover, we show that the pull-back norm correlates with the performance on downstream tasks, and can therefore guide the choice of a suitable PH encoding.

Representation similarity metrics are widely used to compare learned representations in neural networks, as is evident in extensive literature investigating metrics that accurately capture information encoded in representations. However, aiming to capture all of the information available in representations may have little to do with what information is actually used by the downstream network. One solution is to experiment with interventions on network function. By ablating groups of units thought to carry information and observing whether those ablations affect network performance, we can focus on an outcome that mechanistically links representations to function. In this paper, we systematically test representation similarity metrics to evaluate their sensitivity to functional changes induced by ablation. We use network performance changes after ablation as a way to measure the influence of representation on function. These measures of function allow us to test how well similarity metrics capture changes in network performance versus changes to linear decodability. Network performance measures index the information used by the downstream network, while linear decoding methods index available information in the representation. We show that all of the tested metrics are more sensitive to decodable features than network performance. When comparing these metrics, Procrustes and CKA outperform regularized CCA-based methods on average. Although Procrustes and CKA outperform on average, these metrics have a diminished advantage when looking at network performance. We provide ablation tests of the utility of different representational similarity metrics. Our results suggest that interpretability methods will be more effective if they are based on representational similarity metrics that have been evaluated using ablation tests.

The \emph{Path-Dependent Neural Jump Ordinary Differential Equation (PD-NJ-ODE)} is a model for predicting continuous-time stochastic processes with irregular and incomplete observations. In particular, the method learns optimal forecasts given irregularly sampled time series of incomplete past observations. So far the process itself and the coordinate-wise observation times were assumed to be independent and observations were assumed to be noiseless. In this work we discuss two extensions to lift these restrictions and provide theoretical guarantees as well as empirical examples for them. In particular, we can lift the assumption of independence by extending the theory to much more realistic settings of conditional independence without any need to change the algorithm. Moreover, we introduce a new loss function, which allows us to deal with noisy observations and explain why the previously used loss function did not lead to a consistent estimator.

In this note, we demonstrate a first-of-its-kind provable convergence of SGD to the global minima of appropriately regularized logistic empirical risk of depth $2$ nets -- for arbitrary data with any number of gates with adequately smooth and bounded activations, like sigmoid and tanh, and for a class of distributions from which the initial weight is sampled. We also prove an exponentially fast convergence rate for continuous time SGD that also applies to smooth unbounded activations like SoftPlus. Our key idea is to show that the logistic loss function on any size neural net can be Frobenius norm regularized by a width-independent parameter such that the regularized loss is a ``Villani function'' -- and thus be able to build on recent progress with analyzing SGD on such objectives.
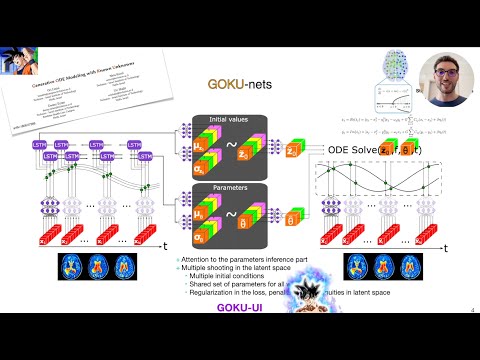
Scientific Machine Learning (SciML) is a burgeoning field that synergistically combines domain-aware and interpretable models with agnostic machine learning techniques. In this work, we introduce GOKU-UI, an evolution of the SciML generative model GOKU-nets. GOKU-UI not only broadens the original model's spectrum to incorporate other classes of differential equations, such as Stochastic Differential Equations (SDEs), but also integrates attention mechanisms and a novel multiple shooting training strategy in the latent space. These modifications have led to a significant increase in its performance in both reconstruction and forecast tasks, as demonstrated by our evaluation on simulated and empirical data. Specifically, GOKU-UI outperformed all baseline models on synthetic datasets even with a training set 16-fold smaller, underscoring its remarkable data efficiency. Furthermore, when applied to empirical human brain data, while incorporating stochastic Stuart-Landau oscillators into its dynamical core, our proposed enhancements markedly increased the model's effectiveness in capturing complex brain dynamics. GOKU-UI demonstrated a reconstruction error five times lower than other baselines, and the multiple shooting method reduced the GOKU-nets prediction error for future brain activity up to 15 seconds ahead. By training GOKU-UI on resting state fMRI data, we encoded whole-brain dynamics into a latent representation, learning a low-dimensional dynamical system model that could offer insights into brain functionality and open avenues for practical applications such as the classification of mental states or psychiatric conditions. Ultimately, our research provides further impetus for the field of Scientific Machine Learning, showcasing the potential for advancements when established scientific insights are interwoven with modern machine learning.

Existing convolutional neural network architectures frequently rely upon batch normalization (BatchNorm) to effectively train the model. BatchNorm, however, performs poorly with small batch sizes, and is inapplicable to differential privacy. To address these limitations, we propose the kernel normalization (KernelNorm) and kernel normalized convolutional layers, and incorporate them into kernel normalized convolutional networks (KNConvNets) as the main building blocks. We implement KNConvNets corresponding to the state-of-the-art ResNets while forgoing the BatchNorm layers. Through extensive experiments, we illustrate that KNConvNets achieve higher or competitive performance compared to the BatchNorm counterparts in image classification and semantic segmentation. They also significantly outperform their batch-independent competitors including those based on layer and group normalization in non-private and differentially private training. Given that, KernelNorm combines the batch-independence property of layer and group normalization with the performance advantage of BatchNorm.

Neural networks produced by standard training are known to suffer from poor accuracy on rare subgroups despite achieving high accuracy on average, due to the correlations between certain spurious features and labels. Previous approaches based on worst-group loss minimization (e.g. Group-DRO) are effective in improving worse-group accuracy but require expensive group annotations for all the training samples. In this paper, we focus on the more challenging and realistic setting where group annotations are only available on a small validation set or are not available at all. We propose BAM, a novel two-stage training algorithm: in the first stage, the model is trained using a bias amplification scheme via introducing a learnable auxiliary variable for each training sample; in the second stage, we upweight the samples that the bias-amplified model misclassifies, and then continue training the same model on the reweighted dataset. Empirically, BAM achieves competitive performance compared with existing methods evaluated on spurious correlation benchmarks in computer vision and natural language processing. Moreover, we find a simple stopping criterion based on minimum class accuracy difference that can remove the need for group annotations, with little or no loss in worst-group accuracy. We perform extensive analyses and ablations to verify the effectiveness and robustness of our algorithm in varying class and group imbalance ratios.

We study the unbalanced optimal transport (UOT) problem, where the marginal constraints are enforced using Maximum Mean Discrepancy (MMD) regularization. Our work is motivated by the observation that the literature on UOT is focused on regularization based on $\phi$-divergence (e.g., KL divergence). Despite the popularity of MMD, its role as a regularizer in the context of UOT seems less understood. We begin by deriving a specific dual of MMD-regularized UOT (MMD-UOT), which helps us prove several useful properties. One interesting outcome of this duality result is that MMD-UOT induces novel metrics, which not only lift the ground metric like the Wasserstein but are also sample-wise efficient to estimate like the MMD. Further, for real-world applications involving non-discrete measures, we present an estimator for the transport plan that is supported only on the given ($m$) samples. Under certain conditions, we prove that the estimation error with this finitely-supported transport plan is also $\mathcal{O}(1/\sqrt{m})$. As far as we know, such error bounds that are free from the curse of dimensionality are not known for $\phi$-divergence regularized UOT. Finally, we discuss how the proposed estimator can be computed efficiently using accelerated gradient descent. Our experiments show that MMD-UOT consistently outperforms popular baselines, including KL-regularized UOT and MMD, in diverse machine learning applications.

Envision an intelligent agent capable of assisting users in conducting forecasting tasks through intuitive, natural conversations, without requiring in-depth knowledge of the underlying machine learning (ML) processes. A significant challenge for the agent in this endeavor is to accurately comprehend the user's prediction goals and, consequently, formulate precise ML tasks. In this paper, we take a pioneering step towards this ambitious goal by introducing a new concept called Forecast Utterance and then focus on the automatic and accurate interpretation of users' prediction goals from these utterances. Specifically, we frame the task as a slot-filling problem, where each slot corresponds to a specific aspect of the goal prediction task. We then employ two zero-shot methods for solving the slot-filling task, namely: 1) Entity Extraction (EE), and 2) Question-Answering (QA) techniques. Our experiments, evaluated with three meticulously crafted data sets, validate the viability of our ambitious goal and demonstrate the effectiveness of both EE and QA techniques in interpreting Forecast Utterances.
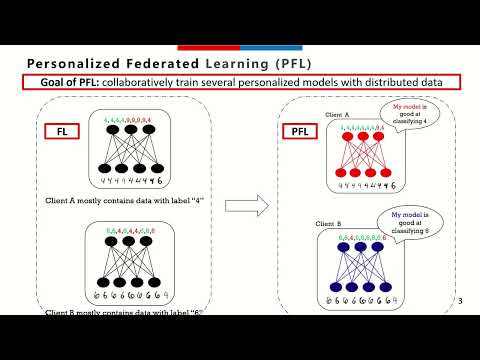
As a popular paradigm of distributed learning, personalized federated learning (PFL) allows personalized models to improve generalization ability and robustness by utilizing knowledge from all distributed clients. Most existing PFL algorithms tackle personalization in a model-centric way, such as personalized layer partition, model regularization, and model interpolation, which all fail to take into account the data characteristics of distributed clients. In this paper, we propose a novel PFL framework for image classification tasks, dubbed pFedPT, that leverages personalized visual prompts to implicitly represent local data distribution information of clients and provides that information to the aggregation model to help with classification tasks. Specifically, in each round of pFedPT training, each client generates a local personalized prompt related to local data distribution. Then, the local model is trained on the input composed of raw data and a visual prompt to learn the distribution information contained in the prompt. During model testing, the aggregated model obtains client-specific knowledge of the data distributions based on the prompts, which can be seen as an adaptive fine-tuning of the aggregation model to improve model performances on different clients. Furthermore, the visual prompt can be added as an orthogonal method to implement personalization on the client for existing FL methods to boost their performance. Experiments on the CIFAR10 and CIFAR100 datasets show that pFedPT outperforms several state-of-the-art (SOTA) PFL algorithms by a large margin in various settings. The code is available at: https://github.com/hkgdifyu/pFedPT.
Test log-likelihood is commonly used to compare different models of the same data or different approximate inference algorithms for fitting the same probabilistic model. We present simple examples demonstrating how comparisons based on test log-likelihood can contradict comparisons according to other objectives. Specifically, our examples show that (i) approximate Bayesian inference algorithms that attain higher test log-likelihoods need not also yield more accurate posterior approximations and (ii) conclusions about forecast accuracy based on test log-likelihood comparisons may not agree with conclusions based on root mean squared error.

The A* algorithm is commonly used to solve NP-hard combinatorial optimization problems. When provided with a completely informed heuristic function, A* can solve such problems in time complexity that is polynomial in the solution cost and branching factor. In light of this fact, we examine a line of recent publications that propose fitting deep neural networks to the completely informed heuristic function. We assert that these works suffer from inherent scalability limitations since --- under the assumption of NP $\not \subseteq$ P/poly --- such approaches result in either (a) network sizes that scale super-polynomially in the instance sizes or (b) the accuracy of the fitted deep neural networks scales inversely with the instance sizes. Complementing our theoretical claims, we provide experimental results for three representative NP-hard search problems. The results suggest that fitting deep neural networks to informed heuristic functions requires network sizes that grow quickly with the problem instance size. We conclude by suggesting that the research community should focus on scalable methods for integrating heuristic search with machine learning, as opposed to methods relying on informed heuristic estimation.

Emergent communication, or emergent language, is the field of research which studies how human language-like communication systems emerge de novo in deep multi-agent reinforcement learning environments. The possibilities of replicating the emergence of a complex behavior like language have strong intuitive appeal, yet it is necessary to complement this with clear notions of how such research can be applicable to other fields of science, technology, and engineering. This paper comprehensively reviews the applications of emergent communication research across machine learning, natural language processing, linguistics, and cognitive science. Each application is illustrated with a description of its scope, an explication of emergent communication's unique role in addressing it, a summary of the extant literature working towards the application, and brief recommendations for near-term research directions.

Neural Persistence is a prominent measure for quantifying neural network complexity, proposed in the emerging field of topological data analysis in deep learning. In this work, however, we find both theoretically and empirically that the variance of network weights and spatial concentration of large weights are the main factors that impact neural persistence. Whilst this captures useful information for linear classifiers, we find that no relevant spatial structure is present in later layers of deep neural networks, making neural persistence roughly equivalent to the variance of weights. Additionally, the proposed averaging procedure across layers for deep neural networks does not consider interaction between layers. Based on our analysis, we propose an extension of the filtration underlying neural persistence to the whole neural network instead of single layers, which is equivalent to calculating neural persistence on one particular matrix. This yields our deep graph persistence measure, which implicitly incorporates persistent paths through the network and alleviates variance-related issues through standardisation. Code is available at https://github.com/ExplainableML/Deep-Graph-Persistence.

Large Language Models (LLMs) have made the ambitious quest for generalist agents significantly far from being a fantasy. A key hurdle for building such general models is the diversity and heterogeneity of tasks and modalities. A promising solution is unification, allowing the support of a myriad of tasks and modalities within one unified framework. While few large models (e.g., Flamingo (Alayrac et al. 2022)), trained on massive datasets, can support more than two modalities, current small to mid-scale unified models are still limited to 2 modalities, usually image-text or video-text. The question that we ask is: is it possible to build efficiently a unified model that can support all modalities? To answer this, we propose UnIVAL, a step further towards this ambitious goal. Without relying on fancy datasets sizes or models with billions of parameters, the ~ 0.25B parameter UnIVAL model goes beyond two modalities and unifies text, images, video, and audio into a single model. Our model is efficiently pretrained on many tasks, based on task balancing and multimodal curriculum learning. UnIVAL shows competitive performance to existing state-of-the-art approaches, across image and video-text tasks. The feature representations learned from image and video-text modalities, allows the model to achieve competitive performance when finetuned on audio-text tasks, despite not being pretrained on audio. Thanks to the unified model, we propose a novel study on multimodal model merging via weight interpolation of models trained on different multimodal tasks, showing their benefits in particular for out-of-distribution generalization. Finally, we motivate unification by showing the synergy between tasks. The model weights and code are available at: https://github.com/mshukor/UnIVAL.

Natural data observed in $\mathbb{R}^n$ is often constrained to an $m$-dimensional manifold $\mathcal{M}$, where $m < n$. This work focuses on the task of building theoretically principled generative models for such data. Current generative models learn $\mathcal{M}$ by mapping an $m$-dimensional latent variable through a neural network $f_\theta: \mathbb{R}^m \to \mathbb{R}^n$. These procedures, which we call pushforward models, incur a straightforward limitation: manifolds cannot in general be represented with a single parameterization, meaning that attempts to do so will incur either computational instability or the inability to learn probability densities within the manifold. To remedy this problem, we propose to model $\mathcal{M}$ as a neural implicit manifold: the set of zeros of a neural network. We then learn the probability density within $\mathcal{M}$ with a constrained energy-based model, which employs a constrained variant of Langevin dynamics to train and sample from the learned manifold. In experiments on synthetic and natural data, we show that our model can learn manifold-supported distributions with complex topologies more accurately than pushforward models.
In this paper, we propose a data based transformation for infinite-dimensional Gaussian processes and derive its limit theorem. For a clustering problem using mixture models, an appropriate modification of this transformation asymptotically leads to perfect separation of the populations under rather general conditions, except the scenario in which differences between clusters depend only on the locations; in which case our procedure is useless. Theoretical properties related to label consistency are studied for the k-means clustering algorithm when used on this transformed data. Good empirical performance of the proposed methodology is demonstrated using simulated as well as benchmark data sets, when compared with some popular parametric and nonparametric methods for such functional data.

Replay methods are known to be successful at mitigating catastrophic forgetting in continual learning scenarios despite having limited access to historical data. However, storing historical data is cheap in many real-world settings, yet replaying all historical data is often prohibited due to processing time constraints. In such settings, we propose that continual learning systems should learn the time to learn and schedule which tasks to replay at different time steps. We first demonstrate the benefits of our proposal by using Monte Carlo tree search to find a proper replay schedule, and show that the found replay schedules can outperform fixed scheduling policies when combined with various replay methods in different continual learning settings. Additionally, we propose a framework for learning replay scheduling policies with reinforcement learning. We show that the learned policies can generalize better in new continual learning scenarios compared to equally replaying all seen tasks, without added computational cost. Our study reveals the importance of learning the time to learn in continual learning, which brings current research closer to real-world needs.
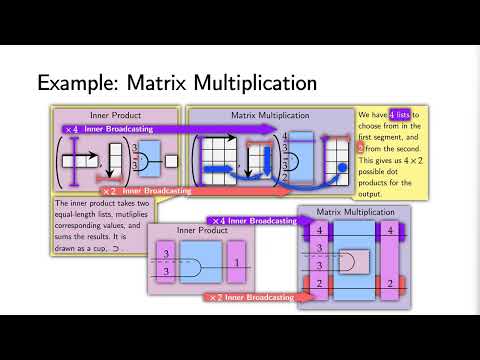
Diagrams matter. Unfortunately, the deep learning community has no standard method for diagramming architectures. The current combination of linear algebra notation and ad-hoc diagrams fails to offer the necessary precision to understand architectures in all their detail. However, this detail is critical for faithful implementation, mathematical analysis, further innovation, and ethical assurances. I present neural circuit diagrams, a graphical language tailored to the needs of communicating deep learning architectures. Neural circuit diagrams naturally keep track of the changing arrangement of data, precisely show how operations are broadcast over axes, and display the critical parallel behavior of linear operations. A lingering issue with existing diagramming methods is the inability to simultaneously express the detail of axes and the free arrangement of data, which neural circuit diagrams solve. Their compositional structure is analogous to code, creating a close correspondence between diagrams and implementation. In this work, I introduce neural circuit diagrams for an audience of machine learning researchers. After introducing neural circuit diagrams, I cover a host of architectures to show their utility and breed familiarity. This includes the transformer architecture, convolution (and its difficult-to-explain extensions), residual networks, the U-Net, and the vision transformer. I include a Jupyter notebook that provides evidence for the close correspondence between diagrams and code. Finally, I examine backpropagation using neural circuit diagrams. I show their utility in providing mathematical insight and analyzing algorithms' time and space complexities.

The ubiquity of missing values in real-world datasets poses a challenge for statistical inference and can prevent similar datasets from being analyzed in the same study, precluding many existing datasets from being used for new analyses. While an extensive collection of packages and algorithms have been developed for data imputation, the overwhelming majority perform poorly if there are many missing values and low sample sizes, which are unfortunately common characteristics in empirical data. Such low-accuracy estimations adversely affect the performance of downstream statistical models. We develop a statistical inference framework for predicting the target variable in the presence of missing data without imputation. Our framework, RIFLE (Robust InFerence via Low-order moment Estimations), estimates low-order moments of the underlying data distribution with corresponding confidence intervals to learn a distributionally robust model. We specialize our framework to linear regression and normal discriminant analysis, and we provide convergence and performance guarantees. This framework can also be adapted to impute missing data. We compare RIFLE with state-of-the-art approaches (including MICE, Amelia, MissForest, KNN-imputer, MIDA, and Mean Imputer) in numerical experiments. Our experiments demonstrate that RIFLE outperforms other benchmark algorithms when the percentage of missing values is high and/or when the number of data points is relatively small. RIFLE is publicly available
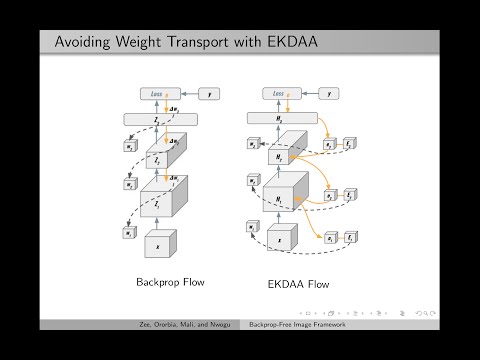
While current deep learning algorithms have been successful for a wide variety of artificial intelligence (AI) tasks, including those involving structured image data, they present deep neurophysiological conceptual issues due to their reliance on the gradients that are computed by backpropagation of errors (backprop). Gradients are required to obtain synaptic weight adjustments but require knowledge of feed forward activities in order to conduct backward propagation, a biologically implausible process. This is known as the "weight transport problem''. Therefore, in this work, we present a more biologically plausible approach towards solving the weight transport problem for image data. This approach, which we name the error-kernel driven activation alignment (EKDAA) algorithm, accomplishes through the introduction of locally derived error transmission kernels and error maps. Like standard deep learning networks, EKDAA performs the standard forward process via weights and activation functions; however, its backward error computation involves adaptive error kernels that propagate local error signals through the network. The efficacy of EKDAA is demonstrated by performing visual-recognition tasks on the Fashion MNIST, CIFAR-10 and SVHN benchmarks, along with demonstrating its ability to extract visual features from natural color images. Furthermore, in order to demonstrate its non-reliance on gradient computations, results are presented for an EKDAA-trained CNN that employs a non-differentiable activation function.

In learning tasks with label noise, improving model robustness against overfitting is a pivotal challenge because the model eventually memorizes labels, including the noisy ones. Identifying the samples with noisy labels and preventing the model from learning them is a promising approach to address this challenge. When training with noisy labels, the per-class confidence scores of the model, represented by the class probabilities, can be reliable criteria for assessing whether the input label is the true label or the corrupted one. In this work, we exploit this observation and propose a novel discriminator metric called confidence error and a sieving strategy called CONFES to differentiate between the clean and noisy samples effectively. We provide theoretical guarantees on the probability of error for our proposed metric. Then, we experimentally illustrate the superior performance of our proposed approach compared to recent studies on various settings, such as synthetic and real-world label noise. Moreover, we show CONFES can be combined with other state-of-the-art approaches, such as Co-teaching and DivideMix to further improve model performance.

Labor economists regularly analyze employment data by fitting predictive models to small, carefully constructed longitudinal survey datasets. Although machine learning methods offer promise for such problems, these survey datasets are too small to take advantage of them. In recent years large datasets of online resumes have also become available, providing data about the career trajectories of millions of individuals. However, standard econometric models cannot take advantage of their scale or incorporate them into the analysis of survey data. To this end we develop CAREER, a foundation model for job sequences. CAREER is first fit to large, passively-collected resume data and then fine-tuned to smaller, better-curated datasets for economic inferences. We fit CAREER to a dataset of 24 million job sequences from resumes, and adjust it on small longitudinal survey datasets. We find that CAREER forms accurate predictions of job sequences, outperforming econometric baselines on three widely-used economics datasets. We further find that CAREER can be used to form good predictions of other downstream variables. For example, incorporating CAREER into a wage model provides better predictions than the econometric models currently in use.

Artificial neural networks (ANNs) exhibit a narrow scope of expertise on stationary independent data. However, the data in the real world is continuous and dynamic, and ANNs must adapt to novel scenarios while also retaining the learned knowledge to become lifelong learners. The ability of humans to excel at these tasks can be attributed to multiple factors ranging from cognitive computational structures, cognitive biases, and the multi-memory systems in the brain. We incorporate key concepts from each of these to design a novel framework, Dual Cognitive Architecture (DUCA), which includes multiple sub-systems, implicit and explicit knowledge representation dichotomy, inductive bias, and a multi-memory system. DUCA shows improvement across different settings and datasets, and it also exhibits reduced task recency bias, without the need for extra information. To further test the versatility of lifelong learning methods on a challenging distribution shift, we introduce a novel domain-incremental dataset DN4IL. In addition to improving performance on existing benchmarks, DUCA also demonstrates superior performance on this complex dataset.
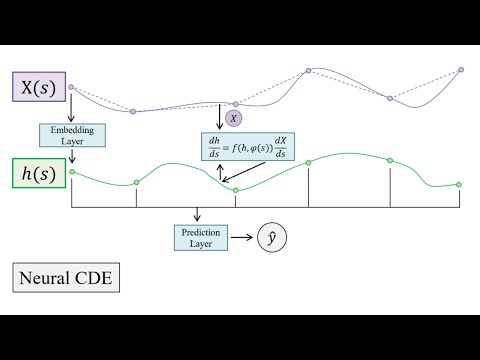
Multiple sclerosis is a disease that affects the brain and spinal cord, it can lead to severe disability and has no known cure. The majority of prior work in machine learning for multiple sclerosis has been centered around using Magnetic Resonance Imaging scans or laboratory tests; these modalities are both expensive to acquire and can be unreliable. In a recent paper it was shown that disease progression can be predicted effectively using performance outcome measures and demographic data. In our work we build on this to investigate the modeling side, using continuous time models to predict progression. We benchmark four continuous time models using a publicly available multiple sclerosis dataset. We find that the best continuous model is often able to outperform the best benchmarked discrete time model. We also carry out an extensive ablation to discover the sources of performance gains, we find that standardizing existing features leads to a larger performance increase than interpolating missing features.
This paper proposes the Doubly Compressed Momentum-assisted stochastic gradient tracking algorithm (DoCoM) for communication-efficient decentralized optimization. The algorithm features two main ingredients to achieve a near-optimal sample complexity while allowing for communication compression. First, the algorithm tracks both the averaged iterate and stochastic gradient using compressed gossiping consensus. Second, a momentum step is incorporated for adaptive variance reduction with the local gradient estimates. We show that DoCoM finds a near-stationary solution at all participating agents satisfying $\mathbb{E}[ \| \nabla f( \theta ) \|^2 ] = {\cal O}( 1 / T^{2/3} )$ in $T$ iterations, where $f(\theta)$ is a smooth (possibly non-convex) objective function. Notice that the proof is achieved via analytically designing a new potential function that tightly tracks the one-iteration progress of DoCoM. As a corollary, our analysis also established the linear convergence of DoCoM to a global optimal solution for objective functions with the Polyak-Łojasiewicz condition. Numerical experiments demonstrate that our algorithm outperforms several state-of-the-art algorithms in practice.

Neurally-parameterized Structural Causal Models in the Pearlian notion to causality, referred to as NCM, were recently introduced as a step towards next-generation learning systems. However, said NCM are only concerned with the learning aspect of causal inference and totally miss out on the architecture aspect. That is, actual causal inference within NCM is intractable in that the NCM won’t return an answer to a query in polynomial time. This insight follows as corollary to the more general statement on the intractability of arbitrary structural causal model (SCM) parameterizations, which we prove in this work through classical 3-SAT reduction. Since future learning algorithms will be required to deal with both high dimensional data and highly complex mechanisms governing the data, we ultimately believe work on tractable inference for causality to be decisive. We also show that not all “causal” models are created equal. More specifically, there are models capable of answering causal queries that are not SCM, which we refer to as partially causal models (PCM). We provide a tabular taxonomy in terms of tractability properties for all of the different model families, namely correlation-based, PCM and SCM. To conclude our work, we also provide some initial ideas on how to overcome parts of the intractability of causal inference with SCM by showing an example of how parameterizing an SCM with SPN modules can at least allow for tractable mechanisms. With this work we hope that our insights can raise awareness for this novel research direction since achieving success with causality in real world downstream tasks will not only depend on learning correct models but also require having the practical ability to gain access to model inferences.

Some argue scale is all what is needed to achieve AI, covering even causal models. We make it clear that large language models (LLMs) cannot be causal and give reason onto why sometimes we might feel otherwise. To this end, we define and exemplify a new subgroup of Structural Causal Model (SCM) that we call meta SCM which encode causal facts about other SCM within their variables. We conjecture that in the cases where LLM succeed in doing causal inference, underlying was a respective meta SCM that exposed correlations between causal facts in natural language on whose data the LLM was ultimately trained. If our hypothesis holds true, then this would imply that LLMs are like parrots in that they simply recite the causal knowledge embedded in the data. Our empirical analysis provides favoring evidence that current LLMs are even weak `causal parrots.'

We introduce meta-learning algorithms that perform zero-shot weight-space adaptation of neural network models to unseen tasks. Our methods repurpose the popular generative image synthesis techniques of natural language guidance and diffusion models to generate neural network weights adapted for tasks. We first train an unconditional generative hypernetwork model to produce neural network weights; then we train a second "guidance" model that, given a natural language task description, traverses the hypernetwork latent space to find high-performance task-adapted weights in a zero-shot manner. We explore two alternative approaches for latent space guidance: "HyperCLIP"-based classifier guidance and a conditional Hypernetwork Latent Diffusion Model ("HyperLDM"), which we show to benefit from the classifier-free guidance technique common in image generation. Finally, we demonstrate that our approaches outperform existing multi-task and meta-learning methods in a series of zero-shot learning experiments on our Meta-VQA dataset.
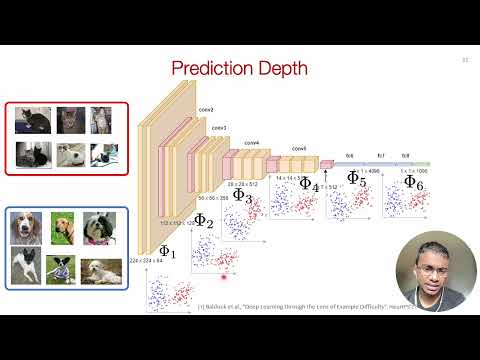
Deep Neural Networks (DNNs) are prone to learning spurious features that correlate with the label during training but are irrelevant to the learning problem. This hurts model generalization and poses problems when deploying them in safety-critical applications. This paper aims to better understand the effects of spurious features through the lens of the learning dynamics of the internal neurons during the training process. We make the following observations: (1) While previous works highlight the harmful effects of spurious features on the generalization ability of DNNs, we emphasize that not all spurious features are harmful. Spurious features can be "benign" or "harmful" depending on whether they are "harder" or "easier" to learn than the core features for a given model. This definition is model and dataset dependent. (2) We build upon this premise and use instance difficulty methods (like Prediction Depth) to quantify "easiness" for a given model and to identify this behavior during the training phase. (3) We empirically show that the harmful spurious features can be detected by observing the learning dynamics of the DNN's early layers. In other words, easy features learned by the initial layers of a DNN early during the training can (potentially) hurt model generalization. We verify our claims on medical and vision datasets, both simulated and real, and justify the empirical success of our hypothesis by showing the theoretical connections between Prediction Depth and information-theoretic concepts like $\mathcal{V}$-usable information. Lastly, our experiments show that monitoring only accuracy during training (as is common in machine learning pipelines) is insufficient to detect spurious features. We, therefore, highlight the need for monitoring early training dynamics using suitable instance difficulty metrics.

Graph Neural Networks (GNNs) have become the leading paradigm for learning on (static) graph-structured data. However, many real-world systems are dynamic in nature, since the graph and node/edge attributes change over time. In recent years, GNN-based models for temporal graphs have emerged as a promising area of research to extend the capabilities of GNNs. In this work, we provide the first comprehensive overview of the current state-of-the-art of temporal GNN, introducing a rigorous formalization of learning settings and tasks and a novel taxonomy categorizing existing approaches in terms of how the temporal aspect is represented and processed. We conclude the survey with a discussion of the most relevant open challenges for the field, from both research and application perspectives.

Molecular dynamics (MD) simulation is essential for various scientific domains but computationally expensive. Learning-based force fields have made significant progress in accelerating ab-initio MD simulation but are not fast enough for many real-world applications due to slow inference for large systems and small time steps (femtosecond-level). We aim to address these challenges by learning a multi-scale graph neural network that directly simulates coarse-grained MD with a very large time step (nanosecond-level) and a novel refinement module based on diffusion models to mitigate simulation instability. The effectiveness of our method is demonstrated in two complex systems: single-chain coarse-grained polymers and multi-component Li-ion polymer electrolytes. For evaluation, we simulate trajectories much longer than the training trajectories for systems with different chemical compositions that the model is not trained on. Structural and dynamical properties can be accurately recovered at several orders of magnitude higher speed than classical force fields by getting out of the femtosecond regime.
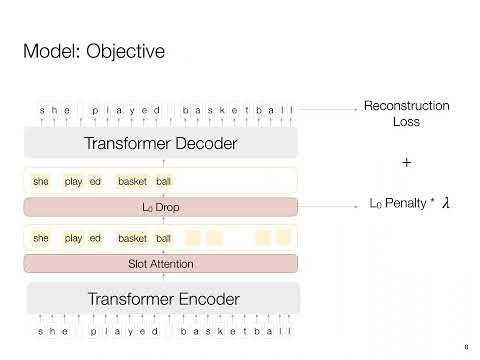
Characters do not convey meaning, but sequences of characters do. We propose an unsupervised distributional method to learn the abstract meaning-bearing units in a sequence of characters. Rather than segmenting the sequence, our Dynamic Capacity Slot Attention model discovers continuous representations of the objects in the sequence, extending an architecture for object discovery in images. We train our model on different languages and evaluate the quality of the obtained representations with forward and reverse probing classifiers. These experiments show that our model succeeds in discovering units which are similar to those proposed previously in form, content, and level of abstraction, and which show promise for capturing meaningful information at a higher level of abstraction.

Exact computation of the partition function is known to be intractable, necessitating approximate inference techniques. Existing methods for approximate inference are slow to converge for many benchmarks. The control of accuracy-complexity trade-off is also non-trivial in many of these methods. We propose a novel incremental build-infer-approximate (IBIA) framework for approximate inference that addresses these issues. In this framework, the probabilistic graphical model is converted into a sequence of clique tree forests (SCTF) with bounded clique sizes. We show that the SCTF can be used to efficiently compute the partition function. We propose two new algorithms which are used to construct the SCTF and prove the correctness of both. The first is an algorithm for incremental construction of CTFs that is guaranteed to give a valid CTF with bounded clique sizes and the second is an approximation algorithm that takes a calibrated CTF as input and yields a valid and calibrated CTF with reduced clique sizes as the output. We have evaluated our method using several benchmark sets from recent UAI competitions and our results show good accuracies with competitive runtimes.

Collaborative filtering is the de facto standard for analyzing users’ activities and building recommendation systems for items. In this work we develop Sliced Anti-symmetric Decomposition (SAD), a new model for collaborative filtering based on implicit feedback. In contrast to traditional techniques where a latent representation of users (user vectors) and items (item vectors) are estimated, SAD introduces one additional latent vector to each item, using a novel three-way tensor view of user-item interactions. This new vector extends user-item preferences calculated by standard dot products to general inner products, producing interactions between items when evaluating their relative preferences. SAD reduces to state-of-the-art (SOTA) collaborative filtering models when the vector collapses to 1, while in this paper we allow its value to be estimated from data. Allowing the values of the new item vector to be different from 1 has profound implications. It suggests users may have nonlinear mental models when evaluating items, allowing the existence of cycles in pairwise comparisons. We demonstrate the efficiency of SAD in both simulated and real world datasets containing over 1M user-item interactions. By comparing with seven SOTA collaborative filtering models with implicit feedbacks, SAD produces the most consistent personalized preferences, in the meanwhile maintaining top-level of accuracy in personalized recommendations. We release the model and inference algorithms in a Python library https://github.com/apple/ml-sad.

For visual document understanding (VDU), self-supervised pretraining has been shown to successfully generate transferable representations, yet, effective adaptation of such representations to distribution shifts at test-time remains to be an unexplored area. We propose DocTTA, a novel test-time adaptation method for documents, that does source-free domain adaptation using unlabeled target document data. DocTTA leverages cross-modality self-supervised learning via masked visual language modeling, as well as pseudo labeling to adapt models learned on a \textit{source} domain to an unlabeled \textit{target} domain at test time. We introduce new benchmarks using existing public datasets for various VDU tasks, including entity recognition, key-value extraction, and document visual question answering. DocTTA shows significant improvements on these compared to the source model performance, up to 1.89\% in (F1 score), 3.43\% (F1 score), and 17.68\% (ANLS score), respectively.

Neural ODEs demonstrate strong performance in generative and time-series modelling. However, training them via the adjoint method is slow compared to discrete models due to the requirement of numerically solving ODEs. To speed neural ODEs up, a common approach is to regularise the solutions. However, this approach may affect the expressivity of the model; when the trajectory itself matters, this is particularly important. In this paper, we propose an alternative way to speed up the training of neural ODEs. The key idea is to speed up the adjoint method by using Gauß-Legendre quadrature to solve integrals faster than ODE-based methods while remaining memory efficient. We also extend the idea to training SDEs using the Wong-Zakai theorem, by training a corresponding ODE and transferring the parameters. Our approach leads to faster training of neural ODEs, especially for large models. It also presents a new way to train SDE-based models.

Inversion by Direct Iteration (InDI) is a new formulation for supervised image restoration that avoids the so-called ``regression to the mean'' effect and produces more realistic and detailed images than existing regression-based methods. It does this by gradually improving image quality in small steps, similar to generative denoising diffusion models. Image restoration is an ill-posed problem where multiple high-quality images are plausible reconstructions of a given low-quality input. Therefore, the outcome of a single step regression model is typically an aggregate of all possible explanations, therefore lacking details and realism. The main advantage of InDI is that it does not try to predict the clean target image in a single step but instead gradually improves the image in small steps, resulting in better perceptual quality. While generative denoising diffusion models also work in small steps, our formulation is distinct in that it does not require knowledge of any analytic form of the degradation process. Instead, we directly learn an iterative restoration process from low-quality and high-quality paired examples. InDI can be applied to virtually any image degradation, given paired training data. In conditional denoising diffusion image restoration the denoising network generates the restored image by repeatedly denoising an initial image of pure noise, conditioned on the degraded input. Contrary to conditional denoising formulations, InDI directly proceeds by iteratively restoring the input low-quality image, producing high-quality results on a variety of image restoration tasks, including motion and out-of-focus deblurring, super-resolution, compression artifact removal, and denoising.

Recent progress in empirical and certified robustness promises to deliver reliable and deployable Deep Neural Networks (DNNs). Despite that success, most existing evaluations of DNN robustness have been done on images sampled from the same distribution on which the model was trained on. However, in the real world, DNNs may be deployed in dynamic environments that exhibit significant distribution shifts. In this work, we take a first step towards thoroughly investigating the interplay between empirical and certified adversarial robustness on one hand and domain generalization on another. To do so, we train robust models on multiple domains and evaluate their accuracy and robustness on an unseen domain. We observe that: (1) both empirical and certified robustness generalize to unseen domains, and (2) the level of generalizability does not correlate well with input visual similarity, measured by the FID between source and target domains. We also extend our study to cover a real-world medical application, in which adversarial augmentation significantly boosts the generalization of robustness with minimal effect on clean data accuracy.

Trying to capture the sample-label relationship, conditional generative models often end up inheriting the spurious correlation in the training dataset, giving label-conditional distributions that are severely imbalanced in another latent attribute. To mitigate such undesirable correlations engraved into generative models, which we call spurious causality, we propose a general two-step strategy. (a) Fairness Intervention (FI): Emphasize the minority samples that are hard to be generated due to the spurious correlation in the training dataset. (b) Corrective Sampling (CS): Filter the generated samples explicitly to follow the desired label-conditional latent attribute distribution. We design the fairness intervention for various degrees of supervision on the spurious attribute, including unsupervised, weakly-supervised, and semi-supervised scenarios. Our experimental results show that the proposed FICS can successfully resolve the spurious correlation in generated samples on various datasets.

Machine learning (ML) models are costly to train as they can require a significant amount of data, computational resources and technical expertise. Thus, they constitute valuable intellectual property that needs protection from adversaries wanting to steal them. Ownership verification techniques allow the victims of model stealing attacks to demonstrate that a suspect model was in fact stolen from theirs. Although a number of ownership verification techniques based on watermarking or fingerprinting have been proposed, most of them fall short either in terms of security guarantees (well-equipped adversaries can evade verification) or computational cost. A fingerprinting technique, Dataset Inference (DI) has been shown to offer better robustness and efficiency than prior methods. The authors of DI provided a correctness proof for linear (suspect) models. However, in a subspace of the same setting, we prove that DI suffers from high false positives (FPs) -- it can incorrectly identify an independent model trained with non-overlapping data from the same distribution as stolen. We further prove that DI also triggers FPs in realistic, non-linear suspect models. We then confirm empirically that DI in the black-box setting leads to FPs, with high confidence. Second, we show that DI also suffers from false negatives (FNs) -- an adversary can fool DI by regularising a stolen model's decision boundaries using adversarial training, thereby leading to an FN. To this end, we demonstrate that black-box DI fails to identify a model adversarially trained from a stolen dataset -- the setting where DI is the hardest to evade. Finally, we discuss the implications of our findings, the viability of fingerprinting-based ownership verification in general, and suggest directions for future work.

With the increasing demand for deep learning models on mobile devices, splitting neural network computation between the device and a more powerful edge server has become an attractive solution. However, existing split computing approaches often underperform compared to a naive baseline of remote computation on compressed data. Recent studies propose learning compressed representations that contain more relevant information for supervised downstream tasks, showing improved tradeoffs between compressed data size and supervised performance. However, existing evaluation metrics only provide an incomplete picture of split computing. This study introduces supervised compression for split computing (SC2) and proposes new evaluation criteria: minimizing computation on the mobile device, minimizing transmitted data size, and maximizing model accuracy. We conduct a comprehensive benchmark study using 10 baseline methods, three computer vision tasks, and over 180 trained models, and discuss various aspects of SC2. We also release our code and sc2bench, a Python package for future research on SC2. Our proposed metrics and package will help researchers better understand the tradeoffs of supervised compression in split computing.
Deep Neural Networks (DNNs) excel at learning complex abstractions within their internal representations. However, the concepts they learn remain opaque, a problem that becomes particularly acute when models unintentionally learn spurious correlations. In this work, we present DORA (Data-agnOstic Representation Analysis), the first data-agnostic framework for analyzing the representational space of DNNs. Central to our framework is the proposed Extreme-Activation (EA) distance measure, which assesses similarities between representations by analyzing their activation patterns on data points that cause the highest level of activation. As spurious correlations often manifest in features of data that are anomalous to the desired task, such as watermarks or artifacts, we demonstrate that internal representations capable of detecting such artifactual concepts can be found by analyzing relationships within neural representations. We validate the EA metric quantitatively, demonstrating its effectiveness both in controlled scenarios and real-world applications. Finally, we provide practical examples from popular Computer Vision models to illustrate that representations identified as outliers using the EA metric often correspond to undesired and spurious concepts.

Adversarial formulations such as generative adversarial networks (GANs) have rekindled interest in two-player min-max games. A central obstacle in the optimization of such games is the rotational dynamics that hinder their convergence. In this paper, we show that game optimization shares dynamic properties with particle systems subject to multiple forces, and one can leverage tools from physics to improve optimization dynamics. Inspired by the physical framework, we propose LEAD, an optimizer for min-max games. Next, using Lyapunov stability theory and spectral analysis, we study LEAD’s convergence properties in continuous and discrete time settings for a class of quadratic min-max games to demonstrate linear convergence to the Nash equilibrium. Finally, we empirically evaluate our method on synthetic setups and CIFAR-10 image generation to demonstrate improvements in GAN training.

Diversity is an important criterion for many areas of machine learning (ML), including generative modeling and dataset curation. However, existing metrics for measuring diversity are often domain-specific and limited in flexibility. In this paper we address the diversity evaluation problem by proposing the Vendi Score, which connects and extends ideas from ecology and quantum statistical mechanics to ml. The Vendi Score is defined as the exponential of the Shannon entropy of the eigenvalues of a similarity matrix. This matrix is induced by a user-defined similarity function applied to the sample to be evaluated for diversity. In taking a similarity function as input, the Vendi Score enables its user to specify any desired form of diversity. Importantly, unlike many existing metrics in ML, the Vendi Score does not require a reference dataset or distribution over samples or labels, it is therefore general and applicable to any generative model, decoding algorithm, and dataset from any domain where similarity can be defined. We showcase the Vendi Score on molecular generative modeling where we found it addresses shortcomings of the current diversity metric of choice in that domain. We also applied the Vendi Score to generative models of images and decoding algorithms of text where we found it confirms known results about diversity in those domains. Furthermore, we used the Vendi Score to measure mode collapse, a known shortcoming of generative adversarial networks (GANs). In particular, the Vendi Score revealed that even GANs that capture all the modes of a labelled dataset can be less diverse than the original dataset. Finally, the interpretability of the Vendi Score allowed us to diagnose several benchmark ML datasets for diversity, opening the door for diversity-informed data augmentation.

Pool-based Active Learning (AL) has proven successful in minimizing labeling costs by sequentially selecting the most informative unlabeled data from large pool and querying their labels from an oracle or annotators. However, existing AL sampling schemes may not perform well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains samples that do not belong to the pre-defined categories of the target task. Achieving strong AL performance under OOD data scenarios presents a challenge due to the inherent conflict between AL sampling strategies and OOD data detection. For instance, both more informative in-distribution (ID) data and OOD data in an unlabeled data pool would be assigned high informativeness scores (e.g., high entropy) during AL processes. To address this dilemma, we propose a Monte-Carlo Pareto Optimization for Active Learning (POAL) sampling scheme, which selects optimal subsets of unlabeled samples with fixed batch size from the unlabeled data pool. We formulate the AL sampling task as a multi-objective optimization problem and employ Pareto optimization based on two conflicting objectives: (1) the conventional AL sampling scheme (e.g., maximum entropy) and (2) the confidence of excluding OOD data samples. Experimental results demonstrate the effectiveness of our POAL approach on classical Machine Learning (ML) and Deep Learning (DL) tasks.
Developing successful artificial intelligence systems in practice depends on both robust deep learning models and large, high-quality data. However, acquiring and labeling data can be prohibitively expensive and time-consuming in many real-world applications, such as clinical disease models. Self-supervised learning has demonstrated great potential in increasing model accuracy and robustness in small data regimes. In addition, many clinical imaging and disease modeling applications rely heavily on regression of continuous quantities. However, the applicability of self-supervised learning for these medical-imaging regression tasks has not been extensively studied. In this study, we develop a cross-domain self-supervised learning approach for disease prognostic modeling as a regression problem using medical images as input. We demonstrate that self-supervised pretraining can improve the prediction of Alzheimer's Disease progression from brain MRI. We also show that pretraining on extended (but not labeled) brain MRI data outperforms pretraining on natural images. We further observe that the highest performance is achieved when both natural images and extended brain-MRI data are used for pretraining.

Vision-language (VL) pretrained models have achieved impressive performance on multimodal reasoning and zero-shot recognition tasks. Many of these VL models are pretrained on unlabeled image and caption pairs from the internet. In this paper, we study whether representations of primitive concepts–such as colors, shapes, or the attributes of object parts–emerge automatically within these pretrained VL models. We propose a two-step framework, Compositional Concept Mapping (CompMap), to investigate this. CompMap first asks a VL model to generate concept activations with text prompts from a predefined list of primitive concepts, and then learns to construct an explicit composition model that maps the primitive concept activations (e.g. the likelihood of black tail or red wing) to com- posite concepts (e.g. a red-winged blackbird). We demonstrate that a composition model can be designed as a set operation, and show that a composition model is straightforward for machines to learn from ground truth primitive concepts (as a linear classifier). We thus hypothesize that if primitive concepts indeed emerge in a VL pretrained model, its primitive concept activations can be used to learn a composition model similar to the one designed by experts. We propose a quantitative metric to measure the degree of similarity, and refer to the metric as the interpretability of the VL models’ learned primitive concept representations. We also measure the classification accuracy when using the primitive concept activations and the learned composition model to predict the composite concepts, and refer to it as the usefulness metric. Our study reveals that state-of-the-art VL pretrained models learn primitive concepts that are highly useful for fine-grained visual recognition on the CUB dataset, and compositional generalization tasks on the MIT-States dataset. However, we observe that the learned composition models have low interpretability in our qualitative analyses. Our results reveal the limitations of existing VL models, and the necessity of pretraining objectives that encourage the acquisition of primitive concepts.

Implicit deep learning allows one to compute with implicitly defined features, for example features that solve optimisation problems. We consider the problem of computing with implicitly defined features in a kernel regime. We call such a kernel a deep equilibrium kernel (DEKer). Specialising on a stochastic gradient descent (SGD) update rule applied to features (not weights) in a latent variable model, we find an exact deterministic update rule for the (DEKer) in a high dimensional limit. This derived update rule resembles previously introduced infinitely wide neural network kernels. To perform our analysis, we describe an alternative parameterisation of the link function of exponential families, a result that may be of independent interest. This new parameterisation allows us to draw new connections between a statistician's inverse link function and a machine learner's activation function. We describe an interesting property of SGD in this high dimensional limit: even though individual iterates are random vectors, inner products of any two iterates are deterministic, and can converge to a unique fixed point as the number of iterates increases. We find that the (DEKer) empirically outperforms related neural network kernels on a series of benchmarks.

Humans excel at continually acquiring, consolidating, and retaining information from an ever-changing environment, whereas artificial neural networks (ANNs) exhibit catastrophic forgetting. There are considerable differences in the complexity of synapses, the processing of information, and the learning mechanisms in biological neural networks and their artificial counterparts, which may explain the mismatch in performance. We consider a biologically plausible framework that constitutes separate populations of exclusively excitatory and inhibitory neurons that adhere to Dale's principle, and the excitatory pyramidal neurons are augmented with dendritic-like structures for context-dependent processing of stimuli. We then conduct a comprehensive study on the role and interactions of different mechanisms inspired by the brain, including sparse non-overlapping representations, Hebbian learning, synaptic consolidation, and replay of past activations that accompanied the learning event. Our study suggests that the employing of multiple complementary mechanisms in a biologically plausible architecture, similar to the brain, may be effective in enabling continual learning in ANNs. \footnote{We will make the code available upon acceptance.
Monge map refers to the optimal transport map between two probability distributions and provides a principled approach to transform one distribution to another. Neural network-based optimal transport map solver has gained great attention in recent years. Along this line, we present a scalable algorithm for computing the neural Monge map between two probability distributions. Our algorithm is based on a weak form of the optimal transport problem, thus it only requires samples from the marginals instead of their analytic expressions, and can be applied in large-scale settings. Furthermore, using the duality gap we prove rigorously \textit{a posteriori} error analysis for the method. Our algorithm is suitable for general cost functions, compared with other existing methods for estimating Monge maps using samples, which are usually for quadratic costs. The performance of our algorithms is demonstrated through a series of experiments with both synthetic and realistic data, including text-to-image generation, class-preserving map, and image inpainting tasks.

The completeness axiom renders the explanation of a post-hoc eXplainable AI (XAI) method only locally faithful to the model, i.e. for a single decision. For the trustworthy application of XAI, in particular for high-stake decisions, a more global model understanding is required. To this end, concept-based methods have been proposed, which are however not guaranteed to be bound to the actual model reasoning. To circumvent this problem, we propose Multi-dimensional Concept Discovery (MCD) as an extension of previous approaches that fulfills a completeness relation on the level of concepts. Our method starts from general linear subspaces as concepts and does neither require reinforcing concept interpretability nor re-training of model parts. We propose sparse subspace clustering to discover improved concepts and fully leverage the potential of multi-dimensional subspaces. MCD offers two complementary analysis tools for concepts in input space: (1) concept activation maps, that show where a concept is expressed within a sample, allowing for concept characterization through prototypical samples, and (2) concept relevance heatmaps, that decompose the model decision into concept contributions. Both tools together enable a detailed global understanding of the model reasoning, which is guaranteed to relate to the model via a completeness relation. Thus, MCD paves the way towards more trustworthy concept-based XAI. We empirically demonstrate the superiority of MCD against more constrained concept definitions.

Randomized smoothing is a technique for providing provable robustness guarantees against adversarial attacks while making minimal assumptions about a classifier. This method relies on taking a majority vote of any base classifier over multiple noise-perturbed inputs to obtain a smoothed classifier, and it remains the tool of choice to certify deep and complex neural network models. Nonetheless, non-trivial performance of such smoothed classifier crucially depends on the base model being trained on noise-augmented data, i.e., on a smoothed input distribution. While widely adopted in practice, it is still unclear how this noisy training of the base classifier precisely affects the risk of the robust smoothed classifier, leading to heuristics and tricks that are poorly understood. In this work we analyze these trade-offs theoretically in a binary classification setting, proving that these common observations are not universal. We show that, without making stronger distributional assumptions, no benefit can be expected from predictors trained with noise-augmentation, and we further characterize distributions where such benefit is obtained. Our analysis has direct implications to the practical deployment of randomized smoothing, and we illustrate some of these via experiments on CIFAR-10 and MNIST, as well as on synthetic datasets.

A major goal of artificial intelligence (AI) is to create an agent capable of acquiring a general understanding of the world. Such an agent would require the ability to continually accumulate and build upon its knowledge as it encounters new experiences. Lifelong or continual learning addresses this setting, whereby an agent faces a continual stream of problems and must strive to capture the knowledge necessary for solving each new task it encounters. If the agent is capable of accumulating knowledge in some form of compositional representation, it could then selectively reuse and combine relevant pieces of knowledge to construct novel solutions. Despite the intuitive appeal of this simple idea, the literatures on lifelong learning and compositional learning have proceeded largely separately. In an effort to promote developments that bridge between the two fields, this article surveys their respective research landscapes and discusses existing and future connections between them.
Data missingness and quality are common problems in machine learning, especially for high-stakes applications such as healthcare. Developers often train machine learning models on carefully curated datasets using only high-quality data; however, this reduces the utility of such models in production environments. We propose a novel neural network modification to mitigate the impacts of low-quality and missing data which involves replacing the fixed weights of a fully-connected layer with a function of additional input. This is inspired by neuromodulation in biological neural networks where the cortex can up- and down-regulate inputs based on their reliability and the presence of other data. In testing, with reliability scores as a modulating signal, models with modulating layers were found to be more robust against data quality degradation, including additional missingness. These models are superior to imputation as they save on training time by entirely skipping the imputation process and further allow the introduction of other data quality measures that imputation cannot handle. Our results suggest that explicitly accounting for reduced information quality with a modulating fully connected layer can enable the deployment of artificial intelligence systems in real-time applications.

3D shapes have complementary abstractions from low-level geometry to part-based hierarchies to languages, which convey different levels of information. This paper presents a unified framework to translate between pairs of shape abstractions: $\textit{Text}$ $\Longleftrightarrow$ $\textit{Point Cloud}$ $\Longleftrightarrow$ $\textit{Program}$. We propose $\textbf{\textit{Neural Shape Compiler}}$ to model the abstraction transformation as a conditional generation process. It converts 3D shapes of three abstract types into unified discrete shape code, transforms each shape code into code of other abstract types through the proposed $\textit{ShapeCode Transformer}$, and decodes them to output the target shape abstraction. Point Cloud code is obtained in a class-agnostic way by the proposed $\textit{Point}$VQVAE. On Text2Shape, ShapeGlot, ABO, Genre, and Program Synthetic datasets, Neural Shape Compiler shows strengths in $\textit{Text}$ $\Longrightarrow$ $\textit{Point Cloud}$, $\textit{Point Cloud}$ $\Longrightarrow$ $\textit{Text}$, $\textit{Point Cloud}$ $\Longrightarrow$ $\textit{Program}$, and Point Cloud Completion tasks. Additionally, Neural Shape Compiler benefits from jointly training on all heterogeneous data and tasks.

To train image-caption retrieval (ICR) methods, contrastive loss functions are a common choice for optimization functions. Unfortunately, contrastive ICR methods are vulnerable to predictive feature suppression. Predictive features are features that correctly indicate the similarity between a query and a candidate item. However, in the presence of multiple predictive features during training, encoder models tend to suppress redundant predictive features, since these features are not needed to learn to discriminate between positive and negative pairs. We introduce an approach to reduce predictive feature suppression for resource-constrained ICR methods: latent target decoding (LTD). We add an additional decoder to the contrastive ICR framework, to reconstruct the input caption in a latent space of a general-purpose sentence encoder, which prevents the image and caption encoder from suppressing predictive features. We implement the LTD objective as an optimization constraint, to ensure that the reconstruction loss is below a bound value while primarily optimizing for the contrastive loss. Importantly, LTD does not depend on additional training data or expensive (hard) negative mining strategies. Our experiments show that, unlike reconstructing the input caption in the input space, LTD reduces predictive feature suppression, measured by obtaining higher recall@k, r-precision, and nDCG scores than a contrastive ICR baseline. Moreover, we show that LTD should be implemented as an optimization constraint instead of a dual optimization objective. Finally, we show that LTD can be used with different contrastive learning losses and a wide variety of resource-constrained ICR methods.
In order for artificial agents to successfully perform tasks in changing environments, they must be able to both detect and adapt to novelty. However, visual novelty detection research often only evaluates on repurposed datasets such as CIFAR-10 originally intended for object classification, where images focus on one distinct, well-centered object. New benchmarks are needed to represent the challenges of navigating the complex scenes of an open world. Our new NovelCraft dataset contains multimodal episodic data of the images and symbolic world-states seen by an agent completing a pogo stick assembly task within a modified Minecraft environment. In some episodes, we insert novel objects of varying size within the complex 3D scene that may impact gameplay. Our visual novelty detection benchmark finds that methods that rank best on popular area-under-the-curve metrics may be outperformed by simpler alternatives when controlling false positives matters most. Further multimodal novelty detection experiments suggest that methods that fuse both visual and symbolic information can improve time until detection as well as overall discrimination. Finally, our evaluation of recent generalized category discovery methods suggests that adapting to new imbalanced categories in complex scenes remains an exciting open problem.

Hierarchical methods in reinforcement learning have the potential to reduce the amount of decisions that the agent needs to perform when learning new tasks. However, finding a reusable useful temporal abstractions that facilitate fast learning remains a challenging problem. Recently, several deep learning approaches were proposed to learn such temporal abstractions in the form of options in an end-to-end manner. In this work, we point out several shortcomings of these methods and discuss their potential negative consequences. Subsequently, we formulate the desiderata for reusable options and use these to frame the problem of learning options as a gradient-based meta-learning problem. This allows us to formulate an objective that explicitly incentivizes options which allow a higher-level decision maker to adjust in few steps to different tasks. Experimentally, we show that our method is able to learn transferable components which accelerate learning and performs better than existing prior methods developed for this setting. Additionally, we perform ablations to quantify the impact of using gradient-based meta-learning as well as other proposed changes.

Transfer in Reinforcement Learning aims to improve learning performance on target tasks using knowledge from experienced source tasks. Successor Representations (SR) and their extension Successor Features (SF) are prominent transfer mechanisms in domains where reward functions change between tasks. They reevaluate the expected return of previously learned policies in a new target task to transfer their knowledge. The SF framework extended SR by linearly decomposing rewards into successor features and a reward weight vector allowing their application in high-dimensional tasks. But this came with the cost of having a linear relationship between reward functions and successor features, limiting its application to tasks where such a linear relationship exists. We propose a novel formulation of SR based on learning the cumulative discounted probability of successor features, called Successor Feature Representations (SFR). Crucially, SFR allows to reevaluate the expected return of policies for general reward functions. We introduce different SFR variations, prove its convergence, and provide a guarantee on its transfer performance. Experimental evaluations based on SFR with function approximation demonstrate its advantage over SF not only for general reward functions, but also in the case of linearly decomposable reward functions.

We present a novel perspective on behavioural metrics for Markov decision processes via the use of positive definite kernels. We define a new metric under this lens that is provably equivalent to the recently introduced MICo distance (Castro et al., 2021). The kernel perspective enables us to provide new theoretical results, including value-function bounds and low-distortion finite-dimensional Euclidean embeddings, which are crucial when using behavioural metrics for reinforcement learning representations. We complement our theory with strong empirical results that demonstrate the effectiveness of these methods in practice.

Explanations are hypothesized to improve human understanding of machine learning models and achieve a variety of desirable outcomes, ranging from model debugging to enhancing human decision making. However, empirical studies have found mixed and even negative results. An open question, therefore, is under what conditions explanations can improve human understanding and in what way. To address this question, we first identify three core concepts that cover most existing quantitative measures of understanding: task decision boundary, model decision boundary, and model error. Using adapted causal diagrams, we provide a formal characterization of the relationship between these concepts and human approximations (i.e., understanding) of them. The relationship varies by the level of human intuition in different task types, such as emulation and discovery, which are often ignored when building or evaluating explanation methods. Our key result is that human intuitions are necessary for generating and evaluating machine explanations in human-AI decision making: without assumptions about human intuitions, explanations may improve human understanding of model decision boundary, but cannot improve human understanding of task decision boundary or model error. To validate our theoretical claims, we conduct human subject studies to show the importance of human intuitions. Together with our theoretical contributions, we provide a new paradigm for designing behavioral studies towards a rigorous view of the role of machine explanations across different tasks of human-AI decision making.

Patch foraging is one of the most heavily studied behavioral optimization challenges in biology. However, despite its importance to biological intelligence, this behavioral optimization problem is understudied in artificial intelligence research. Patch foraging is especially amenable to study given that it has a known optimal solution, which may be difficult to discover given current techniques in deep reinforcement learning. Here, we investigate deep reinforcement learning agents in an ecological patch foraging task. For the first time, we show that machine learning agents can learn to patch forage adaptively in patterns similar to biological foragers, and approach optimal patch foraging behavior when accounting for temporal discounting. Finally, we show emergent internal dynamics in these agents that resemble single-cell recordings from foraging non-human primates, which complements experimental and theoretical work on the neural mechanisms of biological foraging. This work suggests that agents interacting in complex environments with ecologically valid pressures arrive at common solutions, suggesting the emergence of foundational computations behind adaptive, intelligent behavior in both biological and artificial agents.
Many problems in machine learning rely on multi-task learning (MTL), in which the goal is to solve multiple related machine learning tasks simultaneously. MTL is particularly relevant for privacy-sensitive applications in areas such as healthcare, finance, and IoT computing, where sensitive data from multiple, varied sources are shared for the purpose of learning. In this work, we formalize notions of client-level privacy for MTL via billboard privacy (BP), a relaxation of differential privacy for mechanism design and distributed optimization. We then propose an algorithm for mean-regularized MTL, an objective commonly used for applications in personalized federated learning, subject to BP. We analyze our objective and solver, providing certifiable guarantees on both privacy and utility. Empirically, we find that our method provides improved privacy/utility trade-offs relative to global baselines across common federated learning benchmarks.
We present a method for learning active vision skills, to move the camera to observe a robot's sensors from informative points of view, without external rewards or labels. We do this by jointly training a visual predictor network, which predicts future returns of the sensors using pixels, and a camera control agent, which we reward using the negative error of the predictor. The agent thus moves the camera to points of view that are most predictive for a chosen sensor, which we select using a conditioning input to the agent. We observe that despite this noisy learned reward function, the learned policies a exhibit competence by reliably framing the sensor in a specific location in the view, an emergent location which we call a behavioral fovea. We find that replacing the conventional camera with a foveal camera further increases the policies' precision.
In many sequential decision-making tasks, the agent is not able to model the full complexity of the world, which consists of multitudes of relevant and irrelevant information. For example, a person walking along a city street who tries to model all aspects of the world would quickly be overwhelmed by a multitude of shops, cars, and people moving in and out of view, each following their own complex and inscrutable dynamics. Is it possible to turn the agent's firehose of sensory information into a minimal latent state that is both necessary and sufficient for an agent to successfully act in the world? We formulate this question concretely, and propose the Agent Control-Endogenous State Discovery algorithm (AC-State), which has theoretical guarantees and is practically demonstrated to discover the minimal control-endogenous latent state which contains all of the information necessary for controlling the agent, while fully discarding all irrelevant information. This algorithm consists of a multi-step inverse model (predicting actions from distant observations) with an information bottleneck. AC-State enables localization, exploration, and navigation without reward or demonstrations. We demonstrate the discovery of the control-endogenous latent state in three domains: localizing a robot arm with distractions (e.g., changing lighting conditions and background), exploring a maze alongside other agents, and navigating in the Matterport house simulator.
Selecting a well-performing algorithm for a given task or dataset can be time-consuming and tedious, but is crucial for the successful day-to-day business of developing new AI & ML applications. Algorithm Selection (AS) mitigates this through a meta-model leveraging meta-information about previous tasks. However, most of the available AS methods are error-prone because they characterize a task by either cheap-to-compute properties of the dataset or evaluations of cheap proxy algorithms, called landmarks. In this work, we extend the classical AS data setup to include multi-fidelity information and empirically demonstrate how meta-learning on algorithms’ learning behaviour allows us to exploit cheap test-time evidence effectively and combat myopia significantly. We further postulate a budget-regret trade-off w.r.t. the selection process. Our new selector MASIF is able to jointly interpret online evidence on a task in form of varying-length learning curves without any parametric assumption by leveraging a transformer-based encoder. This opens up new possibilities for guided rapid prototyping in data science on cheaply observed partial learning curves.

Photorealistic object appearance modeling from 2D images is a constant topic in vision and graphics. While neural implicit methods (such as Neural Radiance Fields) have shown high-fidelity view synthesis results, they cannot relight the captured objects. More recent neural inverse rendering approaches have enabled object relighting, but they represent surface properties as simple BRDFs, and therefore cannot handle translucent objects. We propose Object-Centric Neural Scattering Functions (OSFs) for learning to reconstruct object appearance from only images. OSFs not only support free-viewpoint object relighting, but also can model both opaque and translucent objects. While accurately modeling subsurface light transport for translucent objects can be highly complex and even intractable for neural methods, OSFs learn to approximate the radiance transfer from a distant light to an outgoing direction at any spatial location. This approximation avoids explicitly modeling complex subsurface scattering, making learning a neural implicit model tractable. Experiments on real and synthetic data show that OSFs accurately reconstruct appearances for both opaque and translucent objects, allowing faithful free-viewpoint relighting as well as scene composition. In our supplementary material, we include a video for an overview. Project website with video results: https://kovenyu.com/OSF/
There is a recent surge in the development of spatio-temporal forecasting models in the transportation domain. Long-range traffic forecasting, however, remains a challenging task due to the intricate and extensive spatio-temporal correlations observed in traffic networks. Current works primarily rely on road networks with graph structures and learn representations using graph neural networks (GNNs), but this approach suffers from over-smoothing problem in deep architectures. To tackle this problem, recent methods introduced the combination of GNNs with residual connections or neural ordinary differential equations (ODE). However, current graph ODE models face two key limitations in feature extraction: (1) they lean towards global temporal patterns, overlooking local patterns that are important for unexpected events; and (2) they lack dynamic semantic edges in their architectural design. In this paper, we propose a novel architecture called Graph-based Multi-ODE Neural Networks (GRAM-ODE) which is designed with multiple connective ODE-GNN modules to learn better representations by capturing different views of complex local and global dynamic spatio-temporal dependencies. We also add some techniques like shared weights and divergence constraints into the intermediate layers of distinct ODE-GNN modules to further improve their communication towards the forecasting task. Our extensive set of experiments conducted on six real-world datasets demonstrate the superior performance of GRAM-ODE compared with state-of-the-art baselines as well as the contribution of different components to the overall performance.

Deep neural networks (DNNs) are often trained on the premise that the complete training data set is provided ahead of time. However, in real-world scenarios, data often arrive in chunks over time. This leads to important considerations about the optimal strategy for training DNNs, such as whether to fine-tune them with each chunk of incoming data (warm-start) or to retrain them from scratch with the entire corpus of data whenever a new chunk is available. While employing the latter for training can be resource-intensive, recent work has pointed out the lack of generalization in warm-start models. Therefore, to strike a balance between efficiency and generalization, we introduce "Learn, Unlearn, and Relearn (LURE)" an online learning paradigm for DNNs. LURE interchanges between the unlearning phase, which selectively forgets the undesirable information in the model through weight reinitialization in a data-dependent manner, and the relearning phase, which emphasizes learning on generalizable features. We show that our training paradigm provides consistent performance gains across datasets in both classification and few-shot settings. We further show that it leads to more robust and well-calibrated models.
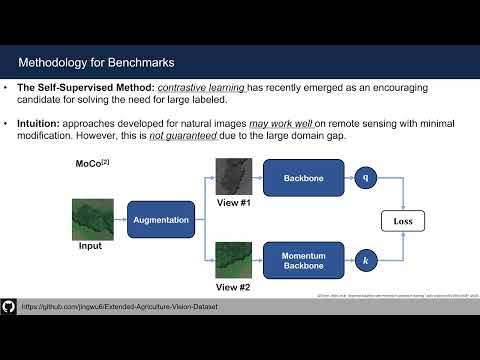
A key challenge for much of the machine learning work on remote sensing and earth observation data is the difficulty in acquiring large amounts of accurately labeled data. This is particularly true for semantic segmentation tasks, which are much less common in the remote sensing domain because of the incredible difficulty in collecting precise, accurate, pixel-level annotations at scale. Recent efforts have addressed these challenges both through the creation of supervised datasets as well as the application of self-supervised methods. We continue these efforts on both fronts. First, we generate and release an improved version of the Agriculture-Vision dataset (Chiu et al., 2020b) to include raw, full-field imagery for greater experimental flexibility. Second, we extend this dataset with the release of 3600 large, high-resolution (10cm/pixel), full-field, red-green-blue and near-infrared images for pre-training. Third, we incorporate the Pixel-to-Propagation Module Xie et al. (2021b) originally built on the SimCLR framework into the framework of MoCo-V2 Chen et al.(2020b). Finally, we demonstrate the usefulness of this data by benchmarking different contrastive learning approaches on both downstream classification and semantic segmentation tasks. We explore both CNN and Swin Transformer Liu et al. (2021a) architectures within different frameworks based on MoCo-V2. Together, these approaches enable us to better detect key agricultural patterns of interest across a field from aerial imagery so that farmers may be alerted to problematic areas in a timely fashion to inform their management decisions. Furthermore, the release of these datasets will support numerous avenues of research for computer vision in remote sensing for agriculture.

Rotation equivariance is a desirable property in many practical applications such as motion forecasting and 3D perception, where it can offer benefits like sample efficiency, better generalization, and robustness to input perturbations. Vector Neurons (VN) is a recently developed framework offering a simple yet effective approach for deriving rotation-equivariant analogs of standard machine learning operations by extending one-dimensional scalar neurons to three-dimensional "vector neurons." We introduce a novel "VN-Transformer" architecture to address several shortcomings of the current VN models. Our contributions are: (i) we derive a rotation-equivariant attention mechanism which eliminates the need for the heavy feature preprocessing required by the original Vector Neurons models; (ii) we extend the VN framework to support non-spatial attributes, expanding the applicability of these models to real-world datasets; (iii) we derive a rotation-equivariant mechanism for multi-scale reduction of point-cloud resolution, greatly speeding up inference and training; (iv) we show that small tradeoffs in equivariance ($\epsilon$-approximate equivariance) can be used to obtain large improvements in numerical stability and training robustness on accelerated hardware, and we bound the propagation of equivariance violations in our models. Finally, we apply our VN-Transformer to 3D shape classification and motion forecasting with compelling results.

Implicit neural representations (INRs) have achieved impressive results for scene reconstruction and computer graphics, where their performance has primarily been assessed on reconstruction accuracy. As INRs make their way into other domains, where model predictions inform high-stakes decision-making, uncertainty quantification of INR inference is becoming critical. To that end, we study a Bayesian reformulation of INRs, UncertaINR, in the context of computed tomography, and evaluate several Bayesian deep learning implementations in terms of accuracy and calibration. We find that they achieve well-calibrated uncertainty, while retaining accuracy competitive with other classical, INR-based, and CNN-based reconstruction techniques. Contrary to common intuition in the Bayesian deep learning literature, we find that INRs obtain the best calibration with computationally efficient Monte Carlo dropout, outperforming Hamiltonian Monte Carlo and deep ensembles. Moreover, in contrast to the best-performing prior approaches, UncertaINR does not require a large training dataset, but only a handful of validation images.
Multi-class support vector machine (SVM) models are typically built using all possible pairs of binary SVM in a one-against-one fashion. This requires too much computation for datasets with hundreds or thousands of classes, which motivates the search for multi-class models that do not use all pairwise SVM. Our models correspond to the choice of the model graph, whose vertices correspond to classes and edges represent which pairwise SVMs are trained. We conduct experiments to uncover metrical and topological properties that impact the accuracy of a multi-class SVM model. Based on their results we propose a way to construct intermediate multi-class SVM models. The key insight is that for model graphs of diameter two, we can estimate missing pairwise probabilities from the known ones thus transforming the computation of posteriors to the usual complete (maximal) case. Our proposed algorithm allows one to reduce computational effort by 50-80% while keeping accuracy near, or even above that of a softmax classifier. In our work we use convolutional data sets, which have multiple advantages for benchmarking multi-class SVM models.

Data-driven machine learning models are being increasingly employed in several important inference problems in biology, chemistry, and physics, which require learning over combinatorial spaces. Recent empirical evidence (see, e.g., ~\cite{tseng2020fourier,aghazadeh2021epistatic,ha2021adaptive}) suggests that regularizing the spectral representation of such models improves their generalization power when labeled data is scarce. However, despite these empirical studies, the theoretical underpinning of when and how spectral regularization enables improved generalization is poorly understood. In this paper, we focus on learning pseudo-Boolean functions and demonstrate that regularizing the empirical mean squared error by the $L_1$ norm of the spectral transform of the learned function reshapes the loss landscape and allows for data-frugal learning under a restricted secant condition on the learner's empirical error measured against the ground truth function. Under a weaker quadratic growth condition, we show that stationary points, which also approximately interpolate the training data points achieve statistically optimal generalization performance. Complementing our theory, we empirically demonstrate that running gradient descent on the regularized loss results in a better generalization performance compared to baseline algorithms in several data-scarce real-world problems.

Many applications of representation learning, such as privacy preservation, algorithmic fairness, and domain adaptation, desire explicit control over semantic information being discarded. This goal is formulated as satisfying two objectives: maximizing utility for predicting a target attribute while simultaneously being invariant (independent) to a known semantic attribute. Solutions to invariant representation learning (IRepL) problems lead to a trade-off between utility and invariance when they are competing. While existing works study bounds on this trade-off, two questions remain outstanding: 1) What is the exact trade-off between utility and invariance? and 2) What are the encoders (mapping the data to a representation) that achieve the trade-off, and how can we estimate it from training data? This paper addresses these questions for IRepLs in reproducing kernel Hilbert spaces (RKHS)s. Under the assumption that the distribution of a low-dimensional projection of high-dimensional data is approximately normal, we derive a closed-form solution for the global optima of the underlying optimization problem for encoders in RKHSs. This yields closed formulae for a near-optimal trade-off, corresponding optimal representation dimensionality, and the corresponding encoder(s). We also numerically quantify the trade-off on representative problems and compare them to those achieved by baseline IRepL algorithms.

We propose a new framework for imitation learning---treating imitation as a two-player ranking-based game between a policy and a reward. In this game, the reward agent learns to satisfy pairwise performance rankings between behaviors, while the policy agent learns to maximize this reward. In imitation learning, near-optimal expert data can be difficult to obtain, and even in the limit of infinite data cannot imply a total ordering over trajectories as preferences can. On the other hand, learning from preferences alone is challenging as a large number of preferences are required to infer a high-dimensional reward function, though preference data is typically much easier to collect than expert demonstrations. The classical inverse reinforcement learning (IRL) formulation learns from expert demonstrations but provides no mechanism to incorporate learning from offline preferences and vice versa. We instantiate the proposed ranking-game framework with a novel ranking loss giving an algorithm that can simultaneously learn from expert demonstrations and preferences, gaining the advantages of both modalities. Our experiments show that the proposed method achieves state-of-the-art sample efficiency and can solve previously unsolvable tasks in the Learning from Observation (LfO) setting.

Despite the success of large-scale empirical risk minimization (ERM) at achieving high accuracy across a variety of machine learning tasks, fair ERM is hindered by the incompatibility of fairness constraints with stochastic optimization. We consider the problem of fair classification with discrete sensitive attributes and potentially large models and data sets, requiring stochastic solvers. Existing in-processing fairness algorithms are either impractical in the large-scale setting because they require large batches of data at each iteration or they are not guaranteed to converge. In this paper, we develop the first stochastic in-processing fairness algorithm with guaranteed convergence. For demographic parity, equalized odds, and equal opportunity notions of fairness, we provide slight variations of our algorithm–called FERMI–and prove that each of these variations converges in stochastic optimization with any batch size. Empirically, we show that FERMI is amenable to stochastic solvers with multiple (non-binary) sensitive attributes and non-binary targets, performing well even with minibatch size as small as one. Extensive experiments show that FERMI achieves the most favorable tradeoffs between fairness violation and test accuracy across all tested setups compared with state-of-the-art baselines for demographic parity, equalized odds, equal opportunity. These benefits are especially significant with small batch sizes and for non-binary classification with large number of sensitive attributes, making FERMI a practical, scalable fairness algorithm. The code for all of the experiments in this paper is available at: https://github.com/optimization-for-data-driven-science/FERMI

Energy-based models (EBMs) allow flexible specifications of probability distributions. However, sampling from EBMs is non-trivial, usually requiring approximate techniques such as Markov chain Monte Carlo (MCMC). A major downside of MCMC sampling is that it is often impossible to compute the divergence of the sampling distribution from the target distribution: therefore, the quality of the samples cannot be guaranteed. Here, we introduce quasi-rejection sampling (QRS), a simple extension of rejection sampling that performs approximate sampling, but, crucially, does provide divergence diagnostics (in terms of f-divergences, such as KL divergence and total variation distance). We apply QRS to sampling from discrete EBMs over text for controlled generation. We show that we can sample from such EBMs with arbitrary precision in exchange for sampling efficiency and quantify the trade-off between the two by means of the aforementioned diagnostics.

We present extensive empirical evidence showing that current Bayesian simulation-based inference algorithms can produce computationally unfaithful posterior approximations. Our results show that all benchmarked algorithms -- (S)NPE, (S)NRE, SNL and variants of ABC -- can yield overconfident posterior approximations, which makes them unreliable for scientific use cases and falsificationist inquiry. Failing to address this issue may reduce the range of applicability of simulation-based inference. For this reason, we argue that research efforts should be made towards theoretical and methodological developments of conservative approximate inference algorithms and present research directions towards this objective. In this regard, we show empirical evidence that ensembling posterior surrogates provides more reliable approximations and mitigates the issue.

In Multi-Task Learning (MTL), K distinct tasks are jointly optimized. With the varying nature and complexities of tasks, few tasks might dominate learning. For other tasks, their respective performances may get compromised due to a negative transfer from dominant tasks. We propose a Dropped-Scheduled Task (DST) algorithm, which probabilistically “drops” specific tasks during joint optimization while scheduling others to reduce negative transfer. For each task, a scheduling probability is decided based on four different metrics: (i) task depth, (ii) number of ground-truth samples per task, (iii) amount of training completed, and (iv) task stagnancy. Based on the scheduling probability, specific tasks get joint computation cycles while others are “dropped”. To demonstrate the effectiveness of the proposed DST algorithm, we perform multi-task learning on three applications and two architectures. Across unilateral (single input) and bilateral (multiple input) multi-task net- works, the chosen applications are (a) face (AFLW), (b) fingerprint (IIITD MOLF, MUST, and NIST SD27), and (c) character recognition (Omniglot) applications. Experimental results show that the proposed DST algorithm has the minimum negative transfer and overall least errors across different state-of-the-art algorithms and tasks.
Building and maintaining state to learn policies and value functions is critical for deploying reinforcement learning (RL) agents in the real world. Recurrent neural networks (RNNs) have become a key point of interest for the state-building problem, and several large-scale reinforcement learning agents incorporate recurrent networks. While RNNs have become a mainstay in many RL applications, many key design choices and implementation details responsible for performance improvements are often not reported. In this work, we discuss one axis on which RNN architectures can be (and have been) modified for use in RL. Specifically, we look at how action information can be incorporated into the state update function of a recurrent cell. We discuss several choices in using action information and empirically evaluate the resulting architectures on a set of illustrative domains. Finally, we discuss future work in developing recurrent cells and discuss challenges specific to the RL setting.

Recent years have witnessed a surge of successful applications of machine reading comprehension. Of central importance to these tasks is the availability of massive amount of labeled data, which facilitates training of large-scale neural networks. However, in many real-world problems, annotated data are expensive to gather not only because of time cost and budget, but also of certain domain-specific restrictions such as privacy for healthcare data. In this regard, we propose an uncertainty-based active learning algorithm for reading comprehension, which interleaves data annotation and model updating to mitigate the demand of labeling. Our key techniques are two-fold: 1) an unsupervised uncertainty-based sampling scheme that queries the labels of the most informative instances with respect to the currently learned model; and 2) an adaptive loss minimization paradigm that simultaneously fits the data and controls the degree of model updating. We demonstrate on benchmark datasets that 25% less labeled samples suffice to guarantee similar, or even improved performance. Our results show strong evidence that for label-demanding scenarios, the proposed approach offers a practical guide on data collection and model training.

The recipe behind the success of deep learning has been the combination of neural networks and gradient-based optimization. Understanding the behavior of gradient descent however, and particularly its instability, has lagged behind its empirical success. To add to the theoretical tools available to study gradient descent we propose the principal flow (PF), a continuous time flow that approximates gradient descent dynamics. To our knowledge, the PF is the only continuous flow that captures the divergent and oscillatory behaviors of gradient descent, including escaping local minima and saddle points. Through its dependence on the eigendecomposition of the Hessian the PF sheds light on the recently observed edge of stability phenomena in deep learning. Using our new understanding of instability we propose a learning rate adaptation method which enables us to control the trade-off between training stability and test set evaluation performance.

Humans innately measure distance between instances in an unlabeled dataset using an unknown similarity function. Distance metrics can only serve as proxy for similarity in information retrieval of similar instances. Learning a good similarity function from human annotations improves the quality of retrievals. This work uses deep metric learning to learn these user-defined similarity functions from few annotations for a large football trajectory dataset. We adapt an entropy-based active learning method with recent work from triplet mining to collect easy-to-answer but still informative annotations from human participants and use them to train a deep convolutional network that generalizes to unseen samples. Our user study shows that our approach improves the quality of the information retrieval compared to a previous deep metric learning approach that relies on a Siamese network. Specifically, we shed light on the strengths and weaknesses of passive sampling heuristics and active learners alike by analyzing the participants' response efficacy. To this end, we collect accuracy, algorithmic time complexity, the participants' fatigue and time-to-response, qualitative self-assessment and statements, as well as the effects of mixed-expertise annotators and their consistency on model performance and transfer-learning.

The practice of applying several local updates before aggregation across clients has been empirically shown to be a successful approach to overcoming the communication bottleneck in Federated Learning (FL). Such methods are usually implemented by having clients perform one or more epochs of local training per round while randomly reshuffling their finite dataset in each epoch. Data imbalance, where clients have different numbers of local training samples, is ubiquitous in FL applications, resulting in different clients performing different numbers of local updates in each round. In this work, we propose a general recipe, FedShuffle, that better utilizes the local updates in FL, especially in this regime encompassing random reshuffling and heterogeneity. FedShuffle is the first local update method with theoretical convergence guarantees that incorporates random reshuffling, data imbalance, and client sampling — features that are essential in large-scale cross-device FL. We present a comprehensive theoretical analysis of FedShuffle and show, both theoretically and empirically, that it does not suffer from the objective function mismatch that is present in FL methods that assume homogeneous updates in heterogeneous FL setups, such as FedAvg (McMahan et al., 2017). In addition, by combining the ingredients above, FedShuffle improves upon FedNova (Wang et al., 2020), which was previously proposed to solve this mismatch. Similar to Mime (Karimireddy et al., 2020), we show that FedShuffle with momentum variance reduction (Cutkosky & Orabona, 2019) improves upon non-local methods under a Hessian similarity assumption.
Automated machine learning (AutoML) usually involves several crucial components, such as Data Augmentation (DA) policy, Hyper-Parameter Optimization (HPO), and Neural Architecture Search (NAS). Although many strategies have been developed for automating these components in separation, joint optimization of these components remains challenging due to the largely increased search dimension and the variant input types of each component. In parallel to this, the common practice of searching for the optimal architecture first and then retraining it before deployment in NAS often suffers from the low-performance correlation between the searching and retraining stages. An end-to-end solution that integrates the AutoML components and returns a ready-to-use model at the end of the search is desirable. In view of these, we propose DHA, which achieves joint optimization of Data augmentation policy, Hyper-parameter, and Architecture. Specifically, end-to-end NAS is achieved in a differentiable manner by optimizing a compressed lower-dimensional feature space, while DA policy and HPO are regarded as dynamic schedulers, which adapt themselves to the update of network parameters and network architecture at the same time. Experiments show that DHA achieves state-of-the-art (SOTA) results on various datasets and search spaces. To the best of our knowledge, we are the first to efficiently and jointly optimize DA policy, NAS, and HPO in an end-to-end manner without retraining.

Understanding generalization is crucial to confidently engineer and deploy machine learning models, especially when deployment implies a shift in the data domain. For such domain adaptation problems, we seek generalization bounds which are tractably computable and tight. If these desiderata can be reached, the bounds can serve as guarantees for adequate performance in deployment. However, in applications where deep neural networks are the models of choice, deriving results which fulfill these remains an unresolved challenge; most existing bounds are either vacuous or has non-estimable terms, even in favorable conditions. In this work, we evaluate existing bounds from the literature with potential to satisfy our desiderata on domain adaptation image classification tasks, where deep neural networks are preferred. We find that all bounds are vacuous and that sample generalization terms account for much of the observed looseness, especially when these terms interact with measures of domain shift. To overcome this and arrive at the tightest possible results, we combine each bound with recent data-dependent PAC-Bayes analysis, greatly improving the guarantees. We find that, when domain overlap can be assumed, a simple importance weighting extension of previous work provides the tightest estimable bound. Finally, we study which terms dominate the bounds and identify possible directions for further improvement.

In this paper, we study the scalability of model-based algorithms learning the optimal policy of a discounted \blue{rested} Markovian bandit problem with $n$ arms. There are two categories of model-based reinforcement learning algorithms: Bayesian algorithms (like PSRL), and optimistic algorithms (like UCRL2 or UCBVI). A naive application of these algorithms is not scalable because the state-space is exponential in $n$. In this paper, we construct variants of these algorithms specially tailored to Markovian bandits (MB) that we call MB-PSRL, MB-UCRL2, and MB-UCBVI. \blue{We consider an episodic setting with geometrically distributed episode length, and measure the performance of the algorithm in terms of regret (Bayesian regret for MB-PSRL and expected regret for MB-UCRL2 and MB-UCBVI)}. We prove that, for this setting, all algorithms have a low regret in $\tilde{O}(S\sqrt{nK})$ -- where $K$ is the number of episodes, $n$ is the number of arms and $S$ is the number of states of each arm. Up to a factor $\sqrt{S}$, these regrets match the \blue{Bayesian minimax regret} lower bound of $\Omega(\sqrt{SnK})$ that we also derive. Even if their theoretical regrets are comparable, the {\it time complexities} of these algorithms vary greatly: We show that MB-UCRL2, as well as all algorithms that use bonuses on transition matrices have a { time} complexity that grows exponentially in $n$. In contrast, MB-UCBVI does not use bonuses on transition matrices and we show that it can be implemented efficiently, with a time complexity linear in $n$. Our numerical experiments show, however, that its empirical regret is large. Our Bayesian algorithm, MB-PSRL, enjoys the best of both worlds: its running time is linear in the number of arms and its empirical regret is the smallest of all algorithms. This is a new addition in the understanding of the power of Bayesian algorithms, that can often be tailored to the structure of the problems to learn.
The challenge in the widely applicable online matching problem lies in making irrevocable assignments while there is uncertainty about future inputs. Most theoretically-grounded policies are myopic or greedy in nature. In real-world applications where the matching process is repeated on a regular basis, the underlying data distribution can be leveraged for better decision-making. We present an end-to-end Reinforcement Learning framework for deriving better matching policies based on trial-and-error on historical data. We devise a set of neural network architectures, design feature representations, and empirically evaluate them across two online matching problems: Edge-Weighted Online Bipartite Matching and Online Submodular Bipartite Matching. We show that most of the learning approaches perform consistently better than classical baseline algorithms on four synthetic and real-world datasets. On average, our proposed models improve the matching quality by 3-10% on a variety of synthetic and real-world datasets.

Generating videos is a complex task that is accomplished by generating a set of temporally coherent images frame-by-frame. This limits the expressivity of videos to only image-based operations on the individual video frames needing network designs to obtain temporally coherent trajectories in the underlying image space. We propose INR-V, a video representation network that learns a continuous space for video-based generative tasks. INR-V parameterizes videos using implicit neural representations (INRs), a multi-layered perceptron that predicts an RGB value for each input pixel location of the video. The INR is predicted using a meta-network which is a hypernetwork trained on neural representations of multiple video instances. Later, the meta-network can be sampled to generate diverse novel videos enabling many downstream video-based generative tasks. Interestingly, we find that conditional regularization and progressive weight initialization play a crucial role in obtaining INR-V. The representation space learned by INR-V is more expressive than an image space showcasing many interesting properties not possible with the existing works. For instance, INR-V can smoothly interpolate intermediate videos between known video instances (such as intermediate identities, expressions, and poses in face videos). It can also in-paint missing portions in videos to recover temporally coherent full videos. In this work, we evaluate the space learned by INR-V on diverse generative tasks such as video interpolation, novel video generation, video inversion, and video inpainting against the existing baselines. INR-V significantly outperforms the baselines on several of these demonstrated tasks, clearly showing the potential of the proposed representation space.
Molecular conformation generation aims to generate three-dimensional coordinates of all the atoms in a molecule and is an important task in bioinformatics and pharmacology. Previous methods usually first predict the interatomic distances, the gradients of interatomic distances or the local structures (e.g., torsion angles) of a molecule, and then reconstruct its 3D conformation. How to directly generate the conformation without the above intermediate values is not fully explored. In this work, we propose a method that directly predicts the coordinates of atoms: (1) the loss function is invariant to roto-translation of coordinates and permutation of symmetric atoms; (2) the newly proposed model adaptively aggregates the bond and atom information and iteratively refines the coordinates of the generated conformation. Our method achieves the best results on GEOM-QM9 and GEOM-Drugs datasets. Further analysis shows that our generated conformations have closer properties (e.g., HOMO-LUMO gap) with the groundtruth conformations. In addition, our method improves molecular docking by providing better initial conformations. All the results demonstrate the effectiveness of our method and the great potential of the direct approach. The code is released at \url{https://github.com/DirectMolecularConfGen/DMCG}.
Artificial neural networks (ANNs) are typically confined to accomplishing pre-defined tasks by learning a set of static parameters. In contrast, biological neural networks (BNNs) can adapt to various new tasks by continually updating the neural connections based on the inputs, which is aligned with the paradigm of learning effective learning rules in addition to static parameters, \textit{e.g.}, meta-learning. Among various biologically inspired learning rules, Hebbian plasticity updates the neural network weights using local signals without the guide of an explicit target function, thus enabling an agent to learn automatically without human efforts. However, typical plastic ANNs using a large amount of meta-parameters violate the nature of the genomics bottleneck and potentially deteriorate the generalization capacity. This work proposes a new learning paradigm decomposing those connection-dependent plasticity rules into neuron-dependent rules thus accommodating $\Theta(n^2)$ learnable parameters with only $\Theta(n)$ meta-parameters. We also thoroughly study the effect of different neural modulation on plasticity. Our algorithms are tested in challenging random 2D maze environments, where the agents have to use their past experiences to shape the neural connections and improve their performances for the future. The results of our experiment validate the following: 1. Plasticity can be adopted to continually update a randomly initialized RNN to surpass pre-trained, more sophisticated recurrent models, especially when coming to long-term memorization. 2. Following the genomics bottleneck, the proposed decomposed plasticity can be comparable to or even more effective than canonical plasticity rules in some instances.

Models of human driving behavior have long been used for prediction in autonomous vehicles, but recently have also started being used to create non-playable characters for driving simulations. While such models are in many respects realistic, they tend to suffer from unacceptably high rates of driving infractions, such as collisions or off-road driving, particularly when deployed in map locations with road geometries dissimilar to the training dataset. In this paper we present a novel method for fine-tuning a foundation model of human driving behavior to novel locations where human demonstrations are not available which reduces the incidence of such infractions. The method relies on inference in the foundation model to generate infraction-free trajectories as well as additional penalties applied when fine-tuning the amortized inference behavioral model. We demonstrate this "titration" technique using the ITRA foundation behavior model trained on the INTERACTION dataset when transferring to CARLA map locations. We demonstrate a 76-86% reduction in infraction rate and provide evidence that further gains are possible with more computation or better inference algorithms.

Following the success in advancing natural language processing and understanding, transformers are expected to bring revolutionary changes to computer vision. This work provides a comprehensive study on the robustness of vision transformers (ViTs) against adversarial perturbations. Tested on various white-box and transfer attack settings, we find that ViTs possess better adversarial robustness when compared with MLP-Mixer and convolutional neural networks (CNNs) including ConvNeXt, and this observation also holds for certified robustness. Through frequency analysis and feature visualization, we summarize the following main observations contributing to the improved robustness of ViTs: 1) Features learned by ViTs contain less high-frequency patterns that have spurious correlation, which helps explain why ViTs are less sensitive to high-frequency perturbations than CNNs and MLP-Mixer, and there is a high correlation between how much the model learns high-frequency features and its robustness against different frequency-based perturbations. 2) Introducing convolutional or tokens-to-token blocks for learning high-frequency features in ViTs can improve classification accuracy but at the cost of adversarial robustness. 3) Modern CNN designs that borrow techniques from ViTs including activation function, layer norm, larger kernel size to imitate the global attention, and patchify the images as inputs, etc., could help bridge the performance gap between ViTs and CNNs not only in terms of performance, but also certified and empirical adversarial robustness. Moreover, we show adversarial training is also applicable to ViT for training robust models, and sharpness-aware minimization can also help improve robustness, while pre-training with clean images on larger datasets does not significantly improve adversarial robustness.

Fairness-aware learning aims at constructing classifiers that not only make accurate predictions, but also do not discriminate against specific groups. It is a fast-growing area of machine learning with far-reaching societal impact. However, existing fair learning methods are vulnerable to accidental or malicious artifacts in the training data, which can cause them to unknowingly produce unfair classifiers. In this work we address the problem of fair learning from unreliable training data in the robust multisource setting, where the available training data comes from multiple sources, a fraction of which might not be representative of the true data distribution. We introduce FLEA, a filtering-based algorithm that identifies and suppresses those data sources that would have a negative impact on fairness or accuracy if they were used for training. As such, FLEA is not a replacement of prior fairness-aware learning methods but rather an augmentation that makes any of them robust against unreliable training data. We show the effectiveness of our approach by a diverse range of experiments on multiple datasets. Additionally, we prove formally that –given enough data– FLEA protects the learner against corruptions as long as the fraction of affected data sources is less than half. Our source code and documentation are available at https://github.com/ISTAustria-CVML/FLEA.

Learning from structured data is a core machine learning task. Commonly, such data is represented as graphs, which normally only consider (typed) binary relationships between pairs of nodes. This is a substantial limitation for many domains with highly-structured data. One important such domain is source code, where hypergraph-based representations can better capture the semantically rich and structured nature of code. In this work, we present HEAT, a neural model capable of representing typed and qualified hypergraphs, where each hyperedge explicitly qualifies how participating nodes contribute. It can be viewed as a generalization of both message passing neural networks and Transformers. We evaluate HEAT on knowledge base completion and on bug detection and repair using a novel hypergraph representation of programs. In both settings, it outperforms strong baselines, indicating its power and generality.
With the motive of training all the parameters of a neural network, we study why and when one can achieve this by iteratively creating, training, and combining randomly selected subnetworks. Such scenarios have either implicitly or explicitly emerged in the recent literature: see e.g., the Dropout family of regularization techniques, or some distributed ML training protocols that reduce communication/computation complexities, such as the Independent Subnet Training protocol. While these methods are studied empirically and utilized in practice, they often enjoy partial or no theoretical support, especially when applied on neural network-based objectives. In this manuscript, our focus is on overparameterized single hidden layer neural networks with ReLU activations in the lazy training regime. By carefully analyzing $i)$ the subnetworks' neural tangent kernel, $ii)$ the surrogate functions' gradient, and $iii)$ how we sample and combine the surrogate functions, we prove linear convergence rate of the training error --up to a neighborhood around the optimal point-- for an overparameterized single-hidden layer perceptron with a regression loss. Our analysis reveals a dependency of the size of the neighborhood around the optimal point on the number of surrogate models and the number of local training steps for each selected subnetwork. Moreover, the considered framework generalizes and provides new insights on dropout training, multi-sample dropout training, as well as Independent Subnet Training; for each case, we provide convergence results as corollaries of our main theorem.
Deep learning with noisy labels is a challenging task, which has received much attention from the machine learning and computer vision communities. Recent prominent methods that build on a specific sample selection (SS) strategy and a specific semi-supervised learning (SSL) model achieved state-of-the-art performance. Intuitively, better performance could be achieved if stronger SS strategies and SSL models are employed. Following this intuition, one might easily derive various effective noisy-label learning methods using different combinations of SS strategies and SSL models, which is, however, simply reinventing the wheel in essence. To prevent this problem, we propose SemiNLL, a versatile framework that investigates how to naturally combine different SS and SSL components based on their effects and efficiencies. We conduct a systematic and detailed analysis of the combinations of possible components based on our framework. Our framework can absorb various SS strategies and SSL backbones, utilizing their power to achieve promising performance. The instantiations of our framework demonstrate substantial improvements over state-of-the-art methods on benchmark-simulated and real-world datasets with noisy labels.

Deep neural network based object detectors are continuously evolving and are used in a multitude of applications, each having its own set of requirements. While safety-critical applications need high accuracy and reliability, low-latency tasks need resource and energy-efficient networks. Real-time detection networks, which are a necessity in high-impact real-world applications, are continuously proposed but they overemphasize the improvements in accuracy and speed while other capabilities such as versatility, robustness, resource, and energy efficiency are omitted. A reference benchmark for existing networks does not exist nor does a standard evaluation guideline for designing new networks, which results in ambiguous and inconsistent comparisons. We, therefore, conduct a comprehensive study on multiple real-time detection networks (anchor-based, keypoint-based, and transformer-based) on a wide range of datasets and report results on an extensive set of metrics. We also study the impact of variables such as image size, anchor dimensions, confidence thresholds, and architecture layers on the overall performance. We analyze the robustness of detection networks against distribution shift, natural corruptions, and adversarial attacks. Also, we provide the calibration analysis to gauge the reliability of the predictions. Finally, to highlight the real-world impact, we conduct two unique case studies, on autonomous driving and healthcare application. To further gauge the capability of networks in critical real-time applications, we report the performance after deploying the detection networks on edge devices. Our extensive empirical study can act as a guideline for the industrial community to make an informed choice on the existing networks. We also hope to inspire the research community towards a new direction of design and evaluation of networks that focuses on the bigger and holistic overview for a far-reaching impact.

Likelihood-based, or explicit, deep generative models use neural networks to construct flexible high-dimensional densities. This formulation directly contradicts the manifold hypothesis, which states that observed data lies on a low-dimensional manifold embedded in high-dimensional ambient space. In this paper we investigate the pathologies of maximum-likelihood training in the presence of this dimensionality mismatch. We formally prove that degenerate optima are achieved wherein the manifold itself is learned but not the distribution on it, a phenomenon we call manifold overfitting. We propose a class of two-step procedures consisting of a dimensionality reduction step followed by maximum-likelihood density estimation, and prove that they recover the data-generating distribution in the nonparametric regime, thus avoiding manifold overfitting. We also show that these procedures enable density estimation on the manifolds learned by implicit models, such as generative adversarial networks, hence addressing a major shortcoming of these models. Several recently proposed methods are instances of our two-step procedures; we thus unify, extend, and theoretically justify a large class of models.

It is well understood that client-master communication can be a primary bottleneck in federated learning (FL). In this work, we address this issue with a novel client subsampling scheme, where we restrict the number of clients allowed to communicate their updates back to the master node. In each communication round, all participating clients compute their updates, but only the ones with "important" updates communicate back to the master. We show that importance can be measured using only the norm of the update and give a formula for optimal client participation. This formula minimizes the distance between the full update, where all clients participate, and our limited update, where the number of participating clients is restricted. In addition, we provide a simple algorithm that approximates the optimal formula for client participation, which allows for secure aggregation and stateless clients, and thus does not compromise client privacy. We show both theoretically and empirically that for Distributed SGD (DSGD) and Federated Averaging (FedAvg), the performance of our approach can be close to full participation and superior to the baseline where participating clients are sampled uniformly. Moreover, our approach is orthogonal to and compatible with existing methods for reducing communication overhead, such as local methods and communication compression methods.

We consider the private ranking recovery problem, where a data collector seeks to estimate the permutation/ranking of a data vector given a randomized (privatized) version of it. We aim to establish fundamental trade-offs between the performance of the estimation task, measured in terms of probability of error, and the level of privacy that can be guaranteed when the noise mechanism consists of adding artificial noise. Towards this end, we show the optimality of a low-complexity decision rule (referred to as linear decoder) for the estimation task, under several noise distributions widely used in the privacy literature (e.g., Gaussian, Laplace, and generalized normal model). We derive the Taylor series of the probability of error, which yields its first and second-order approximations when such a linear decoder is employed. We quantify the guaranteed level of privacy using differential privacy (DP) types of metrics, such as $\epsilon$-DP and $(\alpha,\epsilon)$-Rényi DP. Finally, we put together the results to characterize trade-offs between privacy and probability of error.

The recent works proposing transformer-based models for graphs have proven the inadequacy of Vanilla Transformer for graph representation learning. To understand this inadequacy, there is a need to investigate if spectral analysis of the transformer will reveal insights into its expressive power. Similar studies already established that spectral analysis of Graph neural networks (GNNs) provides extra perspectives on their expressiveness. In this work, we systematically study and establish the link between the spatial and spectral domain in the realm of the transformer. We further provide a theoretical analysis that the spatial attention mechanism in the transformer cannot effectively capture the desired frequency response, thus, inherently limiting its expressiveness in spectral space. Therefore, we propose FeTA, a framework that aims to perform attention over the entire graph spectrum (i.e. actual frequency components of the graph) analogous to the attention in spatial space. Empirical results suggest that FeTA provides homogeneous performance gain against vanilla transformer across all tasks on standard benchmarks and can easily be extended to GNN-based models with low-pass characteristics (e.g., GAT).
Zero-shot learning relies on semantic class representations such as hand-engineered attributes or learned embeddings to predict classes without any labeled examples. We propose to learn class representations by embedding nodes from common sense knowledge graphs in a vector space. Common sense knowledge graphs are an untapped source of explicit high-level knowledge that requires little human effort to apply to a range of tasks. To capture the knowledge in the graph, we introduce ZSL-KG, a general-purpose framework with a novel transformer graph convolutional network (TrGCN) for generating class representations. Our proposed TrGCN architecture computes non-linear combinations of node neighbourhoods. Our results show that ZSL-KG improves over existing WordNet-based methods on five out of six zero-shot benchmark datasets in language and vision.
Bayesian inference in non-linear dynamical systems seeks to find good posterior approximations of a latent state given a sequence of observations. Gaussian filters and smoothers, including the (extended/unscented) Kalman filter/smoother, which are commonly used in engineering applications, yield Gaussian posteriors on the latent state. While they are computationally efficient, they are often criticised for their crude approximation of the posterior state distribution. In this paper, we address this criticism by proposing a message passing scheme for iterative state estimation in non-linear dynamical systems, which yields more informative (Gaussian) posteriors on the latent states. Our message passing scheme is based on expectation propagation (EP). We prove that classical Rauch--Tung--Striebel (RTS) smoothers, such as the extended Kalman smoother (EKS) or the unscented Kalman smoother (UKS), are special cases of our message passing scheme. Running the message passing scheme more than once can lead to significant improvements of the classical RTS smoothers, so that more informative state estimates can be obtained. We address potential convergence issues of EP by generalising our state estimation framework to damped updates and the consideration of general $\alpha$-divergences.

We present NeSF, a method for producing 3D semantic fields from posed RGB images alone. In place of classical 3D representations, our method builds on recent work in neural fields wherein 3D structure is captured by point-wise functions. We leverage this methodology to recover 3D density fields upon which we then train a 3D semantic segmentation model supervised by posed 2D semantic maps. Despite being trained on 2D signals alone, our method is able to generate 3D-consistent semantic maps from novel camera poses and can be queried at arbitrary 3D points. Notably, NeSF is compatible with any method producing a density field. Our empirical analysis demonstrates comparable quality to competitive 2D and 3D semantic segmentation baselines on complex, realistically-rendered scenes and significantly outperforms a comparable neural radiance field-based method on a series of tasks requiring 3D reasoning. Our method is the first to learn semantics by recognizing patterns in the geometry stored within a 3D neural field representation. NeSF is trained using purely 2D signals and requires as few as one labeled image per-scene at train time. No semantic input is required for inference on novel scenes.

The finite-time convergence of off-policy temporal difference (TD) learning has been comprehensively studied recently. However, such a type of convergence has not been established for off-policy TD learning in the multi-agent setting, which covers broader reinforcement learning applications and is fundamentally more challenging. This work develops a decentralized TD with correction (TDC) algorithm for multi-agent off-policy TD learning under Markovian sampling. In particular, our algorithm avoids sharing the actions, policies and rewards of the agents, and adopts mini-batch sampling to reduce the sampling variance and communication frequency. Under Markovian sampling and linear function approximation, we proved that the finite-time sample complexity of our algorithm for achieving an $\epsilon$-accurate solution is in the order of $\mathcal{O}\big(\frac{M\ln\epsilon^{-1}}{\epsilon(1-\sigma_2)^2}\big)$, where $M$ denotes the total number of agents and $\sigma_2$ is a network parameter. This matches the sample complexity of the centralized TDC. Moreover, our algorithm achieves the optimal communication complexity $\mathcal{O}\big(\frac{\sqrt{M}\ln\epsilon^{-1}}{1-\sigma_2}\big)$ for synchronizing the value function parameters, which is order-wise lower than the communication complexity of the existing decentralized TD(0). Numerical simulations corroborate our theoretical findings.